

Why Your Multi-Agent AI Keeps Failing

Beyond the Hype: The Reality Gap in Multi-Agent Systems
The allure of multi-agent systems (MAS), where teams of LLM-based agents collaborate, is undeniable for tackling complex tasks. The theoretical benefits seem clear: breaking down problems, parallelizing work, and leveraging specialized skills promise more sophisticated AI solutions than single agents can deliver. Yet as teams building these systems are discovering, translating this promise into reliable performance is proving unexpectedly difficult. Recent analysis, including a recent paper from UC Berkeley, reveals that performance gains over simpler single-agent approaches are often minimal, and failure rates on standard benchmarks can be alarmingly high.
This disconnect prompted the team from UC Berkeley to investigate why these multi-agent systems stumble. By meticulously examining the execution traces of several popular MAS frameworks across numerous tasks, they identified recurring patterns of failure. These aren't just isolated glitches; they fall into distinct categories related to how systems are specified, how agents interact (or fail to), and how tasks are verified. Understanding these common pitfalls is the first step for practitioners aiming to build MAS that live up to their potential.
Support our work & get exclusive member benefits! 🙏
So, what kinds of problems plague these multi-agent systems? The Berkeley researchers didn't just find random errors; their analysis revealed distinct patterns. Using a systematic approach grounded in analyzing over 150 real-world execution traces, they developed the Multi-Agent System Failure Taxonomy (MASFT). These failures fall into three roughly equal categories: problems with the initial setup (Specification and System Design), breakdowns in agent collaboration (Inter-Agent Misalignment), and issues with checking the work and finishing (Task Verification and Termination). Each category accounts for nearly a third of the observed failures, suggesting no single area is solely to blame.
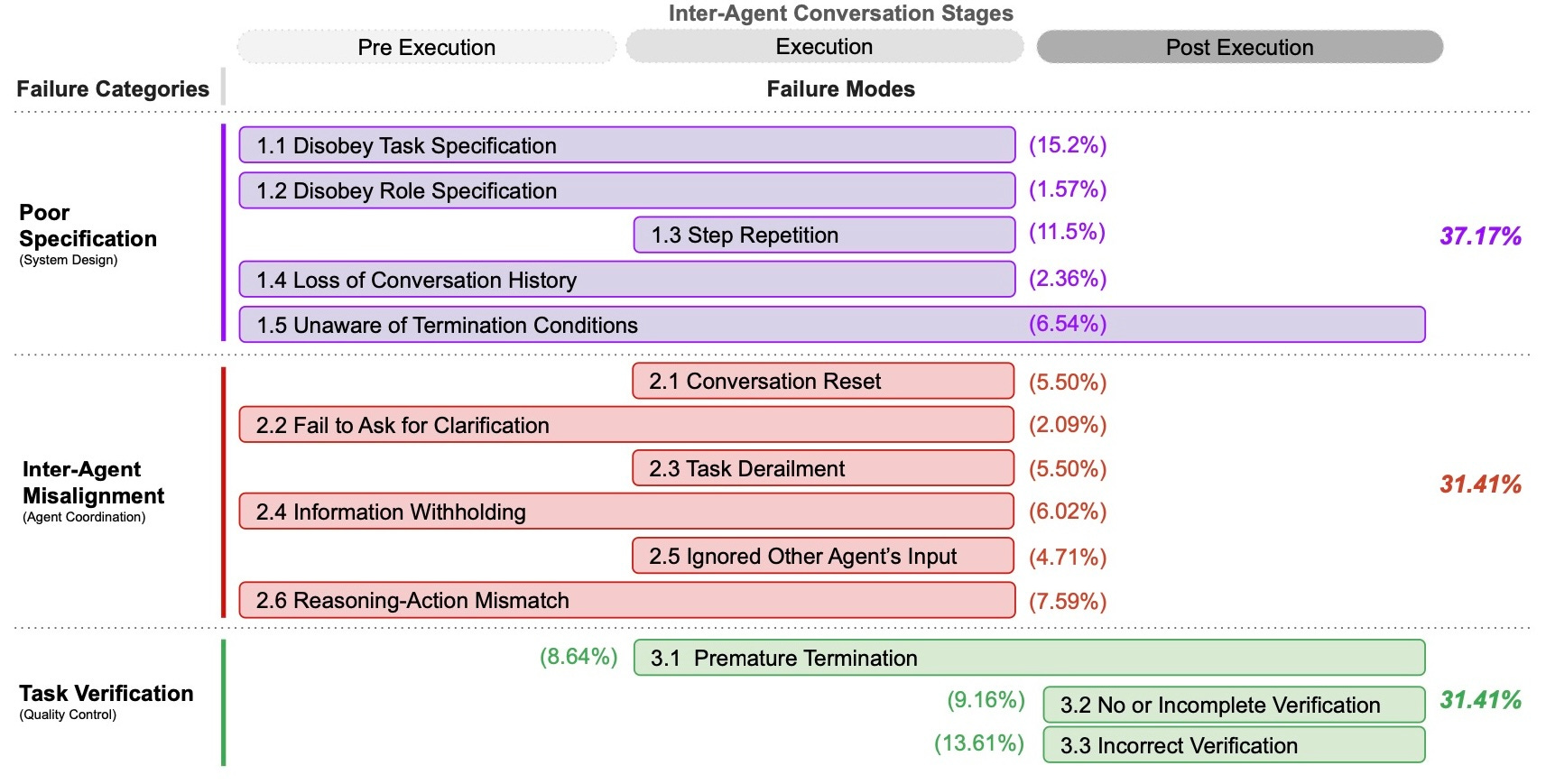
Delving deeper, the taxonomy identifies 14 specific failure modes that practitioners might recognise. Under Specification, for instance, agents might simply disobey task constraints (the most frequent single failure mode at 15.2%) or get stuck repeating steps. Inter-Agent Misalignment includes communication failures like withholding crucial information (as when one agent knew the required login format but didn't tell another) or agents simply ignoring each other's input. Crucially, the Verification category highlights common pitfalls like incomplete checks (a 'tester' agent checking if code compiles but not if it actually works) or outright incorrect verification, which was surprisingly common (13.6%). This detailed breakdown provides a valuable diagnostic tool for teams debugging their own multi-agent implementations.
Armed with this taxonomy, how can teams pinpoint failures in their own systems? The Berkeley researchers offer a practical approach: an "LLM-as-a-Judge" pipeline. By providing a capable LLM with the MASFT definitions and examples, the model can analyze execution logs and automatically flag potential failure modes with reasonable accuracy (achieving 94% accuracy against human experts in their tests). Conveniently for practitioners, the team has open-sourced this tool alongside their annotated dataset, providing a ready-made diagnostic assistant.
Identifying failures is one thing; fixing them is another. The study explored interventions, distinguishing between "tactical" tweaks – like refining prompts, adding self-verification steps, or managing conversation flow – and more fundamental "structural" changes. While tactical fixes provided modest gains (around 9-15% accuracy improvements in their case studies on ChatDev), they often proved insufficient for robust deployment and varied significantly with the underlying LLM. This suggests that truly reliable multi-agent systems will likely require deeper, structural redesigns.
These more involved structural strategies tackle the core challenges highlighted by the taxonomy in Figure 1 above. Think robust, domain-specific verification (going beyond simple code compilation checks), standardized communication protocols between agents (moving past ambiguous natural language), incorporating agent confidence levels into decision-making, or even fine-tuning agents for specific collaborative roles using reinforcement learning. Exploring these structural avenues appears necessary to bridge the gap between the theoretical promise and the practical reality of multi-agent systems.

{kind=link}
{kind=link}
{kind=link}
The Berkeley study provides critical, sobering insights for teams building multi-agent systems. Their Multi-Agent System Failure Taxonomy (MASFT) reveals that pitfalls aren't isolated but span the entire lifecycle, distributed almost evenly across initial Specification & System Design (37%), collaborative Inter-Agent Misalignment (31%), and final Task Verification & Termination (31%). The research underscores that while tactical tweaks like prompt refinement offer modest gains, achieving robust, reliable MAS capable of handling complex enterprise tasks likely demands more fundamental, structural redesigns in areas like communication protocols, verification mechanisms, and agent roles.
Become a premium member: Support us & get extras! 💖
While understanding these failure points is essential for avoiding common traps, it represents only one side of the agent story. In my next post, we'll pivot to explore the pragmatic reality and tangible promise of agentic AI already at work. For now, I'll leave you with these practical recommendations derived from the Berkeley researchers’ work:
Be Aware of Failure Modes. Use the MASFT taxonomy to diagnose specific failures in your system
Define Specialized Roles. Configure agents with clear, distinct responsibilities and enforce role boundaries
Implement Verification Pipelines. Ensure robust verification mechanisms, especially for numerical calculations and critical decisions
Structure Communication. Use standardized formats for agent interactions and create shared memory mechanisms
Use Confidence Thresholds. Implement adaptive thresholds to trigger additional verification when confidence is low
Test with Fresh Data. Validate improvements using new scenarios, not the same data used for development
Consider Structural Fixes. Don't rely solely on prompt engineering; address fundamental architectural issues
Join us in NYC on May 6-7, for the AI Agent Conference—use the discount code GRADIENTFLOW25 and grab one of the few remaining tickets!

{kind=link}
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the AI Agent Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.