

Maximizing the Potential of Large Language Models

The LLM Three-Pronged Strategy: Tune, Prompt, Reward
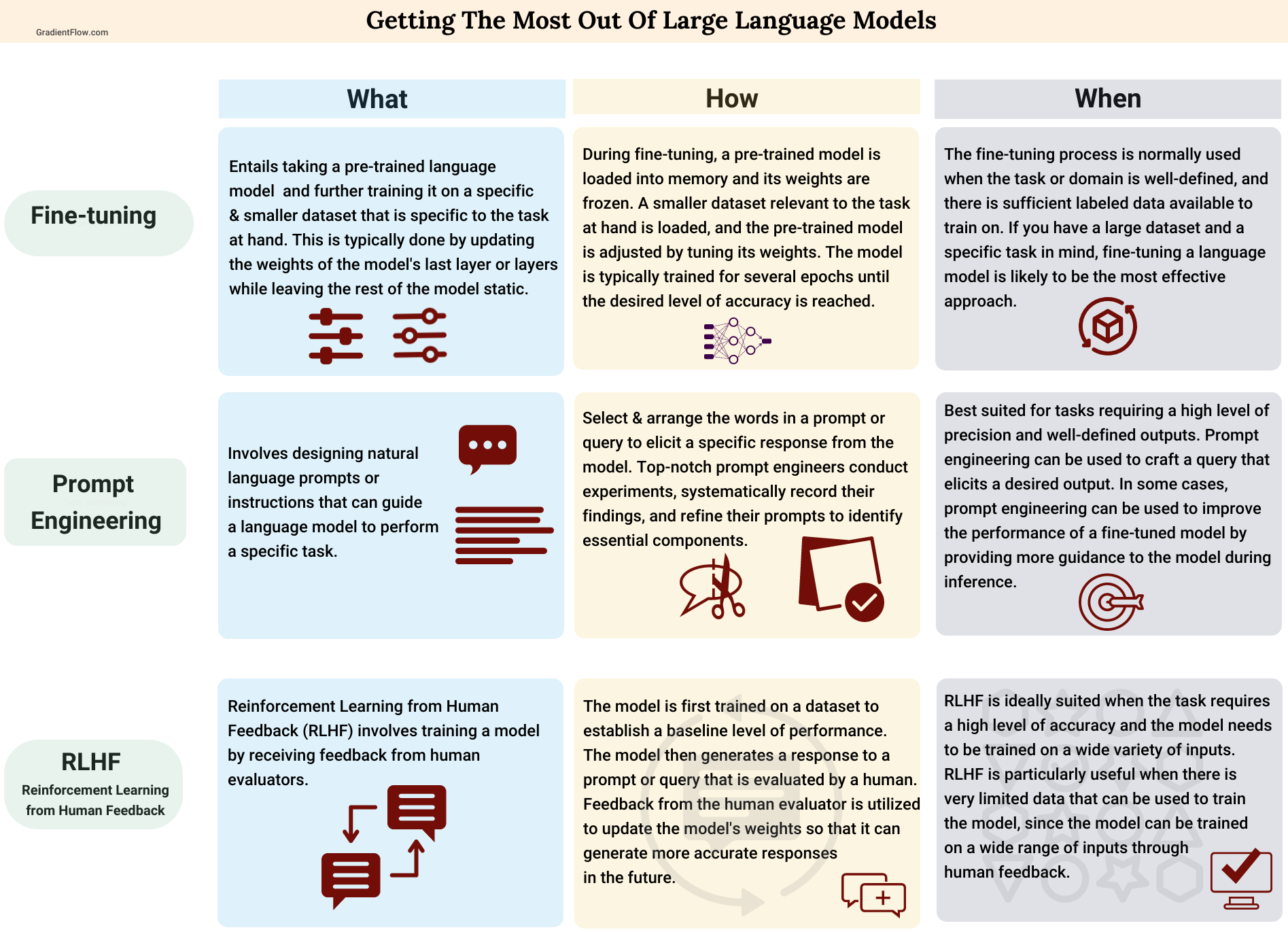
As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing the desired response. If you've tried to coax a desired output from ChatGPT or Stable Diffusion then you're one step closer to becoming a proficient prompt engineer.
At the other end of the tuning spectrum lies Reinforcement Learning from Human Feedback (RLHF), an approach that proves most effective when a model requires training across a range of inputs and demands the utmost accuracy. RLHF is widely used in the fine-tuning of general-purpose models that power ChatGPT, Google’s Bard, Anthropic’s Claude, or DeepMind's Sparrow.

[Click to enlarge.]
{kind=link}
For most teams, the best option is to use an established model and hone it to fit a particular task or dataset. The process begins with a large language model (LLM), that has been trained on a vast corpus of text data. While many LLMs are presently proprietary and solely accessible through APIs, the emergence of open-source data sets, academic papers, and even model code allows teams to refine these resources for their specific domains and applications.
Another intriguing trend is the emergence of more manageable foundation models, such as LlaMA and Chinchilla, which open up possibilities for more mid-sized models in the future. Selecting the appropriate model to fine-tune requires teams to not only consider the quantity of domain-specific data available but also assess the compatibility of the model’s (open-source) license with their specific requirements.

As our understanding of the practical applications of foundation models expands, bespoke tools are emerging to refine these models prior to their deployment. Here are some tools and resources for fine-tuning and customizing language models:
Hugging Face tutorial for fine-tuning (the company provides access to thousands of pre-trained models for a wide range of tasks).
A new set of tools will allow for fine-tuning without writing code. There are already instances of no-code tools available that enable the creation of custom models in NLP (John Snow Labs) and computer vision (Matroid). I anticipate that comparable tools will be developed to refine foundation models.
Although RLHF has gained traction among teams building cutting-edge language models, its accessibility remains limited due to the lack of available tools. Furthermore, RHLF requires the development of a reward function that is vulnerable to misalignment and other issues, and remains a specialized technique that only a few teams have mastered. Prompt engineering, while useful, falls short in producing a reliable foundation model optimized for specific tasks and domains. Despite the fact that some teams may choose to build their own models from scratch, they are unlikely to do so frequently due to the cost of training models from scratch. The trend, therefore, leans towards fine-tuning pre-trained models.
Ultimately, teams need simple and versatile tools that enable them to employ various techniques to create custom models. Although fine-tuning can generate optimal models, further adjustments using RHLF are necessary before deploying them. For instance, a recent study conducted by Anthropic indicates that prompting methods may aid LLMs trained with RLHF in producing less harmful results.

Spotlight
Do Users Write More Insecure Code with AI Assistants? This Stanford study is the first to examine how users interact with an AI code assistant for security-related programming tasks across different languages. Researchers found that participants who had access to an AI assistant based on OpenAI's Codex model wrote significantly less secure code. AI-assisted participants believed they wrote secure code. However, those who trusted AI less and engaged more with prompts had less vulnerable code.
Vector Database Primer. An overview of data management systems specifically designed for embeddings, which have become the lingua franca of modern AI. We include insightful conversations with the creators of three of the most popular data management systems for embeddings: Weaviate, Milvus, and Pinecone.
Insights from New Data and AI Pegacorns. In a recent post with Kenn So, we examine how a new group of startups were able to achieve the remarkable milestone of $100 million in annual revenue. One lingering question is where the majority of value will come from. Will it arise from the limited number of research labs that offer APIs as a service, or from the applications constructed on top of those APIs? Our belief is that the latter will ultimately prove to be more financially rewarding.

FREE Online Conference: 2023 Healthcare NLP Summit
Anyone involved with AI will find this event fascinating, as we explore how LLMs are playing a crucial role in solving mission-critical problems in the healthcare and the life sciences. We will hear from speakers on core topics like safety and reliability, security and privacy, sustainability, data quality, MLOps, and more. Several keynote presentations will highlight the versatile application of LLMs in addressing complex challenges within the field of natural language processing.

Data Exchange Podcast
Generating high-fidelity and privacy-preserving synthetic data. Jinsung Yoon and Sercan Arik are integral members of the Google team responsible for developing EHR-Safe. Using deep learning models, this solution creates highly realistic and secure synthetic electronic health records.
How technology is disrupting the venture capital industry. Brandon Jenkins, is co-founder and COO of Fundrise, the largest direct-to-individuals alternative investment platform in the U.S. Our discussion primarily focused on their recent expansion into technology investing, with a particular focus on startup companies operating in the data infrastructure field.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the Ray Summit, the NLP Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, or on Post. This newsletter is produced by Gradient Flow.