



RAG Reimagined: 5 Breakthroughs You Should Know

RAG's Next Chapter: Agentic, Multimodal, and System-Optimized AI
While autonomous agents and large-scale reasoning models are currently attracting significant attention and investment, I find that Retrieval-Augmented Generation (RAG) and its variants remain foundational to building practical, knowledge-intensive AI applications. The RAG space isn't static; it's continually evolving, offering compelling solutions for real-world AI challenges.
Take GraphRAG, for instance—a design pattern that garnered attention last year. It enhances the traditional method by integrating knowledge graphs (KGs) or graph databases with large language models (LLMs), aiming to extract and utilize structured information from unstructured data to enrich retrieval. A key consideration, however, is that GraphRAG requires access to a knowledge graph. While tools for automating knowledge graph construction are improving, the truth is I still don’t hear that many teams are going down this path. Props to Neo4j's DevRel team for hustling at conferences to get AI teams excited about GraphRAG!
GraphRAG is just one example. More broadly, I find the RAG landscape to be a fertile ground for advancements critical to production AI. In this article, I want to highlight several developments that have particularly caught my attention, as they offer tangible benefits for teams developing AI solutions and address core challenges in information retrieval, system integration, reliability, and the handling of complex, real-world data.
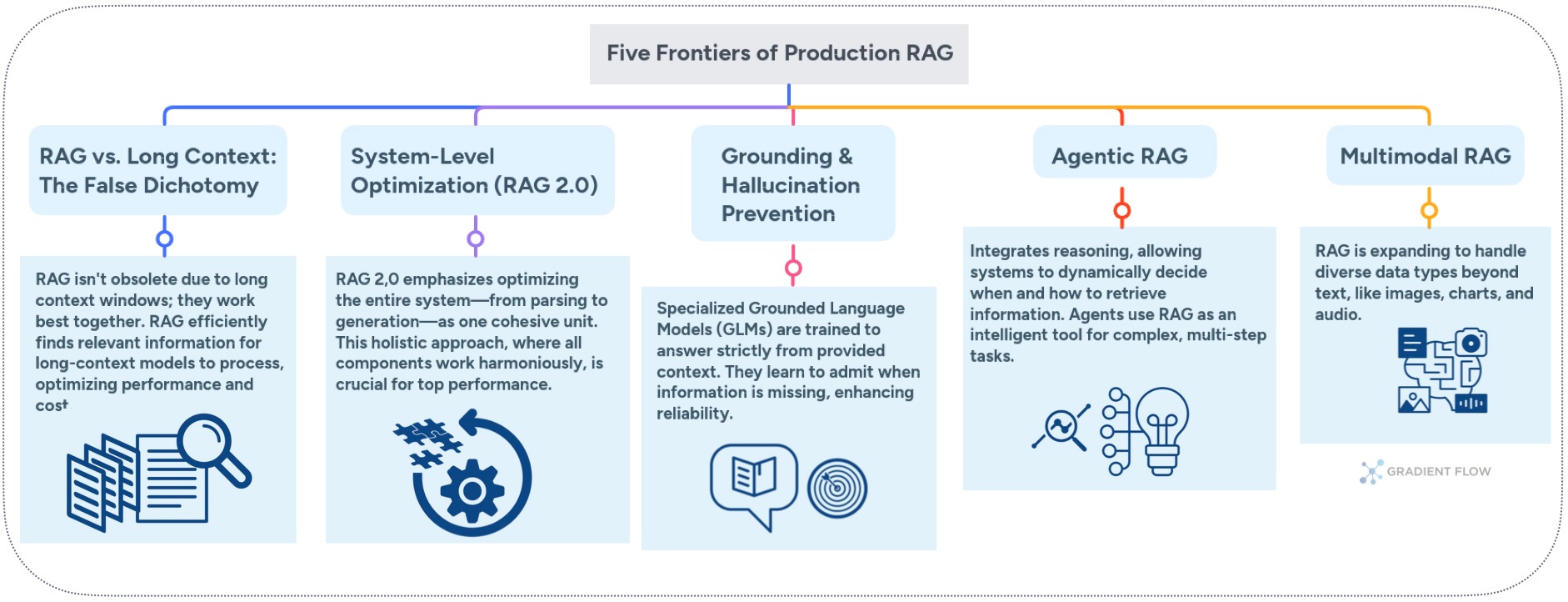
1. RAG vs. Long Context: The False Dichotomy
The advent of LLMs boasting context windows of several million tokens has led some to question RAG's continued necessity. However, practical application and empirical evidence suggest that RAG is far from obsolete. Relying solely on massive context windows can be inefficient and may even degrade performance. Studies on models with extensive context capabilities have indicated that information recall can falter as the context grows, a phenomenon sometimes referred to as "lost in the middle," where details deep within long inputs are overlooked.
The optimal approach combines RAG's precision with long-context capabilities. Consider a practical scenario: extracting a specific fact from a large document corpus doesn't require processing every available token. Using RAG to identify relevant passages, then applying the model's extended context to that refined set, delivers superior results while managing computational costs. This becomes particularly critical when deploying reasoning models that compound latency and expense with each processing step. For teams building high-frequency applications, the difference between retrieving 2,000 relevant tokens versus processing 200,000 tokens can determine economic viability.
2. System-Level Optimization: The Next Wave in RAG
RAG 2.0 is an architectural shift from assembling discrete components to building integrated systems. Early RAG implementations often resembled patchwork solutions—combining arbitrary embedding models, chunking strategies, and language models without considering their interactions. The new paradigm treats document parsing, chunking, embedding, retrieval, re-ranking, and generation as interdependent elements requiring joint optimization.
A recent conversation with Douwe Kiela, CEO of Contextual AI, highlighted how this philosophy manifests in practice. He stressed that the LLM is but one component in a larger architecture; the overall system's efficacy determines the quality of the output. This “end-to-end” approach treats elements like document parsing not as preliminary chores but as critical foundations. Inadequate extraction of information from complex documents—filled with tables, diagrams, or varied layouts—cannot be fully rectified by superior chunking or embeddings downstream. This integrated design aims to ensure that each stage, from information extraction to final answer generation, functions harmoniously.
For developers, this means moving towards solutions where components are designed to work together, potentially reducing the burden of component selection and tuning. The focus is on the end-to-end performance of the system in retrieving and synthesizing information accurately and efficiently.
{kind=link}
3. Tackling Hallucinations: Teaching Models to Say "I Don't Know"
When precision is paramount, an AI model's willingness to admit ignorance can be its most valuable trait. Contextual AI's Grounded Language Model (GLM) is engineered with this principle in mind. Rather than improvising when faced with uncertainty, the GLM is designed to base its responses strictly on the information retrieved from designated knowledge sources. It provides inline citations for its assertions and, critically, is built to refrain from answering if supporting evidence is not found within the provided context. This approach, demonstrated effectively in enterprise settings, directly curtails the tendency of some models to generate plausible but unfounded statements.
However, as highlighted in a recent conversation with key members of Snowflake's AI Research Team, even specialized models can face challenges with ambiguous or insufficient retrieved context. They argue that while fine-tuning improves groundedness, it cannot entirely eliminate hallucinations. Snowflake’s strategy incorporates a multi-layered system that includes not just retrieval and generation, but also a crucial verification stage. In this final step, a separate module—potentially employing a different type of model to reduce shared biases—scrutinizes whether the generated answer is faithfully supported by the retrieved passages. If the evidence is deemed insufficient, the system is designed to "fail closed," explicitly indicating a lack of information rather than risking an unsupported assertion.
These distinct strategies—one focusing on a specialized, citation-aware model and the other on a robust, post-generation verification process—converge on a critical theme: building explicit "I don't know" capabilities directly into the architecture of RAG systems. This marks a shift from relying solely on prompt engineering to embedding safeguards that prioritize factual accuracy. For enterprises where the cost of misinformation is high, such designed-in epistemic humility is not merely a feature, but a requirement for trustworthy AI.

4. Agentic RAG: How Agents are Making RAG Smarter
The integration of reasoning models and inference-time compute transforms RAG from a static pipeline to a dynamic, adaptive system. Rather than retrieving information for every query by default, agentic RAG systems reason about whether, when, and what to retrieve. Domain-agnostic planners now decompose complex queries, select appropriate retrieval strategies, evaluate results, and orchestrate multi-step operations until objectives are met.
Does this evolution mean RAG is obsolete? Not at all. Agents actually incorporate RAG as a fundamental part of their toolkit. When advanced research tools or other agentic systems interact with data, their process of gathering information to inform generation is, in essence, RAG. The distinction lies in the sophistication of the "generator" (the agent) and its ability to actively manage the "retrieval" process. Concepts like Google's Agentic RAG illustrate this, where autonomous agents iteratively refine search queries and evaluate information.
You can see this in action with emerging 'deep research' tools that methodically break down complex questions, search iteratively across various sources, and then pull it all together into comprehensive reports. This mirrors the shift from simple prompt-response patterns to systems capable of sustained investigation and reasoning—a capability increasingly needed by teams building sophisticated AI applications.
5. Multimodal RAG: When RAG Meets Vision and Speech
Production data rarely confines itself to pure text. Technical documentation combines circuit diagrams, code snippets, tables, and charts within single documents. Financial reports blend numerical tables with narrative explanations. Medical records integrate imaging data with clinical notes. Effective RAG systems must therefore be capable of processing and integrating information from these varied data types.
Multimodal RAG systems employ specialized extractors that identify content types, process each modality through appropriate models, and maintain unified indices while preserving modality awareness. The open-source Lance file format exemplifies infrastructure evolution supporting these requirements. Lance v2 is designed to efficiently handle AI/ML workloads, including vector embeddings and diverse data types, offering better performance for point lookups and managing wide schemas, which directly benefits the retrieval speed and scalability of multimodal RAG systems.

Research projects like UniversalRAG demonstrate the importance of maintaining separate embedding spaces for different modalities rather than forcing unified representations. Their dynamic routing mechanism selects appropriate knowledge sources based on both modality and granularity requirements, achieving superior performance compared to single-modality approaches.
RAG's Next Chapter: Key Developments on the Horizon
The trajectory of RAG development reflects a broader pattern in AI systems: evolution from simple augmentation techniques to sophisticated, integrated platforms. As Douwe Kiela noted in our recent conversation, two developments would significantly accelerate progress. First, we need models that truly deliver high-quality recall and processing right up to their maximum advertised token counts. This would ease development, though RAG would still be key for operating efficiently at scale. Second, improved vision language models capable of fine-grained understanding would unlock the vast stores of information locked in complex visual formats across engineering, finance, and healthcare domains.
So, what does all this mean for those of us actually building AI applications? I think the items I highlighted are pretty exciting – they open up a lot of new possibilities. Naturally, this also means we need to be thoughtful about how we put these more powerful tools to work. The tools for creating production-grade RAG systems have matured dramatically, but real success still hinges on understanding the interplay between components, the importance of proper evaluation (for both what the system can and can't answer), and the often-underestimated role of solid document processing. As RAG continues its evolution from simple retrieval to reasoning-enabled, multimodal systems, teams who grasp these developments will be best positioned to deliver the reliable, scalable AI applications.

Data Exchange podcast
How a Public-Benefit Startup Plans to Make Open Source the Default for Serious AI. Manos Koukoumidis, CEO of Oumi Labs, champions "unconditionally open" AI foundation models—making all data, code, weights, and recipes transparent and reproducible—as the only route to trustworthy, production-grade AI. He outlines Oumi's platform for open collaboration and their HallOumi model for claim verification, aiming to create a "Linux moment" for AI.
From Vibe Coding to Autonomous Agents. Jackie Brosamer and Brad Axen from Block discuss Goose, their open-source AI agent designed to automate complex engineering and knowledge work by integrating LLMs with various tools via the Model Context Protocol (MCP). They dive into Goose's architecture, diverse applications within Block, and strategies for managing AI limitations.
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the AI Agent Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.