

Building LLM-powered Apps: What You Need to Know

Building LLM-powered Applications
The past few weeks have been exciting for developers interested in deploying AI-powered applications. The field is evolving quickly, and it is now possible to build AI-powered applications without having to spend months or years learning the ins and outs of machine learning. This opens up a whole new world of possibilities, as developers can now experiment with AI in ways that were never before possible.
Foundation models, particularly large language models (LLMs), are now accessible to developers with minimal or no background in machine learning or data science. These agile teams, skilled in rapid iteration, can swiftly develop, test, and refine innovative applications showcased on platforms like Product Hunt. Significantly, this cohort of developers operates at a much quicker pace compared to the majority of Data and AI teams.
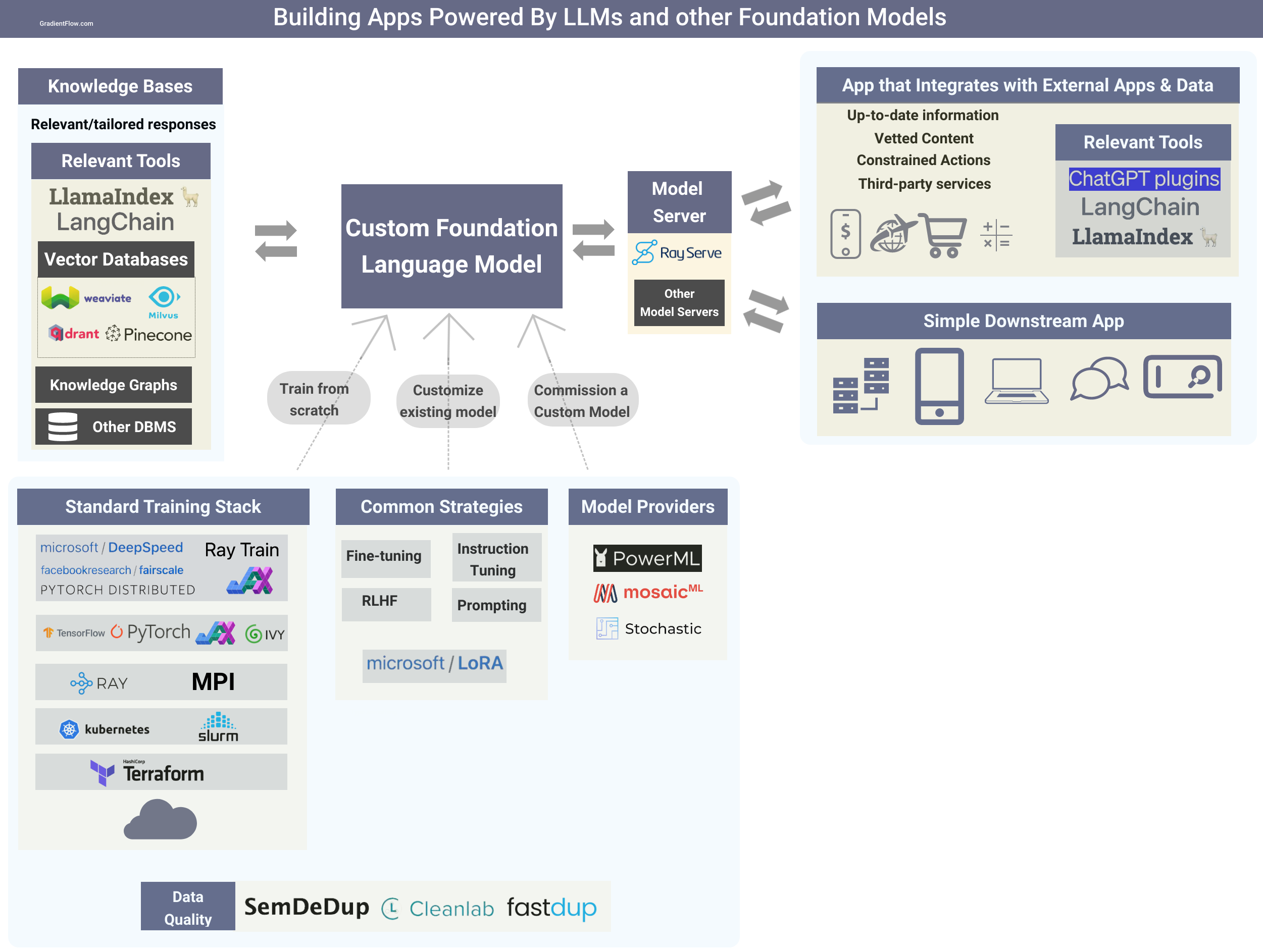
Custom Models
The current prevailing approach for developers is to use proprietary LLMs through APIs. But as we explained in a recent post, factors such as domain specificity, security, privacy, regulations, IP protection and control, will prompt more organizations to opt to invest in their own custom LLMs. As an example, Bloomberg recently detailed how they built BloombergGPT, an LLM for finance. In addition, several examples of finely-tuned, medium-sized models have captured the attention of both researchers and developers, paving the way for more of them to create their own custom LLMs.
Commission a custom model: There are new startups that provide the necessary resources and expertise to help companies fine-tune or even train their own large language models. For example, PowerML enables organizations to surpass the performance of general-purpose LLMs by leveraging RLHF and fine-tuning techniques on their own data.
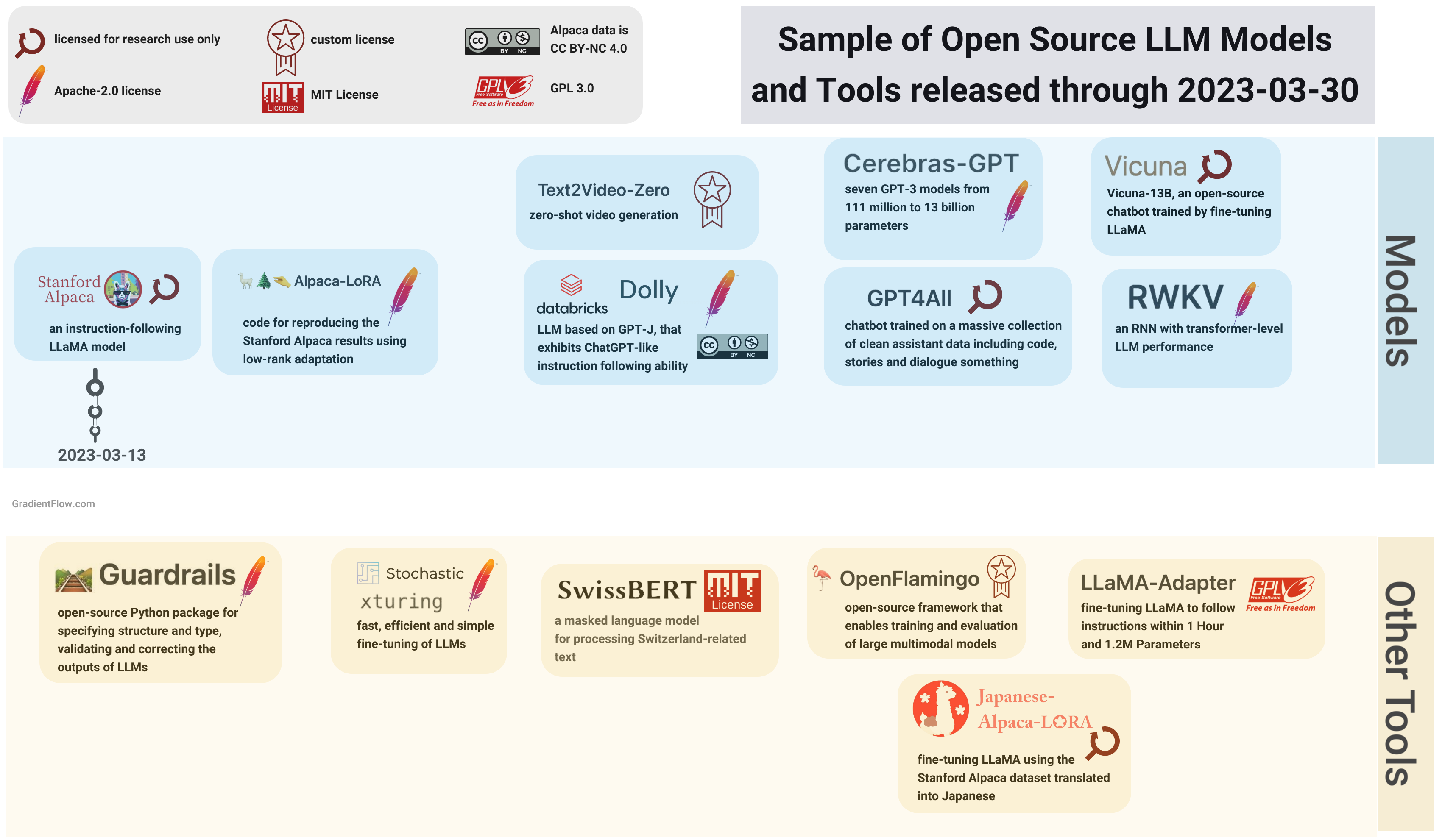
Fine-tune an existing model: I described popular fine-tuning techniques in a previous post. I expect more open source resources, including models and datasets with appropriate licenses, will become available, enabling teams to use them as a starting point to build their own custom models. For instance, Cerebras just open-sourced a collection of LLMs under the Apache 2.0 license.
Training models from scratch: After conducting online research on the production of LLMs and gathering insights from friends with experience in training tools, it became evident that there are a number of open-source components that are commonly utilized for training foundational models. The distributed computing framework Ray is widely used to train foundation models. While PyTorch is the deep learning framework used by many LLM creators, some teams prefer alternative frameworks such as JAX or even homegrown libraries that are popular in China. Ivy is an innovative open-source solution enabling code transpilation between machine learning frameworks, promoting seamless collaboration and versatility across various sources.
Many organizations that develop foundation models have dedicated teams for safety, alignment, and responsible AI. Teams that opt to build their own custom models should make similar investments.
Third-party integrations
OpenAI recently launched a new feature called "plugins" for its ChatGPT language model, which allows developers to create tools that can access up-to-date information, run computations, or use third-party services. Companies such as Expedia, Instacart, and Shopify have already used the feature to create plugins. Third-party developers can develop plugins that range from simple calculators to more complex tools like language translation and Wolfram Alpha integration.
As the creator of Terraform noted, the ChatGPT plugins interface is extremely easy to use: “you write an OpenAPI manifest for your API, use human language descriptions for everything, and that's it. You let the model figure out how to auth, chain calls, process data in between, format it for viewing, etc. There's absolutely zero glue code.”
Other LLM providers are likely to offer similar resources to help developers integrate with external services. Open-source tools like LangChain and LlamaIndex were early to help developers build apps that rely on external services and sources. I expect rapid progress on third-party integration tools for building LLM-backed applications in the near future.
Tools such as LangChain and LlamaIndex, or even a potential open protocol for plugin-sharing between LLMs, hold appeal for developers seeking the flexibility to interchange models or target multiple LLM providers. Such tools allow developers to use the best LLM for a particular task, without being locked into a single provider.
Knowledge Bases
Knowledge graphs and other external data sources can be used to enhance LLMs by providing complementary, domain-specific, factual information. We are starting to see tools that facilitate the connection to existing data sources and formats, including to new systems like vector databases. These tools enable the creation of indices over both structured and unstructured data, allowing for in-context learning. Additionally, they provide an interface for querying the index and obtaining knowledge-augmented output, which enhances the accuracy and relevance of the information provided.
Serving Models
Software services require several key features to meet the demands of modern computing. They must be responsive, highly available, secure, flexible, and interoperable across platforms and systems, while also being capable of handling large volumes of users and providing real-time processing and analytics capabilities. The deployment of LLMs presents unique challenges due to their size, complexity, and cost.
The open-source library, Ray Serve, perfectly aligns with the requirements of AI applications, as it empowers developers to construct a scalable, efficient, and flexible inference service able to integrate multiple machine learning models and Python-based business logic. Here’s an example of how to deploy an LLM with Ray Serve.
The rise of smaller and more streamlined models will improve the efficiency of LLMs in a range of applications. We’re beginning to see impressive LLMs such as LLaMA and Chinchilla that are a fraction of the size of the largest models available. Furthermore, compression and acceleration techniques like pruning, quantization, and distillation will play an increasingly important role in the use of LLMs, following the path set by computer vision.
Summary
The proliferation of tools and resources for building LLM-powered applications has opened a new world of possibilities for developers. These tools allow developers to leverage the power of AI without having to learn the complexities of machine learning. As more organizations invest in their own custom LLMs and open-source resources become more widely available, the landscape for LLM-powered applications will become more diverse and fragmented. This presents both opportunities and challenges for developers.
It is important to remember that with great power comes great responsibility. Organizations must invest in safety, alignment, and responsible AI to guarantee that LLM-powered applications are employed for positive and ethical purposes.

Spotlight
Introducing NLP Test. This much-needed, open source tool helps to improve the quality and reliability of NLP models. It is simple to use and provides comprehensive test coverage, helping to ensure that models are safe, effective, and responsible. The library offers over 50 test types compatible with popular NLP libraries and tasks, addressing model quality aspects such as robustness, bias, fairness, representation, and accuracy before deployment in production systems.
Microwave from BNH. Microwave is a free AI-based bias assessment tool, designed to assist businesses in adhering to New York City's Local Law 144. This legislation mandates the evaluation of potential biases in automated employment decision-making systems. It has been utilized for auditing AI systems for clients ranging from Fortune 100 companies to software startups, helping them measure and manage AI risks.
Training 175B Parameter Language Models at 1000 GPU scale with Alpa and Ray. Alpa is an open source compiler system for automating and democratizing model-parallel training of large deep learning models. It generates parallelization plans that match or outperform hand-tuned model-parallel training systems even on models they are designed for. This post discusses the integration of Alpa and Ray to train a 175B parameter model equivalent to GPT-3 (OPT-175B) model with pipeline parallelism. The benchmarks show that Alpa can scale beyond 1000 GPUs, achieve state-of-the-art peak GPU utilization, and perform automatic LLM parallelization and partitioning with one line decorator.

Data Exchange Podcast
How Data and AI Happened. Chris Wiggins is a Professor at Columbia University and the Chief Data Scientist at The New York Times. He is also co-author of How Data Happened, a fascinating historical exploration of how data has been used as a tool in shaping society, from the census to eugenics to Google search.
Uncovering AI Trends: Pioneering Research and Uncharted Horizons. Jakub Zavrel, the Founder and CEO at Zeta Alpha, discusses the 100 most cited AI papers of 2022, trending AI research topics, and the future of language models, and multimodal AI. He highlights the dominance of transformers, the rise of multimodal models, the significance of synthetic data, custom LLMs, chain-of-thought reasoning, and next-gen search technology.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the Ray Summit, the NLP Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, or on Post. This newsletter is produced by Gradient Flow.