

Paradigm Shifts in Data Processing for the Generative AI Era

Bridging the Gap: Multimodal Data Processing for Generative AI
By Ben Lorica and Dean Wampler.
In the rapidly evolving landscape of Generative AI, one of the most critical, yet often underestimated challenges is data processing and preparation. While models have become more sophisticated, the data pipelines feeding them have not kept pace, especially in leveraging heterogeneous computational resources like CPUs and GPUs. Traditional data processing systems are ill-equipped for the dynamic allocation demands of modern ML workloads, leading to underutilized GPUs, increased processing times, and escalating operational costs.
This efficiency gap is further widened by the fundamental shift from traditional SQL-centric to AI-centric data processing. Modern AI applications must process an unprecedented variety of unstructured data—including meeting recordings, sales calls, PDFs, and videos—far beyond the scope of conventional data engineering tools. Even seemingly straightforward document processing pipelines now involve complex steps like PII removal, OCR extraction, cross-language translation, and vector embedding generation. AI-centric processing leverages machine learning technologies to automate crucial tasks such as data cleaning, feature extraction, and synthetic data generation, enabling organizations to handle complex, multimodal datasets effectively. However, these advanced capabilities come with demanding infrastructure requirements. Processing multimodal data that combines text, images, audio, and video requires GPU-intensive computing power that often surpasses the capabilities of legacy systems. This technological gap is forcing organizations to rethink their data processing architecture and invest in more robust, AI-optimized infrastructure.
Consider the training of multimodal models like Stable Diffusion, where CPU-intensive preprocessing tasks such as video decoding, cropping, and encoding must seamlessly integrate with GPU-intensive processes. The mismatch between CPU-based data processing and GPU-based training often creates bottlenecks, leading to expensive GPUs sitting idle while waiting for data. This inefficiency is particularly evident in video processing pipelines, where CPU-bound tasks like decoding, cropping, and encoding can severely impact overall system performance. These challenges not only affect training pipelines but also impact batch inference scenarios, where suboptimal resource allocation can significantly reduce throughput. Optimizing the balance between CPU and GPU utilization becomes crucial for teams aiming to build cost-effective and high-performing Generative AI applications.

Moreover, the complexity of preparing unstructured data for Large Language Models (LLMs) and other frontier models adds another layer of difficulty. Tasks like cleaning, filtering, deduplication, and formatting are not only time-consuming but also critical for model accuracy. The lack of adequate tools to handle diverse data modalities and to scale seamlessly from development to production exacerbates the problem. We believe that addressing these data processing and preparation challenges is essential for unlocking the full potential of Generative AI, enabling teams to improve model performance, accelerate development cycles, and achieve cost-effective scalability.
Why Current Data Tools Fall Short in Generative AI
Despite the abundance of data processing tools and frameworks available today, AI teams building generative applications still face significant challenges that existing solutions fail to address. Traditional batch and stream processing systems struggle to efficiently manage heterogeneous machine learning pipelines that require diverse resources such as CPUs and GPUs. Batch processing frameworks like Apache Hadoop and Apache Spark execute jobs in sequential stages, necessitating the complete materialization of intermediate data before proceeding to the next stage. This approach can lead to increased memory usage, writing intermediate results to disk, and underutilization of GPUs, especially when different stages have varying resource requirements. While stream processing systems are capable of pipelining execution across various resources, they are typically optimized for processing specific types of data (like database records or text), rather than handling diverse, heterogeneous data processing workloads. This rigidity prevents them from adapting to changing workload demands, making them ill-suited for ML pipelines where requirements can fluctuate significantly between operators and over time.
Existing machine learning data loading systems like PyTorch's DataLoader and TensorFlow's tf.data were primarily designed for single-node environments where data loading happens alongside GPU training. These systems face significant challenges when scaled to distributed, multi-node scenarios, as their parallelization approaches typically rely on basic libraries such as Python multiprocessing. A key limitation is that the data loader's lifecycle is tightly coupled with the training job itself, creating potential bottlenecks and inefficiencies. While recent cloud-native streaming systems have emerged to handle specialized data formats and stream data from cloud storage, they still face general limitations in distributed execution and resource management similar to those of traditional ML data loaders.
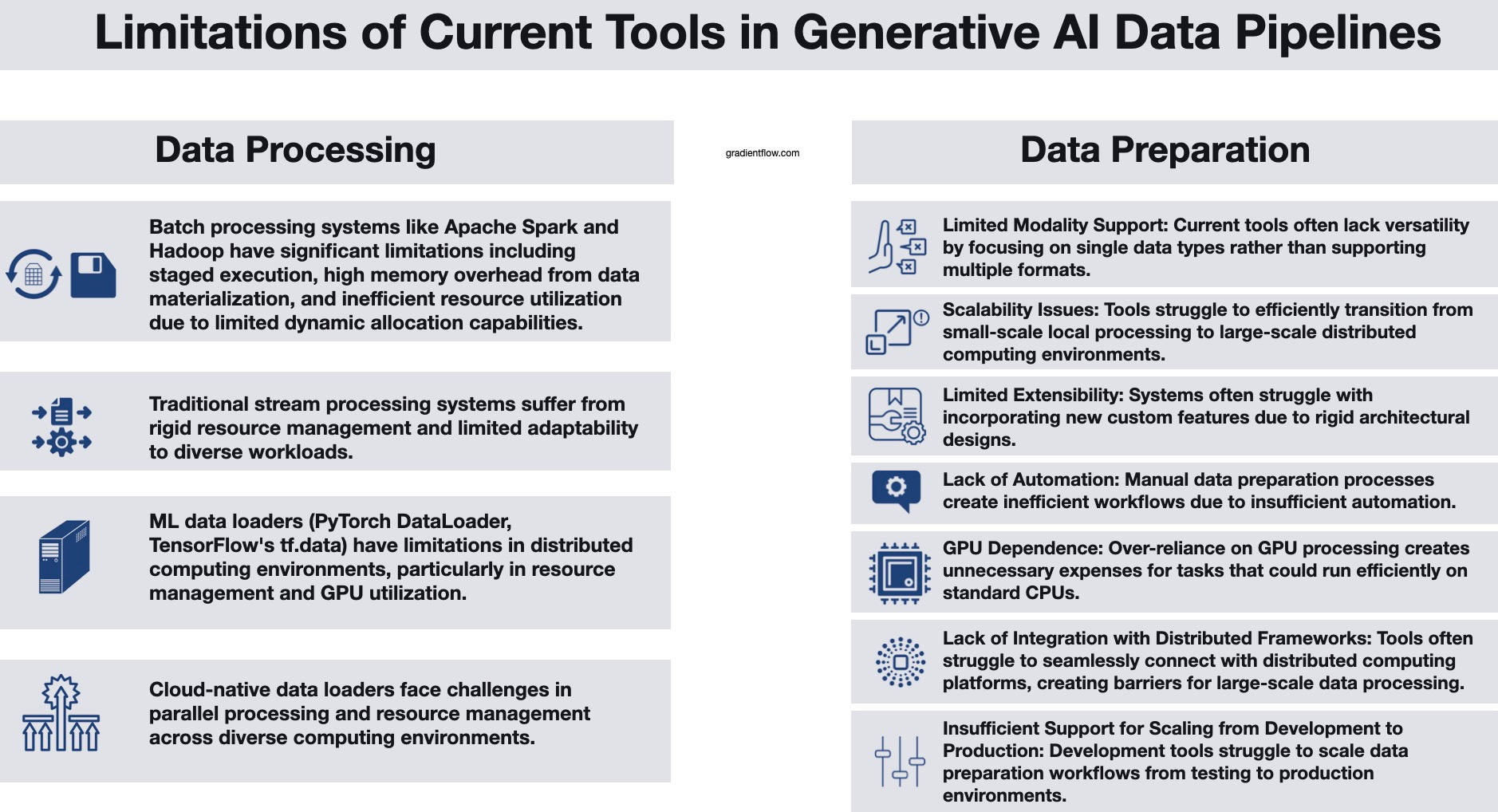
The landscape is equally challenging when it comes to selecting data preparation tools for Large Language Models (LLMs). While existing tools like BigCode, DataTrove, and Dolma provide valuable capabilities, they are often limited in scope - many focus primarily on specific use cases like pre-training rather than supporting multiple applications such as fine-tuning and RAG. Most tools are designed primarily for data scientists, potentially excluding other personas like application developers. While some tools offer scalability through frameworks like Slurm or Spark, they often lack the flexibility to seamlessly transition from local development to large-scale production environments. Additionally, many rely solely on command-line interfaces rather than providing automated workflow options through user interfaces. Perhaps most importantly, adding new scalable modules to these tools can be challenging, often requiring deep expertise in distributed computing frameworks like Ray or Spark.
Multimodal Data Processing with Ray Data
Ray Data is a compelling solution for modern AI teams, offering a distributed data processing framework built on the Ray platform that addresses the emerging need to blend stream processing with batch processing. This approach combines the advantages of both batch and stream processing, enabling dynamic resource allocation and pipelined execution across heterogeneous resources like CPUs and GPUs. By effectively bridging the gap between traditional systems, Ray Data maximizes hardware utilization and minimizes processing times.
One of the key differentiators of Ray Data is its adaptive scheduling mechanism, which dynamically adjusts resource allocation and task parallelism based on real-time workload characteristics. This capability, combined with features like streaming repartitioning and dynamic parallelism, allows teams to intelligently balance CPU-intensive preprocessing tasks with GPU-heavy training and inference, preventing bottlenecks and idle resources. For instance, in training multimodal models like Stable Diffusion, Ray Data can offload preprocessing tasks to CPUs or cheaper GPUs, improving training throughput and reducing costs compared to traditional methods.
In addition, Ray Data supports both online preprocessing—processing data on-the-fly during training—and offline preprocessing, where data is processed beforehand and stored. This flexibility allows teams to choose the most efficient approach based on their specific workloads and resource availability. Furthermore, Ray Data enables overlapping execution of different pipeline stages such as data loading, preprocessing, and inference. By executing these stages concurrently rather than sequentially, Ray Data maximizes resource utilization, reduces bottlenecks, and increases throughput.
Ray Data's integration with the Ray platform leverages distributed execution capabilities, enabling scalable and fault-tolerant processing across clusters. Its Python-friendly API simplifies the development of distributed data workflows without requiring deep expertise in distributed computing frameworks, allowing AI teams to focus on model development rather than wrestling with infrastructure challenges.
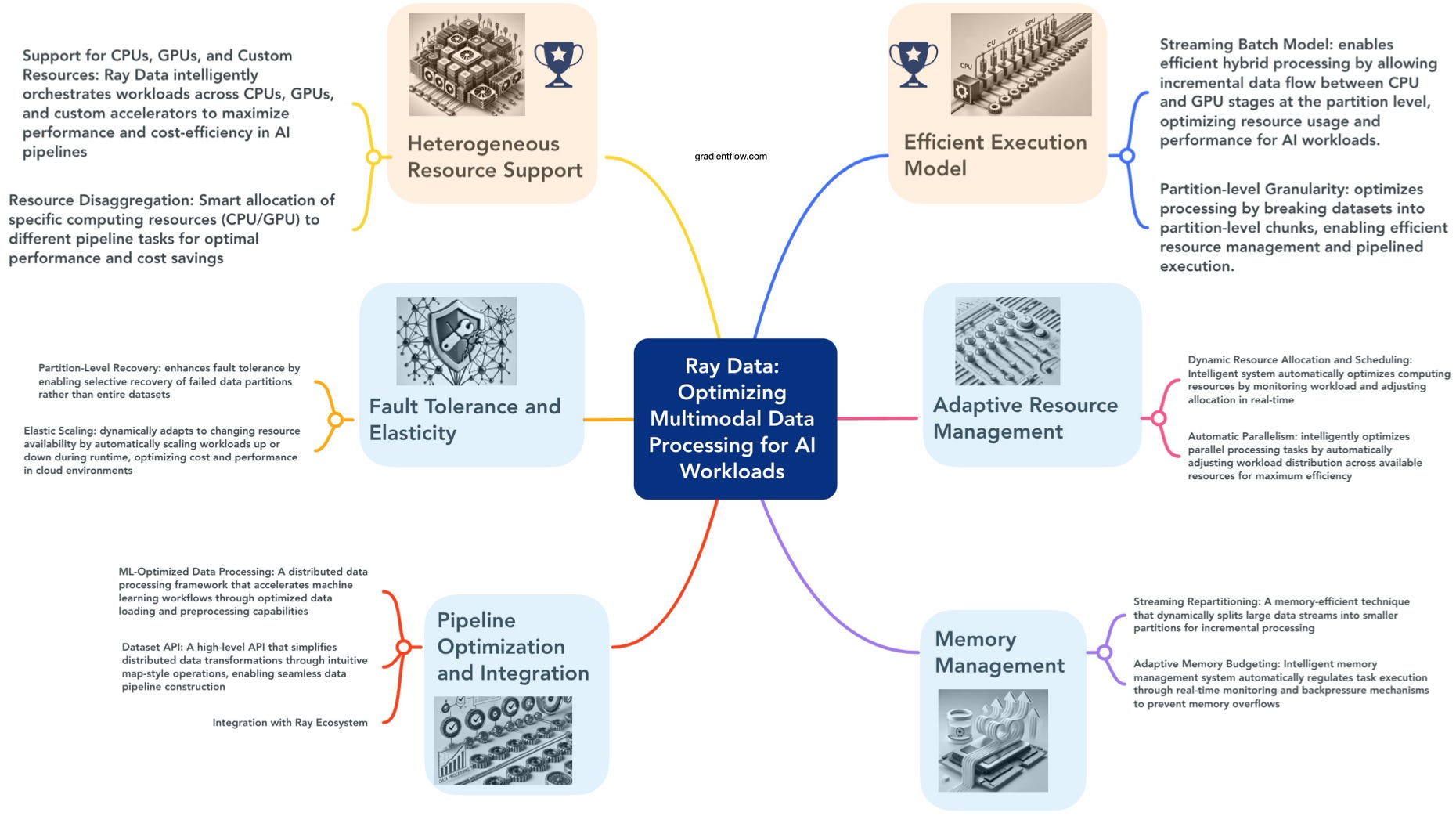
Real-world evidence of Ray Data's effectiveness is compelling. We are aware of cases reporting throughput improvements of 3–8x over traditional batch and stream processing systems when handling heterogeneous pipelines involving both CPUs and GPUs. Use cases like video and image batch inference have demonstrated significant reductions in completion time and improved GPU utilization by efficiently offloading preprocessing tasks to CPUs.
Major technology companies have already validated Ray Data's effectiveness in production environments. ByteDance successfully deployed Ray Data for processing petabyte-scale datasets across audio and video pipelines, particularly for tasks like feature extraction and video preprocessing for AI model training. Ray Data’s ability to scale seamlessly from local scripts to thousands of nodes while maintaining fault tolerance proved crucial for their operations.
Similarly, Pinterest adopted Ray Data to overcome significant bottlenecks in their data loading and preprocessing pipeline for training large-scale recommender models. Pinterest's initial setup employed a traditional single-node PyTorch configuration with standard data loaders, where data loading, preprocessing, and model training occurred on the same CPU-GPU nodes. This configuration had fixed CPU-to-GPU ratios and could not meet their high data throughput demands, achieving only 260,000 examples per second against a target of 500,000 examples per second. By switching to Ray Data and distributing data loading and preprocessing across multiple CPU nodes independently from GPU nodes, they successfully reached their throughput goals, while processing hundreds of terabytes of data across over 100,000 files.
Streamlining LLM Data Preparation with Data Prep Kit
Data Prep Kit (DPK) addresses a critical gap in the LLM development workflow by providing a unified, scalable solution for data preparation. Unlike existing tools that often focus on specific data types or lack scalability, DPK's modular architecture enables teams to handle diverse data preparation tasks efficiently, from single machines to large clusters. DPK also provides runtime flexibility, enabling users to choose the most appropriate computing environment for their needs, whether it's a local machine or a large-scale cluster. At its core, DPK comprises three main components:
Data Access: This module manages input/output operations across different storage systems, providing storage-independent data processing. It allows for seamless integration with various data sources without the burden of underlying storage complexities.
Transformation Modules: DPK offers a set of pre-built, reusable transforms for common operations like cleaning and deduplication. By leveraging these ready-made transforms, teams can expedite the data preparation process while maintaining high standards of data quality.
Runtime Environment: Managing the execution environment and scaling is simplified through DPK's support for multiple runtimes, with Ray's distributed computing capabilities being the primary one. This flexibility allows teams to scale from development to production environments without significant code changes.
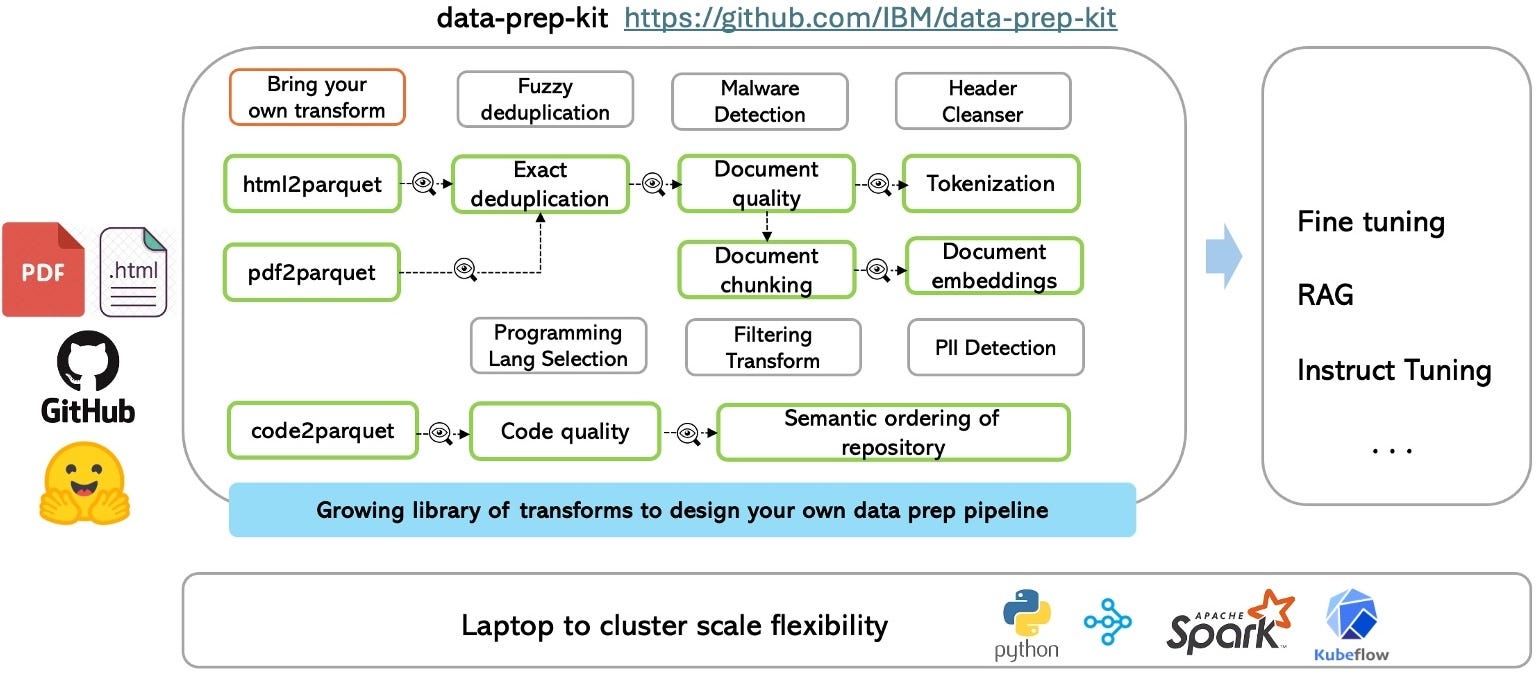
The toolkit's extensibility is particularly valuable for AI teams. Developers can create and integrate custom data transforms without deep expertise in distributed computing, thanks to DPK's abstraction layer over frameworks like Ray and Spark. This flexibility, combined with built-in automation features through Kubeflow Pipelines integration, significantly reduces the engineering effort required for managing data preparation workflows.
Early evidence from IBM's Granite models deployment demonstrates DPK's effectiveness in production environments. Performance tests on clusters up to 40 nodes show strong scalability, with significant reductions in execution time per terabyte as computational resources increase. The toolkit maintains consistent performance across varying data sizes, making it a reliable choice for teams working with large-scale datasets.
Future Directions and Practical Considerations
Ray Data primarily targets tasks with sub-second latency rather than applications requiring sub-millisecond latency. Looking ahead, the Ray Data team sees opportunities for dynamic query planning and autoscaling capabilities that could automatically reconfigure applications and resize clusters based on workload demands.
DPK faces its own set of challenges, primarily in its current limited support for data modalities beyond code and natural language. Some data transforms may show performance plateaus at higher scales, particularly for complex operations like language identification. The roadmap for DPK includes expanding support for additional data modalities (including images, speech, and multimodal data), developing new specialized transforms, and enhancing automation and monitoring capabilities.
While these projects serve different purposes—Ray Data focuses on efficient multimodal data processing, while DPK is tailored for LLM-specific workflows—they share a common objective: improving the efficiency and scalability of data workflows for modern AI applications. As both projects continue to evolve and address their current limitations, they represent valuable additions to the AI practitioner's toolkit.
With data processing transitioning from SQL-centric to AI-centric approaches, organizations must fundamentally rethink their data infrastructure. This shift brings new challenges, particularly as organizations deal with increasingly sophisticated data types like video, which demands both specialized processing capabilities and efficient resource utilization across CPUs and GPUs. Ultimate success in the coming years will depend on building flexible, scalable infrastructures that can support dynamic pipeline optimization, automated quality assessment, and sophisticated data curation. The future of Generative AI applications lies not just in model architecture improvements, but in our ability to build and maintain robust data processing systems that can adapt to evolving data types, quality requirements, and computational demands.
Happy Thanksgiving 🎊

{kind=link}
{kind=link}
{kind=link}
{kind=link}
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.