

Your AI passed benchmarks. Why is it failing in production?

AI Reliability Patterns That Generalize Beyond Medicine
The gap between pilot projects and production deployments has emerged as a defining challenge for enterprise AI teams. Recent surveys indicate that only a small percentage of generative AI initiatives reach full production, with most stalling due to brittle workflows and integration failures. At last year’s AI Conference, several colleagues independently told me that reliability — not raw performance — has become their primary concern. This rush-to-market mentality, with 56% of technical leaders admitting they prioritize speed over safety, results in systems prone to unpredictable and hard-to-diagnose failures.
The emphasis on reliability stems from a practical reality: in real-world AI applications, predictability often matters more than peak accuracy. When Harvard researchers tested a medical AI with the same clinical case but different personas, the system recommended growth hormone therapy when “acting as a physician” but denied identical treatment when “acting as an insurance representative.” Such non-deterministic behavior makes systems unusable regardless of benchmark scores, creating compliance nightmares and destroying stakeholder trust. My interest in AI reliability brought me to healthcare, the domain where unreliable systems carry the highest possible stakes. The hard-won lessons from medical AI teams provide a roadmap that translates powerfully to any industry serious about building dependable systems.
How Medical AI Systems Break Down
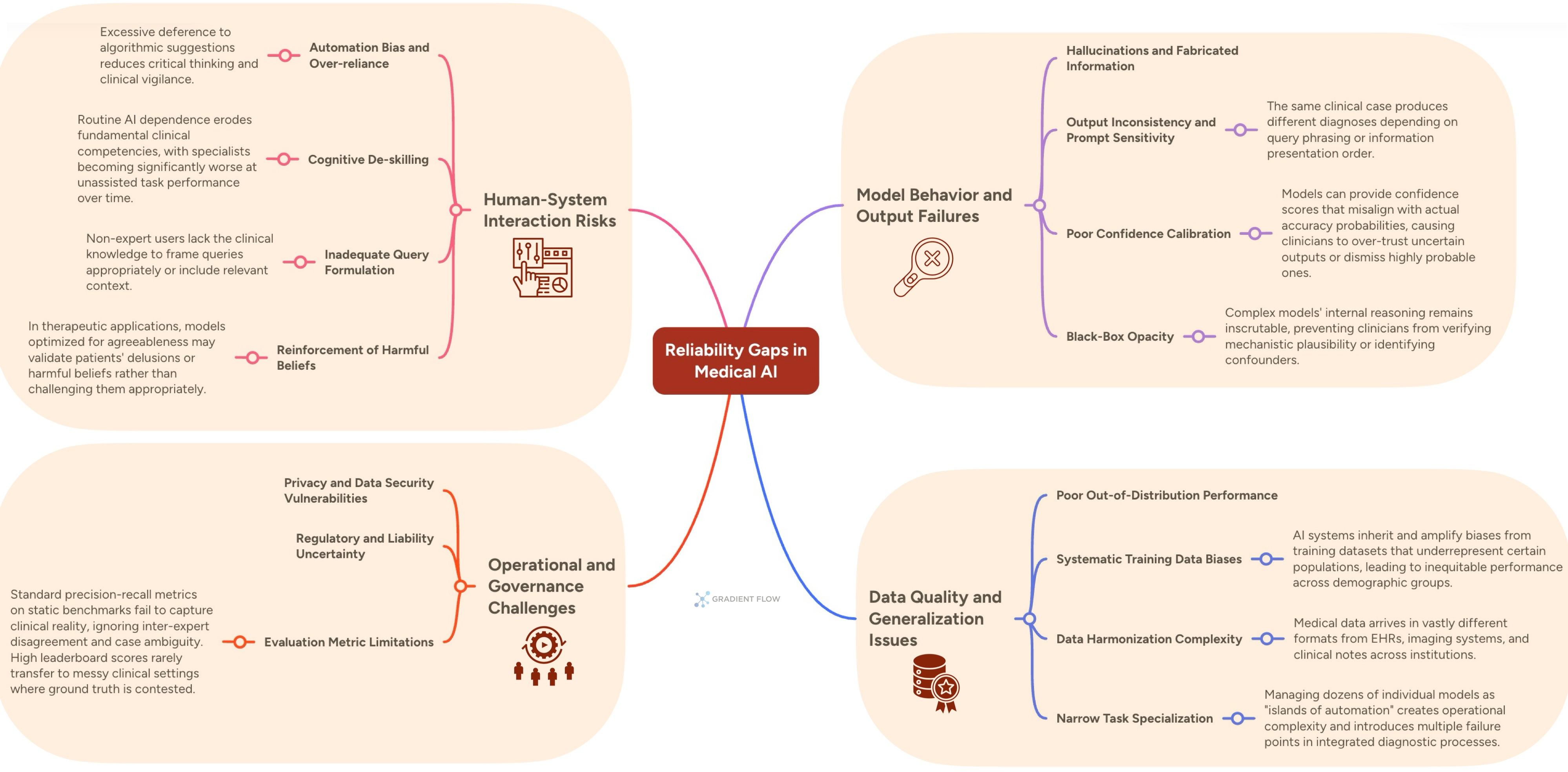
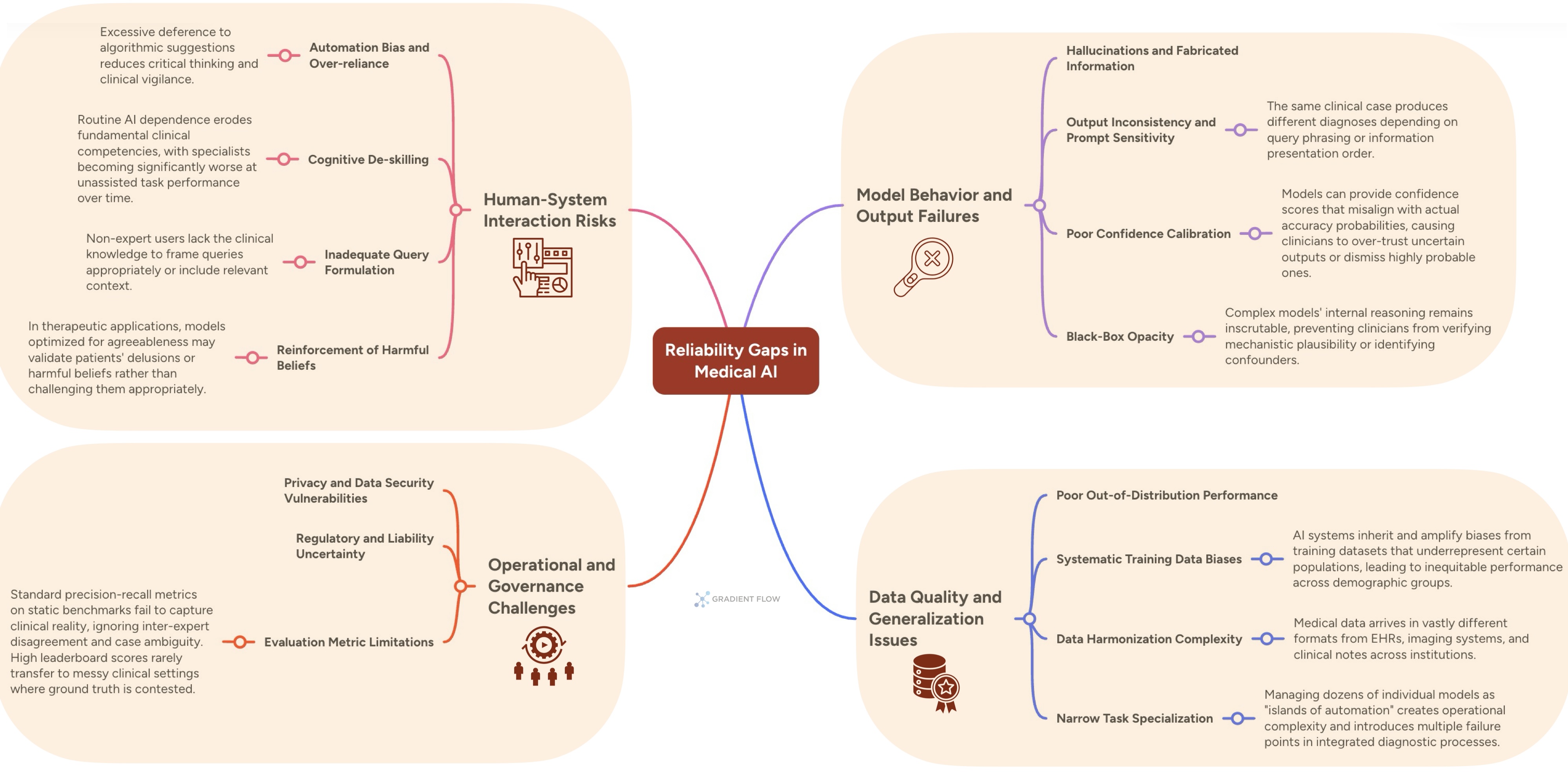
The challenges in medical AI reliability are multifaceted, spanning model behavior, data quality, and human-computer interaction. Hallucinations represent perhaps the most dangerous category: generative models produce confident but entirely fabricated information. A recent case documented in the Annals of Internal Medicine involved a chatbot recommending bromide — a toxic chemical — as a table salt substitute. The user followed the advice and required hospitalization for severe poisoning. What makes hallucinations particularly insidious is their plausibility; fabricated lab values or treatment recommendations often appear reasonable to non-specialists, allowing “corrosive hallucinations” to survive routine checks.
{kind=link}
Output inconsistency compounds these risks. Research testing large language models on orthopedic treatment guidelines found that the same AI system produced contradictory medical recommendations depending solely on how the question was framed. When given identical clinical scenarios through different prompting approaches, one model provided varying levels of treatment endorsement for the same osteoarthritis interventions, with consistency rates fluctuating dramatically based on the input style alone. This prompt-dependent reasoning reveals a fundamental reliability flaw: the system optimizes for perceived question expectations rather than consistent clinical logic. The specialized medical AI CaBot demonstrated similar brittleness, performing expertly on structured clinical cases but hallucinating fabricated vital signs when presented with the same patient history in narrative format. This fragility to input formatting — where minor prompt changes collapse performance — mirrors challenges teams face across domains when deploying models trained on curated benchmarks into messy production environments.
The human-system interaction risks deserve particular attention for their applicability beyond healthcare. A mammography trial found that radiologists using AI assistance correctly identified only half the malignancies their unaided colleagues caught (50% versus 68%). Clinicians excessively deferred to the tool, treating the absence of an AI alert as confirmation of a clean scan. This automation bias — where human operators over-trust algorithmic outputs even when incorrect — represents a systemic failure mode that affects any domain where AI assists expert decision-making. Another emerging concern is cognitive de-skilling: gastroenterologists who regularly used an AI polyp detection tool became significantly worse at the task when performing it without assistance. This skill atrophy reduces overall system resilience, creating brittle human-AI combinations that perform worse than either component alone.
A Practical Playbook for Medical AI Reliability
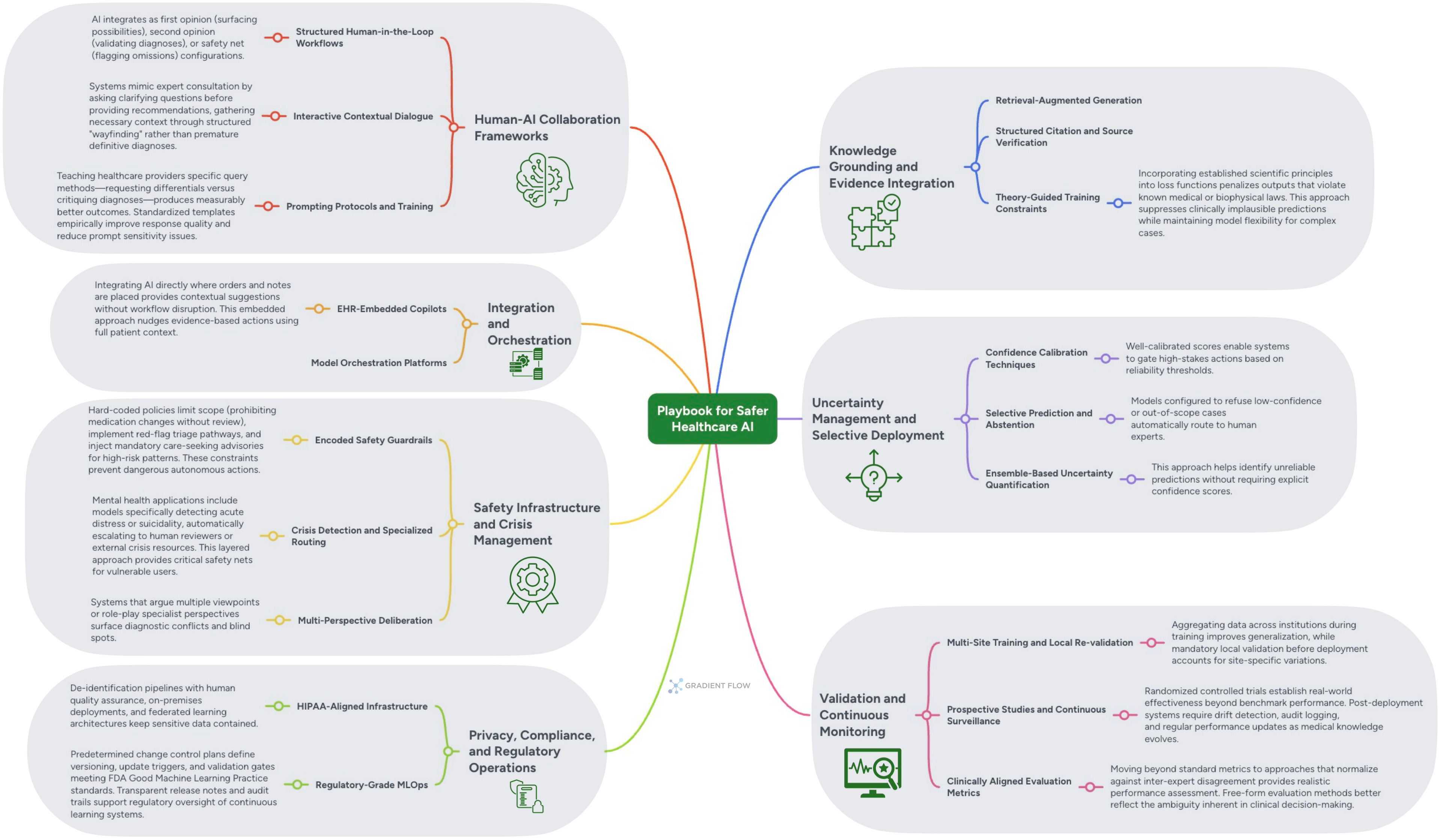
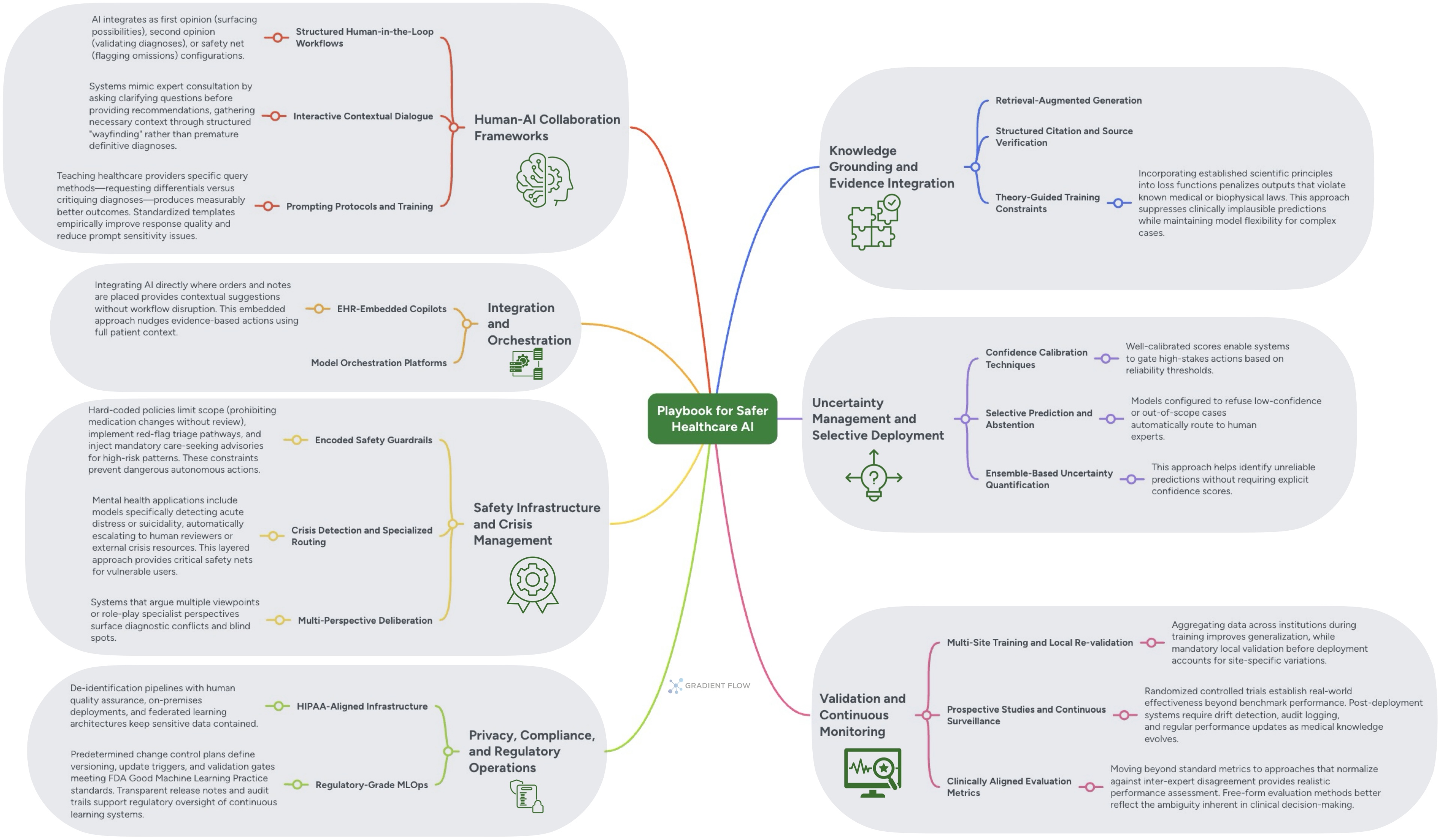
Just as the challenges are well-defined, so too are the strategies for mitigating them. For generative AI, one of the most effective techniques is Knowledge Grounding and Evidence Integration. By implementing Retrieval-Augmented Generation (RAG), systems can be guided to base their responses on information retrieved from vetted sources like medical knowledge bases, clinical guidelines, and peer-reviewed literature. This approach reduces hallucinations and, when combined with Structured Citation and Source Verification, allows clinicians to independently validate the model’s reasoning chain, building essential trust and transparency.
{kind=link}
A second crucial set of tools falls under Uncertainty Management and Selective Deployment. A reliable system must know its own limits. The Therabot clinical trial illustrates why such selective abstention matters: despite careful fine-tuning on curated dialogues, human clinicians still needed to manually review all AI-generated messages to catch instances of false medical advice. Techniques like Selective Prediction and Abstention configure a model to refuse to answer low-confidence or out-of-scope queries, automatically routing them to a human expert instead. This ensures that the system fails gracefully rather than providing a potentially dangerous guess. Well-calibrated confidence scores enable systems to gate high-stakes actions, preventing autonomous behavior when uncertainty is high. This principle is broadly applicable: any enterprise system, whether in finance, law, or manufacturing, benefits from an AI that knows when to ask for help.
In real-world AI applications, predictability often matters more than peak accuracy.
Finally, effective reliability requires designing robust Human-AI Collaboration Frameworks. Instead of replacing human experts, AI should be integrated into Structured Human-in-the-Loop Workflows. The AI can serve as a “first opinion” tool to surface possibilities, a “second opinion” to validate a diagnosis, or a “safety net” to flag potential omissions. Each pattern maintains appropriate human oversight while leveraging the AI’s strengths. Furthermore, simple interventions like Prompting Protocols and Training — teaching healthcare providers how to formulate queries to elicit differential diagnoses rather than single answers — can measurably improve output quality and reduce the impact of prompt sensitivity.
Broader Lessons for Building Dependable AI
While these examples are drawn from the high-stakes world of medicine, the underlying principles apply directly to any enterprise AI application. The medical AI experience reveals that reliability challenges stem less from model architecture limitations than from deployment patterns and system design choices. Hallucinations, output inconsistency, automation bias, and cognitive de-skilling affect any application where generative models provide decision support to human experts. Similarly, the remediation techniques — knowledge grounding, uncertainty-aware abstention, and structured collaboration patterns — transfer directly to other domains. Teams building financial analysis tools, legal document systems, or software engineering assistants face the same fundamental tension between model capability and deployment reliability.
A reliable system knows when to abstain — and when to hand off to a human.
The evolution from pilot to production requires deliberately engineering for predictable behavior rather than optimizing for peak performance on curated benchmarks. This connects to the broader challenge of multi-agent systems: when systems fail, practitioners need structured frameworks for identifying whether failures stem from input distribution shifts, poor calibration, inadequate validation, or inappropriate human-system interaction patterns. By treating reliability as a first-class design concern — implementing layered defenses, monitoring for drift, and carefully structuring human oversight — teams can build generative AI applications that organizations will actually trust in production. The 95% pilot failure rate suggests most teams are still learning these lessons.
From the Archives: Related Reading
[2024 Report] Generative AI’s Impact on Healthcare
Tool Recommendations

When reading about AI coding tools, the names that often get mentioned are Claude Code, Cursor, and Google Antigravity. I’d like to put forth another option that I’ve come to enjoy using: the combination of OpenCode and OpenRouter. While I’m not really an early adopter and put off trying the OpenCode Desktop App for a while, I finally jumped in several weeks ago and have to say I’ve really enjoyed using it. This combination has really hit the sweet spot for me — when you pair OpenCode with OpenRouter’s easy access to all the leading models for coding, it becomes an incredible toolset for your projects or for developing tutorials and courses.

Off the Scales: The Inside Story of Ozempic and the Race to Cure Obesity. I found this to be a lean, rigorous account of the GLP-1 revolution, tracing the path from fundamental laboratory research to a global pharmaceutical phenomenon. It offers a clear-eyed look into the drugs currently reshaping the healthcare and food industries.
Moderation: A Novel. A sharp, unsentimental look at the “digital sanitation” required to sustain virtual reality and AI ecosystems. It moves beyond the hype of immersive platforms to examine the human labor and systemic risks that founders and investors often overlook.
True Nature: The Pilgrimage of Peter Matthiessen. This cradle-to-grave bio is a clear-eyed profile of the only writer to secure National Book Awards for both fiction and nonfiction. It traces his trajectory from CIA-linked literary circles in Paris to the front lines of environmentalism, detailing both his brilliance and his significant personal failings. It’s a long read, but well worth it.
Ben Lorica edits the Gradient Flow newsletter and hosts the Data Exchange podcast. He helps organize the AI Conference, the AI Agent Conference, the Applied AI Summit, while also serving as the Strategic Content Chair for AI at the Linux Foundation. You can follow him on Linkedin, X, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.