


The Multimodal Moment: Turning Holistic Perception into Business Value
AI models are demonstrating rapidly growing proficiency in understanding and generating content across diverse modalities like text, images, audio, and video. This capability is maturing in large foundation models, such as Google Gemini, which can now efficiently handle complex, long multimedia inputs. Chinese firms are also advancing quickly: ByteDance's UI-TARS and OmniHuman, together with Alibaba's Qwen 2.5-VL, are setting new benchmarks in multimodal comprehension and generation.
Beyond model scale and training data, architectural design is proving critical for effective multimodal integration. Research from organizations like Apple and Meta indicates that "early-fusion" architectures—which integrate different data types earlier in the processing pipeline—often outperform traditional "late-fusion" approaches where modalities are processed separately before combining. This focus on deeply integrated architectures is essential for developing models that can perceive and reason about the world in a truly seamless, holistic manner.
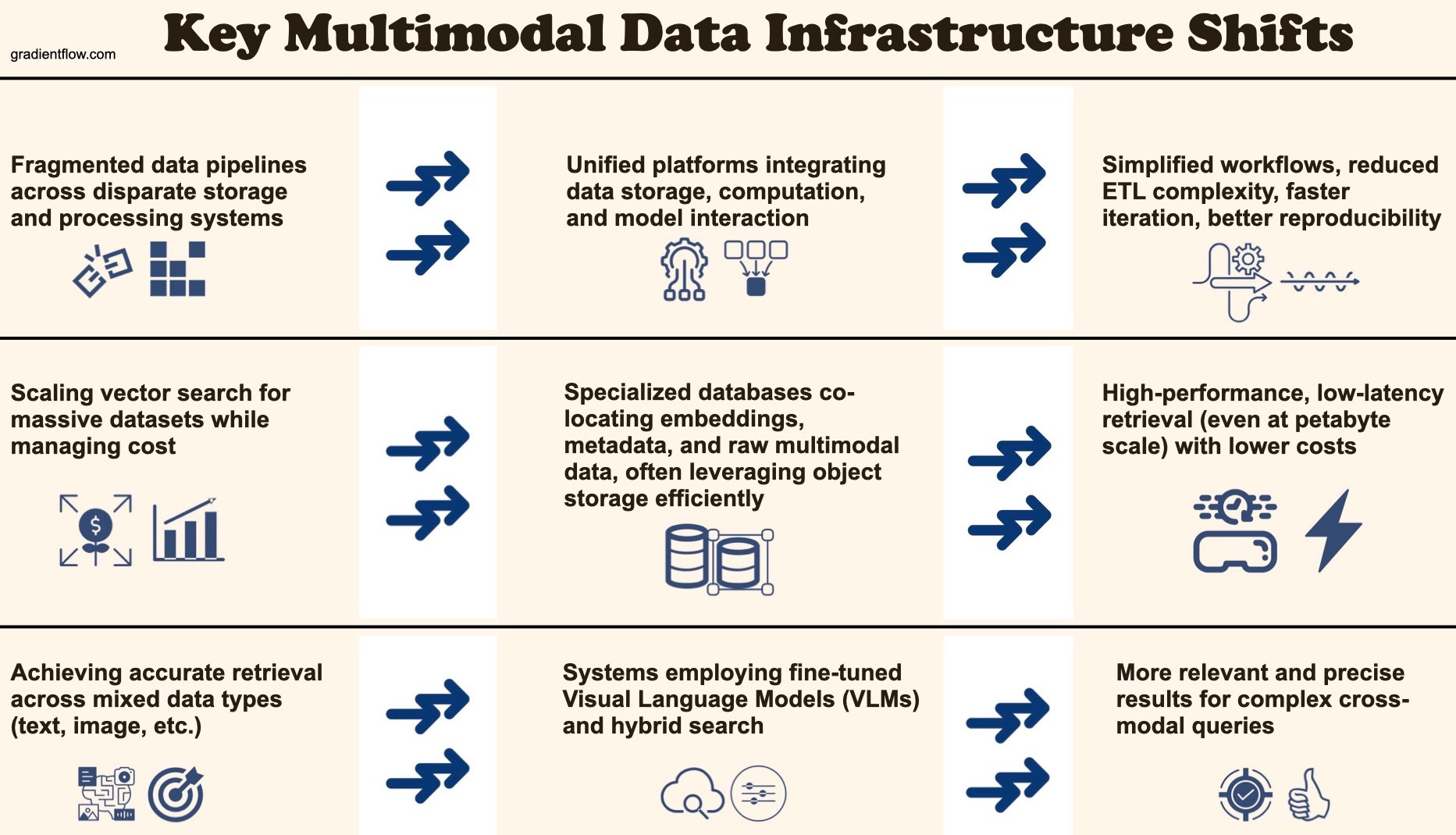
Integrating multiple modalities unlocks powerful capabilities but introduces significant engineering complexity across the entire lifecycle—from data handling to training and deployment. Teams need to look beyond just model selection to establish robust infrastructure and processes:
1. Architectural Strategy
Evaluate the trade-offs between different fusion strategies based on your specific tasks and performance requirements
Consider whether your use case benefits more from early integration of modalities or separate processing with later combination
2. Data Infrastructure Investment
Evaluate specialized tools designed for multimodal data management (e.g., LanceDB, ActiveLoop, Pixeltable)
Prioritize solutions that handle diverse data types natively and enable efficient retrieval through vector or hybrid search (e.g., Lance data format)
Look for platforms offering automatic versioning and incremental updates to accelerate development cycles
3. Performance Optimization
Recognize that multimodal processing is typically more resource-intensive than single-modality approaches
Explore modality-specific optimization techniques and ensure your infrastructure can scale efficiently
Consider distributed computing environments and frameworks like Ray that support parallel processing

{kind=link}
4. Model Orchestration
Implement systems that dynamically route requests to the most appropriate model based on the input type, quality requirements, and resource constraints
Develop fallback strategies for when certain modalities are unavailable or of poor quality
5. Value-Driven Implementation
Critically assess which modalities genuinely enhance your application's value proposition
Balance technical capability with actual user needs—adding complexity without clear benefits can drain resources unnecessarily
By addressing these considerations systematically, you can can better utilize the expanding capabilities of multimodal AI while managing the associated technical complexity and resource requirements.
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the AI Agent Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.