

The margin paradox threatening every AI company

The AI Bubble Is Real. Enterprise Usage Is Even More Telling.
The existence of an AI bubble is beyond dispute. What remains unclear is when or how it deflates. As investors know all too well, the most costly mistake in business is often being correct prematurely. The infrastructure layer has already booked revenues. This includes sectors like semiconductors, data centers, and power grids. The application side is a different story. It’s still a guessing game, and we’re still trying to figure out what customers will actually open their wallets for.
Rather than attempting to time the correction, I try to focus on what enterprises are actually doing with AI in production. When you look at what’s actually happening, the reality doesn’t quite match the headlines. It’s no secret that coding is the big winner so far, but the real news is the growth in administrative automation, and a clear preference for “simple and reliable” over “flashy and complex.” Furthermore, Chinese AI firms are pivoting aggressively toward Western markets, introducing application-layer competition to segments where U.S. firms have focused primarily on foundational research. Ultimately, we’re seeing two very different playbooks. Major Western AI labs are all-in on reaching AGI, but China is doubling down on the essentials: energy, supply chains, and diffusion — getting AI apps into the hands of as many companies as possible, as fast as possible.
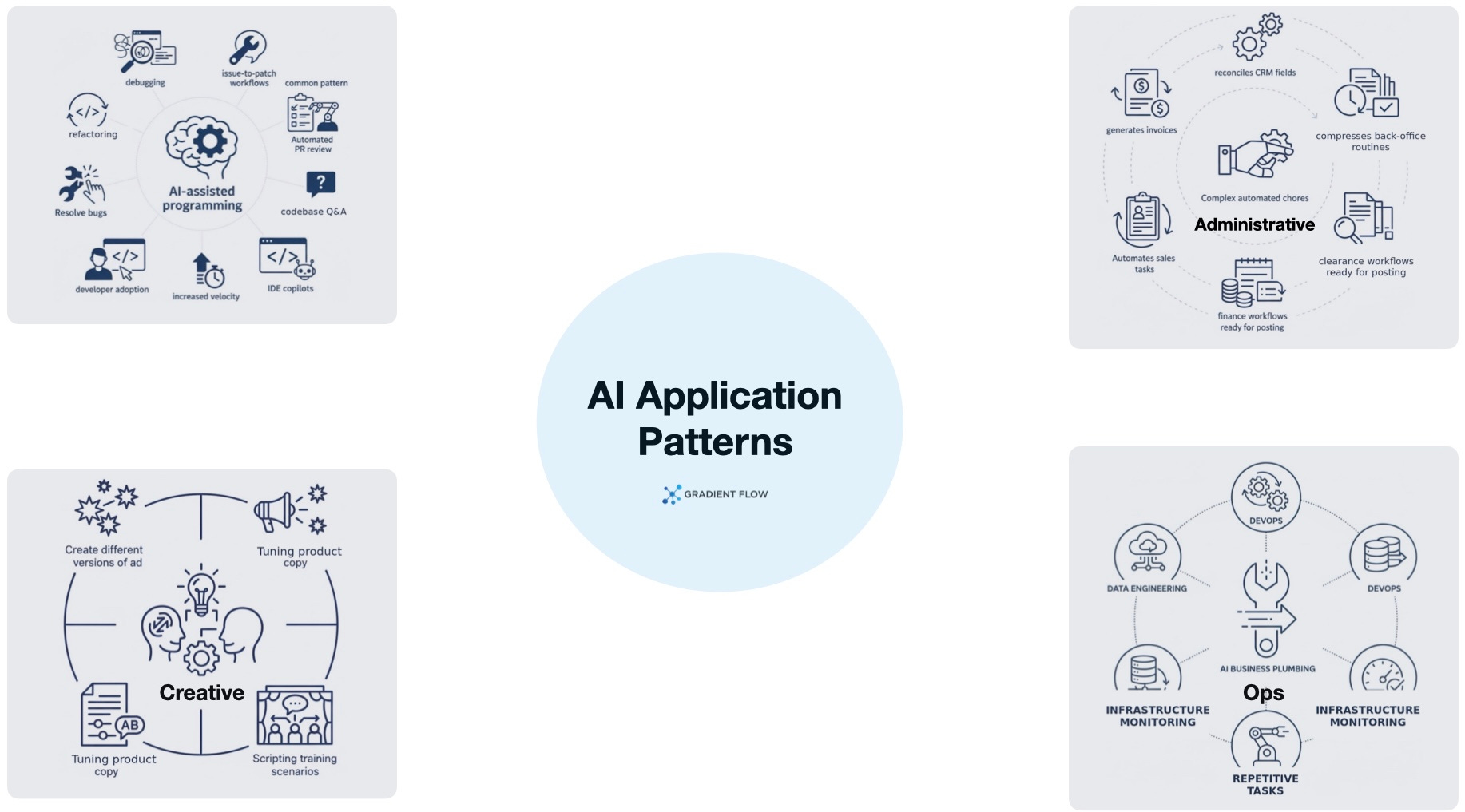
Dominant Use Cases: From Code to Creative to Administrative
Software development is the dominant enterprise workload, rising to over half of total token usage by late 2025. AI-assisted programming and coding tasks include debugging, refactoring, and resolving bugs. Developer adoption ranges from half to two-thirds using AI tools daily, significantly increasing the velocity of the entire software lifecycle. A common pattern has emerged: teams start with IDE copilots, then move up the stack into codebase Q&A, automated PR review, and “issue-to-patch” workflows that draft changes a human can validate.
But two other areas are quietly taking off just as fast: creative applications and administrative automation. Creative use has surprised many AI teams. It isn’t just about getting the AI to write a document. It’s more like a back-and-forth process where you build ideas together. This shows up in tasks like creating different versions of an ad, tuning product copy, or even scripting training scenarios.
Automating admin work is a huge deal for the bottom line, mainly because AI is now handling complex chores rather than just writing messages. AI is taking over the “busy work” of data entry and invoicing. Tasks that used to take all afternoon, like organizing insurance files or prepping financial entries, are now done automatically and handed to a human just for a final look. By automating sales tasks like record updates and follow-up sequences, AI removes the burden of manual data entry and administrative overhead.
There is also a massive shift happening under the hood. While everyone focuses on chatbots you can talk to, some of the most successful AI deployments are happening in the “plumbing” of the business. I’m hearing about more teams using agents for high-repetition tasks in data engineering and DevOps. These agents handle the tedious work of moving data between systems or keeping infrastructure running. It’s the kind of work end users never see, but it’s where the real gains in speed and automation are being made.
The Evolution of Inference Patterns
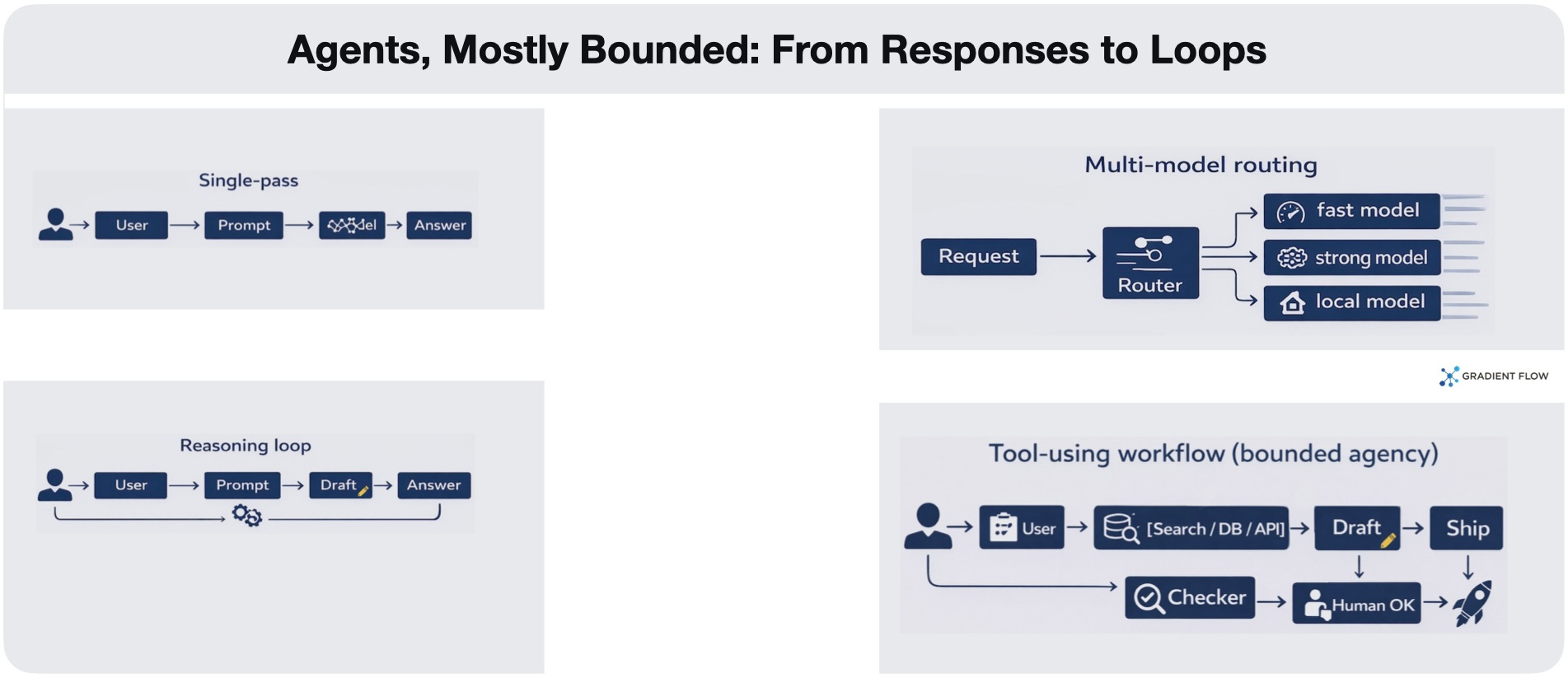
The technical architecture of AI is transitioning from single-pass pattern matching, to multi-step reasoning. New reasoning models are driving this shift. Because they allow a system to “think” before it responds, we’re seeing a total shift in the way these models use tokens. This has led to a dramatic increase in prompt lengths as developers build more complex, agentic loops. While the narrative around “autonomous agents” often outpaces the reality of production environments, there is an undeniable trend toward workflows where models plan and iterate rather than simply predict the next word.
In this architectural shift, open-weight models have carved out a stable and significant niche. Chinese models, such as DeepSeek and Qwen, have become formidable competitors, often providing performance that rivals proprietary Western models at a fraction of the cost. The strategic implication isn’t just cheaper inference. Chinese firms are using their open-weight models as a foot in the door for Western markets. Once they’ve proven their tech is legit through open-source, they move quickly into building business apps rather than just focusing on foundational models.
Deployment Patterns: Bounded Agency and Lifecycle Management
In the real world, the most successful companies are using what I call “bounded agency.” Even though we have the tech to build fully autonomous agents, most teams are choosing to keep them on a short leash. They limit the AI to just a few steps before a human has to step in and check the work. The reason is simple: reliability. By keeping a human in the loop, you ensure that if the AI makes a mistake, you can actually see what happened and fix it. This is about helping experts do their jobs faster, not replacing them.
Most teams are also choosing stability over perfection. They’d rather use a standard, off-the-shelf model with good guardrails than spend months trying to fine-tune a “perfect” custom one. It’s more practical and much easier to manage.
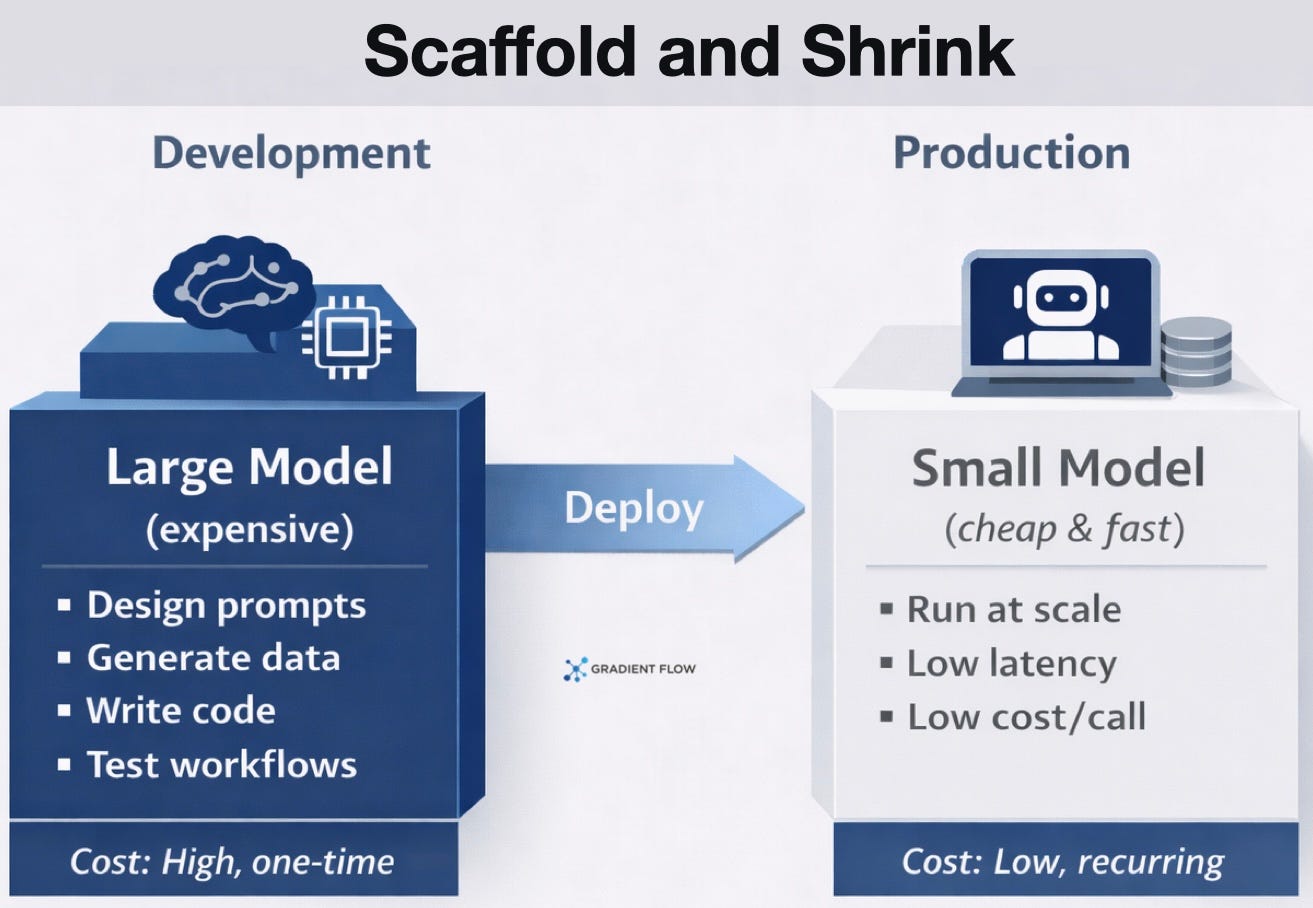
A related trend is a pattern I call "scaffold and shrink." Companies use a top-tier model as a temporary architect during the development or "vibe coding" phase. This expensive model writes the application code, refines the prompts, and generates the data needed to tune the system. Once the logic is solid, the team swaps it for a much smaller and faster model for daily use. This approach turns the high cost of a frontier model into a one-time development expense rather than a permanent tax on every customer interaction. It also levels the playing field. A small startup can use the best intelligence on the market to build its product without paying for that intelligence every time a user clicks a button. You do not need to run a massive model constantly if you have already used one to figure out exactly what your system needs to do.
The companies seeing the biggest returns tend to do two things well. First, they integrate AI deeply into their daily workflows. Instead of just using a chatbot, they turn general tasks into standard steps, like automatically updating a CRM right after a meeting. They then share those patterns across the whole company so everyone benefits. Second, they treat model upgrades as an ongoing process. They run old and new models side-by-side to catch any weird changes in behavior. They also build smart routing strategies so they aren’t using the most expensive model for every single tiny task.
This is where the competition is really heating up. New players, especially from China, are arriving with ready-to-use apps that promise instant results. This puts pressure on established companies to prove they can offer more than just a quick fix. They have to show that their systems are more secure, better integrated, and more reliable for the long haul.
Reliability and Infrastructure Gaps
Reliability is still the biggest hurdle for businesses today. Even with the top-tier foundation models we are all using right now, the success rate drops fast as soon as you give an AI agent a long, multi-step task. Think about a customer support agent trying to handle a refund. It has to look up a customer ID, check a return policy, initiate a bank transfer, and then send a confirmation email. Even if the AI is 90% accurate at each individual stage, the chances of the entire sequence working perfectly are surprisingly low. This “compound error” effect basically cuts the hype around productivity in half and is the main reason we can’t give these systems full autonomy in a production environment.
There is also a massive gap between coding and other types of work. AI is great at coding because it gets immediate feedback from a compiler. It knows right away if the code works or not. But for complex tasks like insurance authorizations or incident response, the feedback loop is much slower. You don’t find out if the AI made a mistake until much later, and those real-world consequences are much harder to automate.
AI also breaks the traditional way we build and test software. Normal software is predictable, but AI is not. It can be a bit random, which means most teams can’t rely on their usual automated testing and have to check the work manually. This creates a lot of friction, and it’s made worse by the massive increase in data being processed. Prompts have grown four times larger because these agent loops require thousands of tokens just to complete a single task.

Finally, there is a hidden risk in how concentrated AI usage has become. Most companies are using AI for the same ten things, like fixing software bugs. This creates a “single point of failure” for the whole business. If a model’s performance degrades or a provider has an outage, it wouldn’t just be a minor glitch. It could paralyze core operations across the entire company.
Trust, Cybersecurity, and Geopolitical Considerations
Trust and safety aren’t just about ethics anymore. They are a business requirement. Trust failures show up as delayed deployments and worse outcomes, especially when they involve concerns around privacy, safety, and governance. Many organizations are effectively trying to scale autonomy before they’ve standardized policies for permissions, audit, incident response, and supplier risk. (I covered agents and security shifts in a previous article.)
Data sovereignty is also reshaping governance decisions. Buyers increasingly prioritize model origin and data residency, which influences vendor selection and hosting architecture. This is particularly relevant as Chinese startups expand into the West: enterprise buyers will demand more rigorous proof of control, transparency, and compliance before trusting these providers with sensitive, high-impact workflows.
The Margin Paradox and Market Correction
As AI tools become common, the industry is running into a bit of a trap. When everyone has the same efficiency-boosting tech, the savings just get passed on to the customer. This leads to lower prices and thinner profit margins for everyone. This deflationary cycle is being accelerated by the arrival of Chinese firms like Manus and Atoms. These companies add competitive pressure precisely in the application layer where monetization remains most uncertain, bringing sophisticated tools and outcome-driven approaches honed in brutal domestic competition.
While the West is swinging for the fences with AGI, China is focused on the plumbing: securing supply chains and ensuring AI reaches every corner of the economy.
We all recognize that a market correction is unavoidable, and because AI is now a large share of the market narrative, the spillover won’t be neatly contained. Infrastructure suppliers are partially insulated. Capital spent on hardware is a sunk cost once it’s booked, so any adjustment is more likely to show up as slower growth than revenue reversals. But there is a major caveat here. Much of the massive data center build-out is being funded by debt. If the application side doesn’t start generating enough cash to cover those loans, that debt could turn a simple market slowdown into a much deeper financial strain for the companies building the physical foundations of AI. Cloud revenue, meanwhile, remains largely tied to basic compute and storage rather than AI-specific offerings. The challenge for investors is that while a few durable winners will emerge, trying to spot them today is more about following the crowd than how these businesses actually make money.

{kind=link}
Eventually, the bubble will burst, but that doesn’t mean the technology will stop being useful. History shows that once the hype dies down, the real work of “diffusion” begins as these tools become a standard part of every industry. That’s why I focus on what enterprises are actually doing today. By learning from the patterns that are working in the real world, you can move past the hype and start building AI projects that actually deliver results.

Reader Bot: What Happens When AI Reads and Why It Matters. I still think nothing beats curling up with a good book, but we are facing a perfect storm where long-standing declines in reading meet AI’s ability to process text for us. This book offers an excellent overview of how to use these models as helpful co-readers without outsourcing the actual joy of reading.
I Deliver Parcels in Beijing. Years ago in Shanghai I kept dodging electric scooters zipping around the French Concession to make deliveries, and it turns out that was just the tip of the iceberg. This book puts you inside the life of the person on that scooter, where every bathroom break has a cost in yuan and every failed delivery eats into wages that were already razor-thin.
Strangers: A Memoir of Marriage. I've read a lot of memoirs over the years, and this is one of the best. It is a sharp look at how little we sometimes know the people closest to us.
Ben Lorica edits the Gradient Flow newsletter and hosts the Data Exchange podcast. He helps organize the AI Conference and the AI Agent Conference, while also serving as the Strategic Content Chair for AI at the Linux Foundation. You can follow him on Linkedin, X, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.