

Alignment in AI: Key to Safe and Beneficial Systems

Get Started on Aligning AI
Alignment is a topic that has garnered significant attention and research in the field of AI. It is a critical challenge in AI and machine learning that seeks to ensure that machines behave in ways that are beneficial. More precisely, alignment refers to the idea that an AI system should align its goals with its human operators or stakeholders. The objective is to create AI systems that meet both functional goals and ethical and societal standards. Alignment ensures dependable, secure, and value-consistent AI systems.
Alignment has become a widely discussed topic in recent times due to instances where AI systems failed to act in accordance with the objectives defined by their developers, resulting in severe repercussions. A notable example is a chatbot that learns from online interactions and makes racist and sexist remarks, emphasizing the importance of aligning AI systems with human values. As AI technology advances and AI systems become more autonomous, the risks of misalignment become greater.

[Click to enlarge.]
In my opinion, it's crucial for Data and AI teams to prioritize alignment from the outset since it's a fundamental aspect of any Responsible AI development process. As AI is increasingly incorporated into products and systems, it's more important than ever to ensure that we create a future where we all thrive. While tools like MLOps are important for streamlining the model development and deployment process, teams need to ensure that their tools also address the ethical and societal implications of AI. Prioritizing alignment early on can help teams avoid ethical and legal pitfalls down the line, as well as build trust with stakeholders and users.
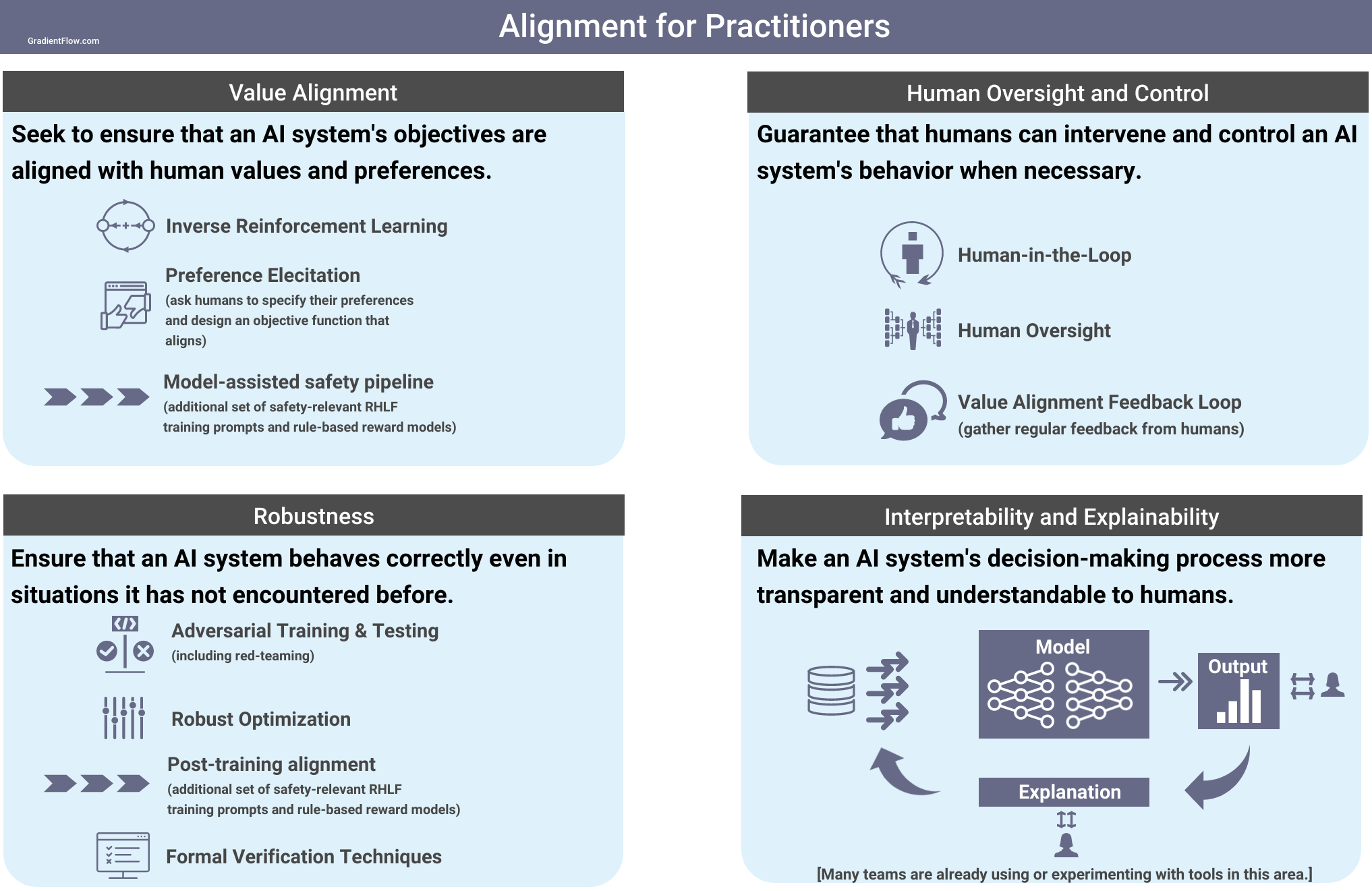
But how do you get started? Robust alignment is a difficult task that continues to be a subject of active research. Fortunately, a variety of tools and techniques are already at the disposal of teams seeking to undertake this journey.
Human-in-the-loop testing and evaluation: This involves identifying and addressing issues with the AI system's performance with feedback from human users. Incorporating human feedback into the training and evaluation process will ensure that the system is aligned with the goals and values of humans.
Adversarial training: This involves training the AI system on examples that are specifically designed to trick or mislead the system, in order to make it more robust and resistant to attacks. Adversarial training can help to ensure that the system behaves consistently and reliably in a variety of different situations.
Model interpretability and explainability: Developers can promote the alignment of AI systems with human values and objectives by increasing their transparency and comprehensibility. This can be achieved through techniques such as feature visualization, attention maps, and decision boundary analysis. These methods provide developers with insights into the model's prediction process and the factors influencing its behavior.
Value alignment algorithms: These are algorithms that are specifically designed to ensure that the behavior of the AI system is aligned with the values and goals of its human creators. Advanced techniques like inverse reinforcement learning and cooperative inverse reinforcement learning, can help machines understand the preferences and objectives of human users, and use this knowledge to improve their training process
It is worth noting that several of these methodologies are already familiar to Data and AI teams. The key is to formalize and systematize existing practices, improve documentation, and broaden the scope of your alignment tools to encompass previously overlooked aspects. With the right mindset and approach, teams can leverage existing practices and expand their alignment toolkit to include new and previously unexplored areas.
Data Exchange Podcast
Exhaustion of High-Quality Data Could Slow Down AI Progress in Coming Decades. I delve into the topic of data availability for machine learning in natural language processing and computer vision with Pablo Villalobos of Epoch. Additionally, we explore his recent post on scaling laws that explore the relationship between scale and performance of models.
Blazing fast bulk data transfers between any cloud. Paras Jain and Sarah Wooders are graduate students at the Sky Computing Lab at UC Berkeley. They are integral members of the team responsible for developing Skyplane, an open-source project designed to accelerate wide-area transfers in the cloud through the use of overlay routing and parallelism.

[A new generation of custom models are coming soon to a device near you.]
Spotlight
Run LLaMA LLM chatbots on any cloud with one click. Learn how to effortlessly host a LLaMA-powered chatbot on any cloud using SkyPilot, a one-command solution that simplifies instance setup, ensures cloud portability, and reduces costs while increasing GPU availability.
Fine-Tuning Large Language Models with Hugging Face and DeepSpeed. This article delves into the process of fine-tuning T5 language models for generating comprehensive product review summaries, utilizing Hugging Face on Databricks in conjunction with Microsoft's DeepSpeed for enhanced performance.
How Ray solves common production challenges for generative AI. Explore how Ray addresses the unique infrastructure challenges of generative AI in production environments. A number of leading AI teams, including OpenAI, Cohere, and EleutherAI, use Ray to train their large models, including ChatGPT, GPT-J, and others. This must-read article examines the computational complexities and costs associated with generative models, as well as how Ray is utilized by top AI organizations for distributed training, online serving, fine-tuning, and offline batch inference workloads.
Section 230 Won’t Protect ChatGPT. The current liability regime for LLMs could lead to reduced startup formation and limited integration of LLMs in new products due to increased legal risks. Companies will need to impose significant restrictions on LLM functionality or limit usage to pre-vetted users, potentially hindering innovation and market competition, especially for smaller companies with fewer resources.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the Ray Summit, the NLP Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, or on Post. This newsletter is produced by Gradient Flow.