

GraphRAG: Design Patterns, Challenges, Recommendations

Enhancing RAG with Knowledge Graphs: Blueprints, Hurdles, and Guidelines
By Ben Lorica and Prashanth Rao.
GraphRAG (Graph-based Retrieval Augmented Generation) enhances the traditional Retrieval Augmented Generation (RAG) method by integrating knowledge graphs (KGs) or graph databases with large language models (LLMs). It leverages the structured nature of graph databases to organize data as nodes and relationships, enabling more efficient and accurate retrieval of relevant information to provide better context to LLMs for generating responses.
By incorporating knowledge graphs as a source of structured, domain-specific context or factual information, GraphRAG enables LLMs to provide more precise, contextually aware, and relevant answers to questions, especially for complex queries that require a holistic understanding of summarized semantic concepts over large data collections or even single large documents.
While conventional vector search methods focus on unstructured data using high-dimensional vectors, GraphRAG leverages knowledge graphs to enable a more nuanced understanding and retrieval of interconnected, heterogeneous information. This structured approach enhances the context and depth of the retrieved information, resulting in more accurate and relevant responses to user queries, especially for complex or domain-specific topics.
Myriad of GraphRAG Architectures
While GraphRAG offers advantages over traditional RAG by utilizing the structured nature of knowledge graphs, its implementation presents unique challenges. The lack of a standardized approach for integrating knowledge graphs into the RAG pipeline creates a variety of implementations, each with its own strengths and considerations. Additionally, the requirement of a pre-existing knowledge graph adds another layer of complexity. Here are a few common GraphRAG architectures:
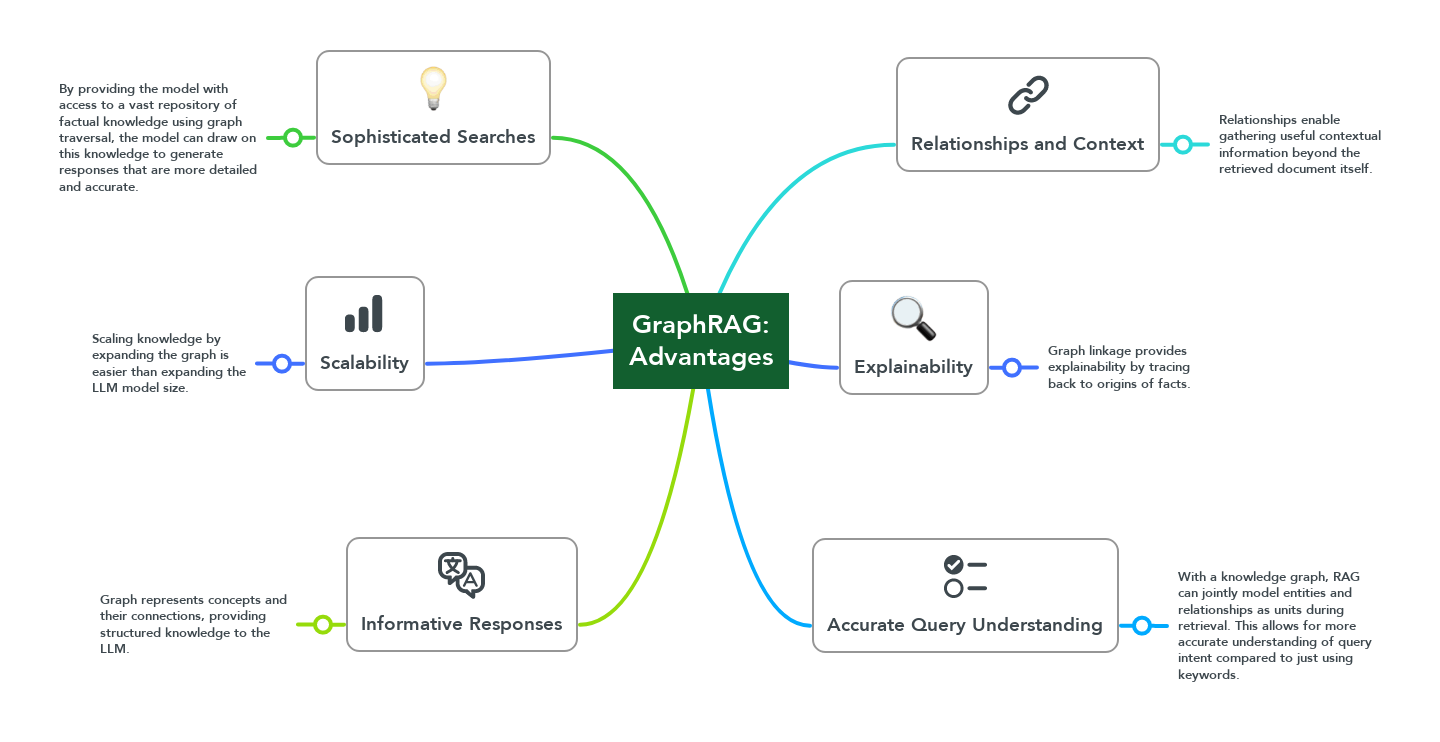
Knowledge Graph with Semantic Clustering
The graph provides a structured representation of data and enables reasoning on the whole dataset. The pipeline begins with a user submitting a query, followed by the system using the knowledge graph and graph machine learning to fetch relevant information. The retrieved information is then organized into semantic clusters through graph-based clustering. This clustered information enriches the data within the LLM's context window, allowing the LLM to generate an answer using this enriched context. The final answer includes references to the knowledge graph, making it suitable for data analysis, knowledge discovery, and research applications.
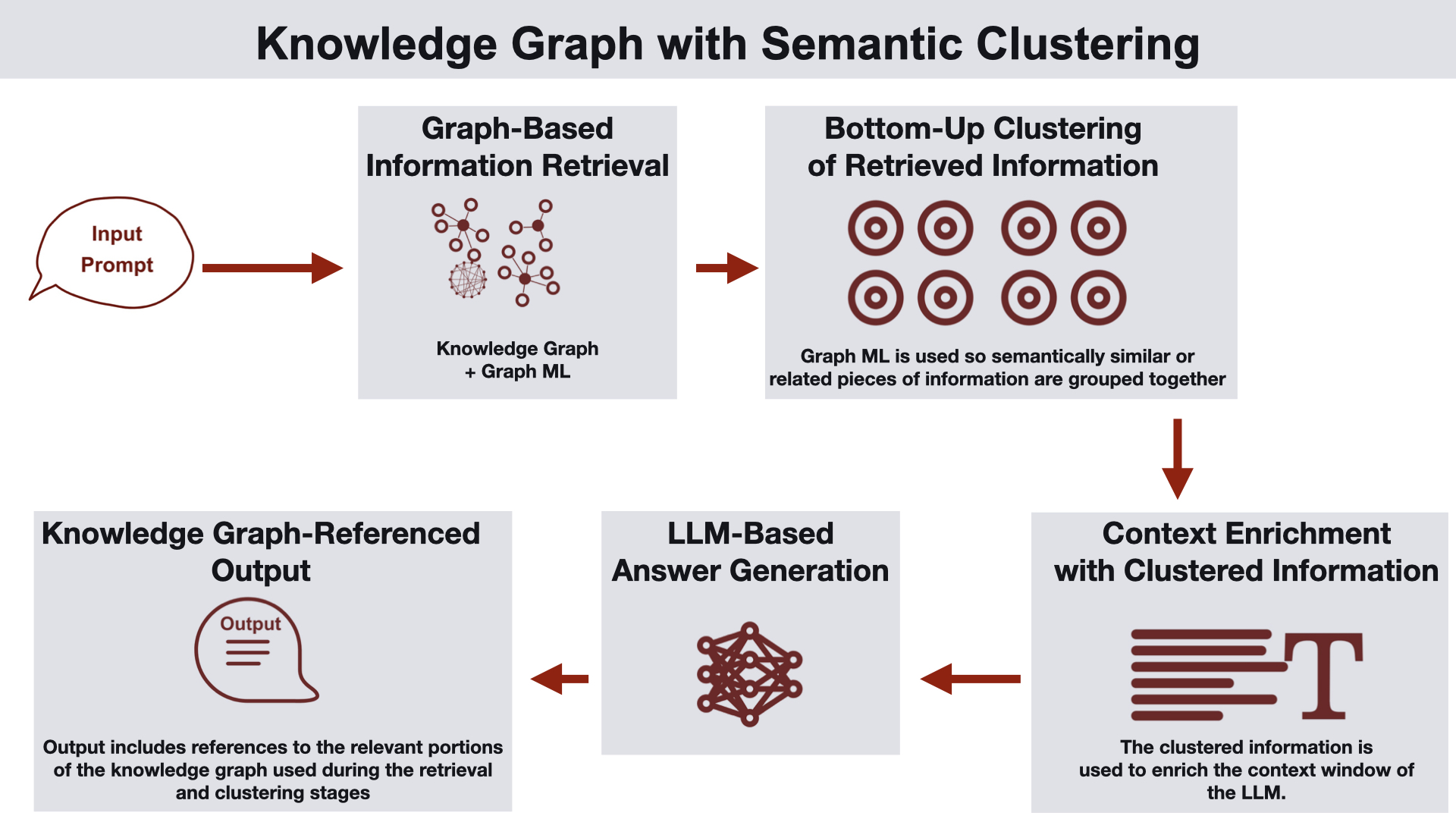
Knowledge Graph and Vector Database Integration
This approach leverages both a knowledge graph and a vector database to gather relevant information. The knowledge graph is constructed in a way that captures the relationships between chunks of vectors, including document hierarchies. The knowledge graph provides structured entity information in the neighborhood of the retrieved chunks from the vector search, enriching the prompt with valuable additional context. This enriched prompt is fed into the LLM for processing, and the LLM generates a response. Finally, the generated answer is returned to the user. This architecture is suitable for use cases such as customer support, semantic search, and personalized recommendations.
Knowledge Graph-Enhanced Question Answering Pipeline
In this architecture, the knowledge graph is used downstream of vector retrieval to enhance the response with additional facts. The pipeline begins with the user providing a query, followed by the calculation of the query embedding. A vector similarity search is then conducted on the vector index to identify relevant entities from the knowledge graph. The system retrieves the relevant nodes and properties from the graph database and (if found) executes Cypher queries to retrieve additional information on these entities. The retrieved information is aggregated to form a comprehensive context, which is passed to the LLM for generating a response. This approach is beneficial in healthcare or legal settings, where a standard response is always included along with the answer, based on the entities in the response.

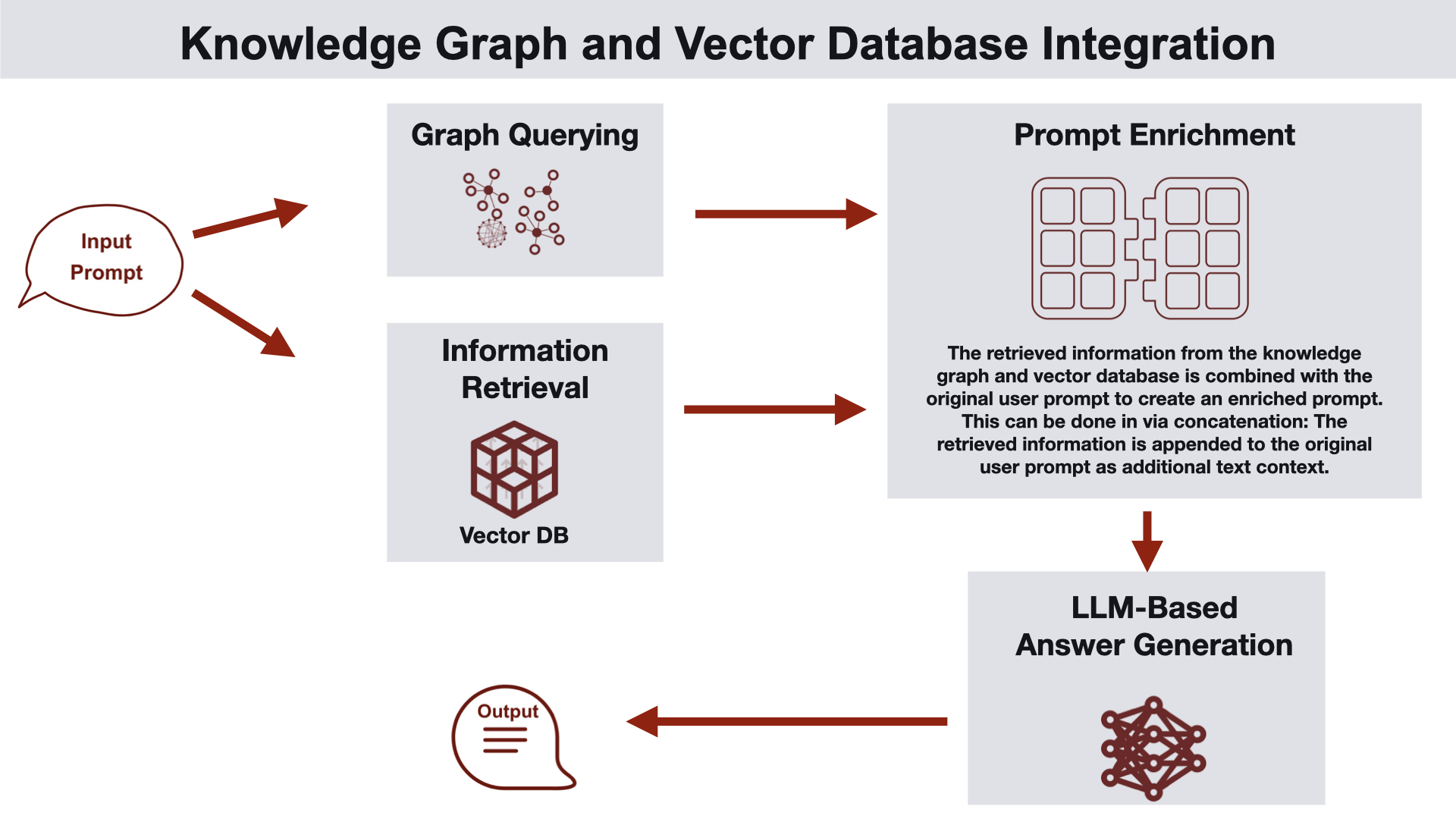
Graph-Enhanced Hybrid Retrieval
This GraphRAG architecture employs a hybrid approach that combines vector search, keyword search, and graph-specific queries for efficient and accurate retrieval of relevant information. Note that the term “hybrid” here is not the commonly used definition of combining vector and keyword-based retrieval - it also includes a knowledge graph retrieval step. The pipeline starts with a user submitting a query, followed by the hybrid retrieval process that integrates results from unstructured data searches and graph data searches. The retrieval from the vector and keyword index can be initially enhanced via reranking or rank fusion techniques. The results from all three forms of search are combined to create the context for an LLM, whose generated response is delivered to the user. This architecture is suitable for use cases such as enterprise search, document retrieval, and knowledge discovery.
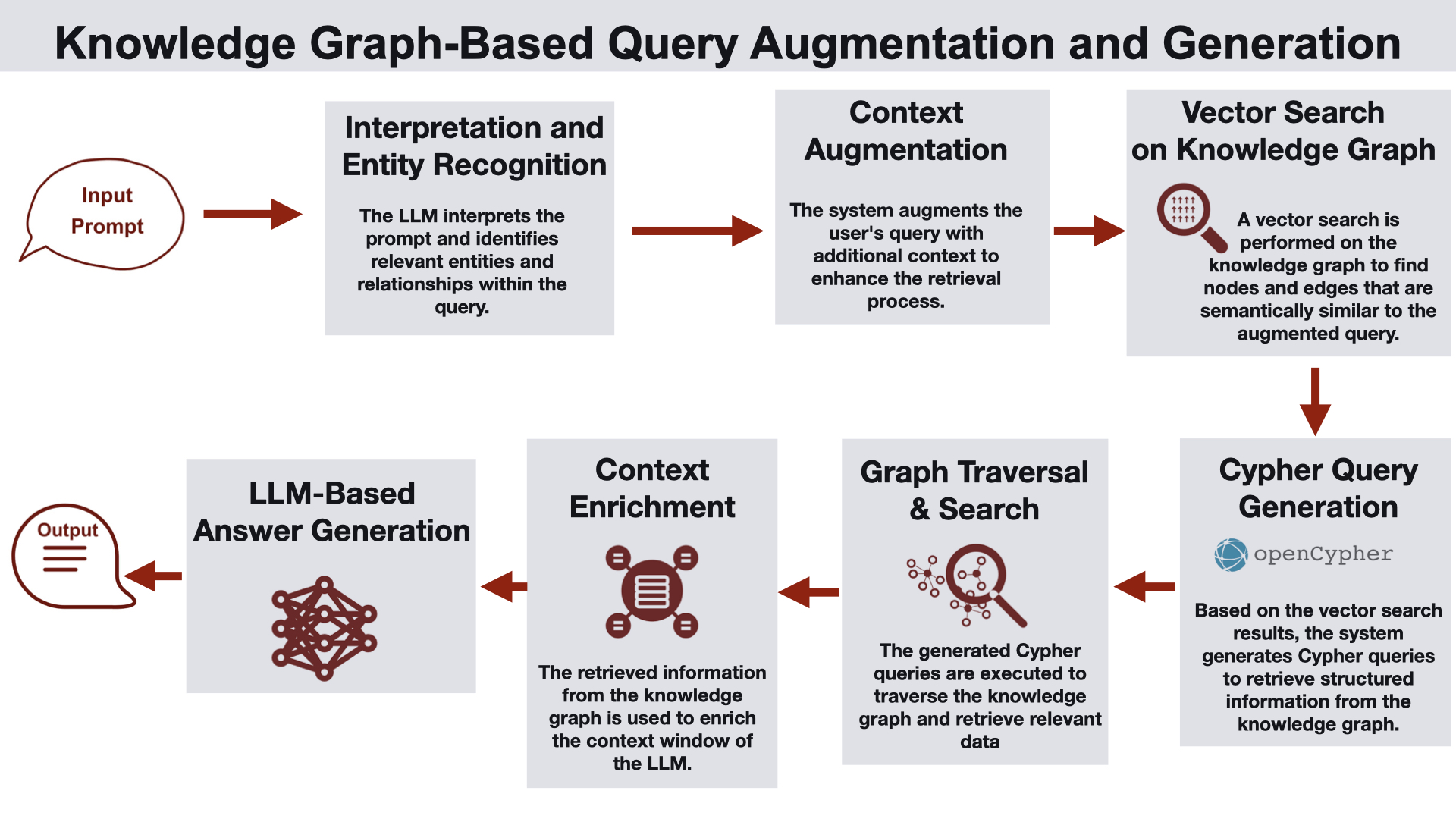
Knowledge Graph-Based Query Augmentation and Generation
This architecture leverages a knowledge graph prior to performing vector search, to traverse and retrieve relevant nodes and edges, enriching the context window of the LLM. The first stage is query augmentation, where the user's query is processed by the LLM to extract key entities and relationships. A vector search is performed on the node properties within the knowledge graph, to narrow down on the relevant nodes of interest. The next step is query rewriting, in which Cypher queries are generated on the retrieved subgraph to further narrow down on relevant structured information from the graph. The retrieved data from the graph traversal is used to enrich the LLM's context window. Finally, the LLM generates a response based on the enriched context. This architecture is suitable for product lookups or financial report generation where the relationships between entities are important.
Key Challenges
Building a comprehensive and accurate knowledge graph requires deep domain understanding and expertise in graph modeling, which is complex and resource-intensive. Automating this process with LLMs is still in its early stages and can be difficult and/or error-prone. Ensuring the quality, relevance, and completeness of the data is crucial. Maintaining an up-to-date knowledge graph demands expert knowledge, resources, and constant adaptation to evolving data. Integrating data from multiple sources with different schemas and quality levels adds to the complexity and time required for this task.
As we noted in a previous post, RAG itself requires computationally demanding experiments to identify optimal information extraction, chunking, embedding, retrieval and ranking strategies. Computationally intensive experiments to explore different GraphRAG architectures, settings, and parameters also demand significant resources. Leveraging a distributed computing framework like Ray for data processing and embedding computation, coupled with a performant and easy-to-integrate graph database such as Kuzu, facilitates large-scale experimentation and system optimization.
The Future of GraphRAG: Insights and Recommendations
We think that GraphRAG is here to stay, and has emerged as a natural extension of RAG. Using knowledge graphs provides another way to obtain structured information that can enhance the prompts used by the LLM at the generation stage. Here are some recommendations in getting started with implementing GraphRAG in your organization:
First, become familiar with “naive” RAG (vector retrieval with chunking). Also become proficient at running experiments and develop an evaluation strategy (what is considered a “good” result in your domain?).
Work on obtaining the data sources for a knowledge graph, which could be existing structured data, or unstructured text that can be transformed into a knowledge graph.
Become familiar with graph databases, how to ingest data into them, and how to query them (Kuzu is an easy-to-setup option).
Start with a small knowledge graph and experiment with passing query results from the graph as context to an LLM, and compare its performance to your naive RAG setup.
Don’t optimize your knowledge graph too early. First, settle on a GraphRAG architecture you can implement. You can begin improving your KG and data model once you have your entire GraphRAG setup and evaluation pipelines in place.
Run your GraphRAG pipeline end-to-end and convince yourself that the results are indeed better than the vector-only or graph-only approaches.
Don’t aim to build the perfect GraphRAG application right away. Starting off with a simpler design helps you better quantify the retrieval outcomes relative to a baseline, and you can build up from there by adding more elaborate routers and agents.
As your GraphRAG initiative evolves and your requirements grow, you may find yourself needing more complex architectures that can handle larger volumes of data. To ensure a smooth transition, it's wise to choose tools that can scale alongside your project. Tools should be flexible and cost-effective to accommodate enhancements to your GraphRAG setup and design, allowing you to adapt and optimize your system as your needs change.

These are early days for GraphRAG, and a lot of teams building these systems are still in the exploratory phase. We barely know of any examples of production deployments that are offering real business value. To get there, we’ll need more benchmark datasets and evaluation methodologies that are designed specifically for GraphRAG to help teams better gauge performance. Benchmark datasets like FinanceBench, designed for open-book question answering, offer a promising means of studying a GraphRAG system’s ability to reduce hallucinations and improve factual accuracy in generated responses.

Data Exchange Podcast
Unleashing the Power of AI Agents. Joao Moura, founder of crewAI, discusses the potential of AI agents to revolutionize automation, their architectures, modalities, and the process of building and implementing them using platforms like crewAI, while also exploring the associated risks, challenges, and future directions of the technology.
Machine Unlearning: Techniques, Challenges, and Future Directions. Ken Liu, a Stanford Computer Science Ph.D. student, discusses the concept, approaches, challenges, and future implications of machine unlearning, a process of removing specific data points from trained AI models.

Recent Articles
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Twitter, Reddit, or Mastodon. This newsletter is produced by Gradient Flow.
We (Tilores) have used our entity resolution engine in a similar way for RAG, in an insurance company use case. I guess it would be the Graph-Enhanced Hybrid Retrieval or Knowledge Graph-Based Query Augmentation and Generation approach as you describe. In that case, the LLM is using our entity resolution engine as a fuzzy keyword search to find a customer profile, and what insurance policies they have, and then the vector database is returning information about the insurance policy.
We have proposed the term "EntityRAG" for this, but maybe in the end we just get lumped in with Graph databases as GraphRAG. tbc.
You can see a video about it with Kern.ai here: https://youtu.be/QUdIpXUxaAc