


Context is King: Long Live Graph-Based Reasoning
Just over a year ago, we examined an emerging set of techniques known as GraphRAG. The concept was to enhance retrieval-augmented generation by integrating knowledge graphs, using their structured nature to provide richer, more nuanced context than standard vector search could offer. In that initial analysis, we detailed several architectural blueprints for harnessing these graphs to capture the complex relationships between entities, with the goal of producing more accurate and contextually aware AI-generated responses.
Since then, I have been watching for signs of these techniques taking root in practice. Frankly, evidence of widespread adoption is scarce. This fits a classic pattern of technological adoption I’ve seen play out many times from my role as a conference program chair: a subject ignites a flurry of interest, but twelve months on, the initial fervor has subsided. The discussion around GraphRAG now seems confined mostly to graph technology vendors and the specialist graph community, with little mention from mainstream AI engineering teams or developers.
My observations are not unique. When I ask friends if they are hearing about enterprise demand for GraphRAG, the response from those outside the dedicated graph world is consistently muted. This aligns with the view of experts like Douwe Kiela, who notes the effectiveness of the marketing behind the concept—"whoever is doing the marketing behind this is very good at their job"—while remaining skeptical of the execution. He suggests that most current implementations are not truly graph-based, but rather a form of "data augmentation" that simply adds "more chunks to a standard vector database." The initial excitement, it seems, has not yet translated into meaningful engineering traction.
Graph-Thinking in Practice: Signs of Life
But anecdotal reports and expert skepticism may not capture the full picture. A review of recent job postings reveals a small cohort of companies building systems that rely on the core principles of GraphRAG, even if they avoid the label. In healthcare, firms are creating "patient-provider-payer relationship graphs" to optimize medical billing. In advertising, they are engineering vast "identity graphs" that connect user activity across devices. Productivity platforms are also getting in on the act, building assistants that retrieve context by understanding the links between emails, calendar events, and meeting transcripts—a clear application of graph-based thinking.
A year later, GraphRAG chatter is louder than its footprint in production.
Perhaps the most forward-looking applications are emerging in the field of agentic AI. Some teams are architecting multi-agent systems to automate complex enterprise workflows, such as orchestrating a cloud migration by deploying specialized agents that plan, execute, and validate tasks. Others are building sophisticated assistants for industries like real estate, where agents must fuse visual data from property photos with market trends and user queries, navigating a complex web of interconnected information. In these systems, the graph is evolving from a simple data source for retrieval into a foundational map for reasoning and coordination.
A Blueprint for Agentic Reasoning
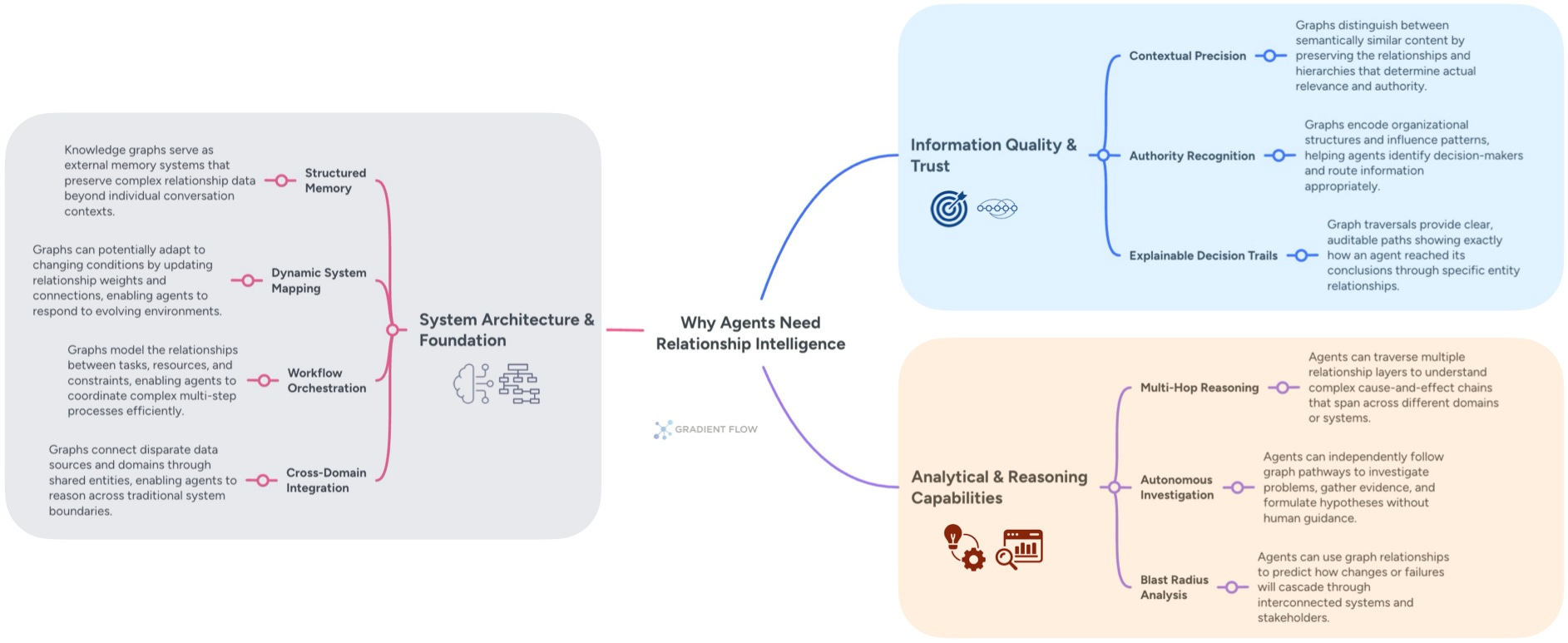
The true value of this graph-centric approach becomes clear when applied to agentic AI. Consider an agent tasked with diagnosing a production failure. A system reliant on semantic search might surface a dozen documents mentioning "database latency," but it cannot distinguish a critical failure in the primary authentication service from a minor lag in a secondary reporting tool. A knowledge graph, by contrast, provides a map of the system's dependencies. The agent can traverse this map, methodically tracing the cascade of failures from the user-facing app back to its root cause, much as a human engineer would.
This represents a shift from searching for similarity to reasoning over relationships. An agent managing client communications, for example, needs to know not just that a concern was raised, but who raised it. A graph preserves this crucial context, modeling organizational hierarchies and communication patterns as first-class citizens. This allows an agent to move beyond simple keyword retrieval to answer sophisticated queries like, “Which stakeholders with budget authority have expressed doubts about this project?”—a level of precision that vector search alone cannot provide.
{kind=link}
Ultimately, this structured understanding is what enables proactive, autonomous action. An agent overseeing a global supply chain can use a graph to see that a shipping delay in one port will affect a specific parts supplier, which in turn will disrupt a manufacturing line on another continent. This multi-hop reasoning allows the agent to act: rerouting shipments, alerting partners, and adjusting production schedules based on a holistic view of the system. The graph becomes both the agent’s long-term memory and its framework for reasoning, a critical foundation for any truly autonomous system.
Closing the Implementation Gap with Kùzu
At this point, I may seem to be arguing from both sides: that GraphRAG has seen limited adoption, yet graphs are essential for the future of agentic AI. This apparent contradiction highlights the gap between a compelling vision and the practical difficulty of implementation. The persistent obstacle remains what it has always been: knowledge graph construction and maintenance is a complex, resource-intensive task that demands deep domain expertise and ongoing curation.
This is where recent work from the team behind the Kùzu graph database becomes particularly relevant. They have been publishing detailed, practical guides that address this implementation gap directly. Their work demonstrates how to build more resilient systems—for instance, an agentic router that intelligently combines the precision of Cypher queries with the flexibility of vector search to overcome the brittleness of traditional Text2Cypher. By leveraging popular open-source tools like BAML and DSPy, they show how to create and enrich graphs in a programmatic, repeatable fashion.
This practical approach is enabled by the design of Kùzu itself. As an embedded graph database, it runs within an application's process, eliminating network latency and the operational burden of a separate server. Its combination of a vectorized query engine, native Cypher support, and built-in vector indexing makes it a pragmatic choice for developers. With a permissive MIT license and a simple pip install setup, Kùzu is the kind of tool that lowers the barrier to entry, making powerful graph-based reasoning accessible without requiring teams to become specialized infrastructure experts.

From Retrieval to Relational Reasoning
So, while the "GraphRAG" label may not be headlining conference agendas this year, I think that its core ideas are far from dormant. The principle of reasoning over structured, connected data has a more potent calling. It is poised to become an architectural backbone for the next wave of agentic AI systems—the kind that must navigate complex, real-world dependencies. For engineering teams looking to build applications that do more than just retrieve facts, this is the key takeaway: the shift from simply finding similar text to understanding relationships is what separates a basic chatbot from an autonomous system that can actually reason.
Kùzu makes graph reasoning a pip-install away instead of a six-month infrastructure project.
This evolution is part of a much larger, more significant trend. The most pressing challenge in AI development is no longer about crafting the perfect prompt but about mastering what some call "context engineering." As I've argued previously, the bottleneck for creating reliable, sophisticated AI is the system that feeds it information. Graph-based reasoning is arguably the most advanced form of this discipline, providing not just a collection of facts but an interconnected map for an agent to navigate. Ultimately, the future of capable AI will be defined by the deliberate, thoughtful information architecture we build around it.
Quick Takes
Evangelos Simoudis and I discuss the following topics:
The Great AI “Hollowing Out” – When Entry-Level Jobs Disappear
The Hidden Hardware Crisis – When AI Assets Depreciate Faster Than Balance Sheets
The Router Revolution – How Model Access Is Being Transformed
Ben Lorica edits the Gradient Flow newsletter and hosts the Data Exchange podcast. He helps organize the AI Conference, the AI Agent Conference, the Applied AI Summit, while also serving as the Strategic Content Chair for AI at the Linux Foundation. (He is an investor in Kùzu Inc.) You can follow him on Linkedin, X, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.