

A Comprehensive Approach to Using LLMs

From Proprietary to Open Source to Fleets of Custom LLMs
Large language models (LLMs) have proven to be powerful tools for me over the last year. LLMs can be used to build a wide range of applications, from chatbots and content generators to coding assistants and question answering systems. After discussing the journey of building applications with friends, I want to share the typical progression most LLM enthusiasts experience when diving into the rapidly changing and fascinating world of LLMs.
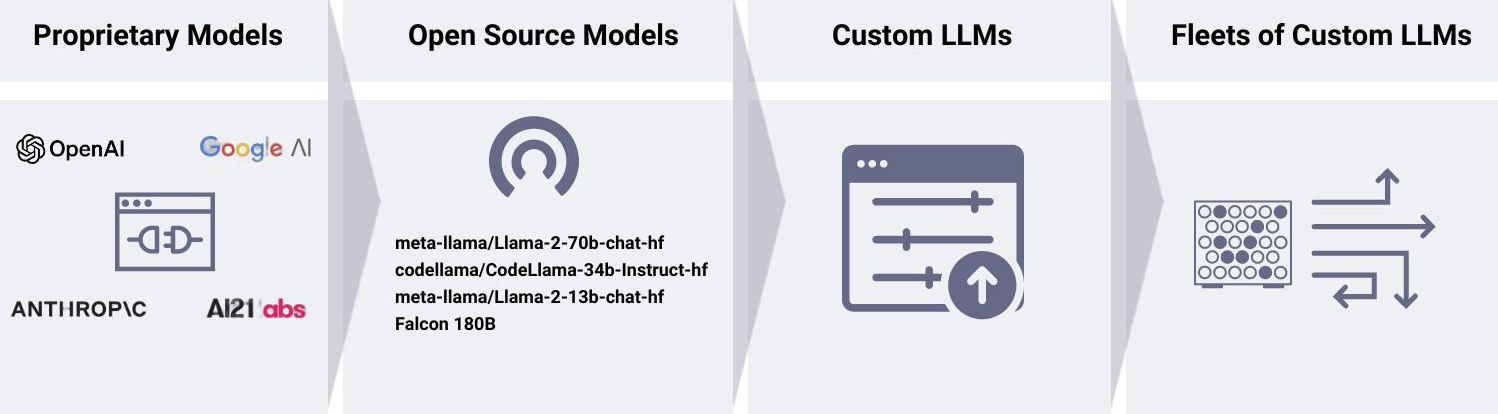
Stage 1: Start with proprietary models available through a public API.
The most common way to start building applications with LLMs is to use a proprietary model available through a public API. In my case this meant the OpenAI models GPT-4 and GPT-3.5. This is a relatively easy and straightforward approach, as it does not require any expertise in training or deploying LLMs. At this stage, you play around with LLM orchestration tools (my current favorite is Haystack) and build your first retrieval-augmented generation (RAG) application.
Stage 2: Explore open source LLM alternatives.
While proprietary LLMs are easy to use, they can be slow, unstable, and expensive, especially as you scale your usage. For these reasons, many developers are now turning to open source LLMs. Open source LLMs are freely available to use and modify, and they can be deployed on your own infrastructure. This gives you more control over the cost, latency, and security of your applications.
My most recent experience with the Llama family of LLMs came through Anyscale endpoints. Despite their compact nature, these models can hold their ground. Llama models demand more explicit instructions, but that was a minor trade-off for their speed, stability, and remarkably affordable price—Anyscale charges just $1 for a million tokens.
Since these models are open source, why not just host them yourself? Hosting your own version of Llama may seem tempting, but it's not necessarily cost-efficient. Anyscale, for instance, invests significant intellectual property in ensuring optimal cost efficiency. Managing costs for LLM inference isn't straightforward; it permeates every layer of the tech stack. It demands mastery over advanced GPU and model optimization techniques, such as PagedAttention and tensor parallelism. Additionally, you'd need to harness strategies like continuous batching, adeptly scale model replicas for fluctuating loads, and strategically select the most budget-friendly hardware and GPUs across diverse regions or even different cloud services. Given these complexities, I feel that utilizing Anyscale endpoints emerges as a practical and efficient choice.
Currently, my toolkit comprises a mix of open-source LLMs via Anyscale endpoints, supplemented by occasional proprietary models from OpenAI.
Stage 3: Create a custom LLM.
Custom LLMs offer several advantages over general-purpose models, especially when you have specific requirements for your application, such as enhanced accuracy or performance for a particular task or domain. Teams often opt for custom LLMs due to concerns related to privacy, security, and the desire for more control. Additionally, custom LLMs can be more compact than general models, offering advantages in cost, speed, and precision.
Expanding the notion of "custom LLM" to encompass retrieval-augmented generation can result in applications that are sharper, faster, and more cost-effective. However, these models demand intensive calibration to achieve their potential. Though smaller models may not perform optimally at first, they can benefit from fine-tuning techniques and domain-specific data using RAG. As I noted in my previous post, navigating the many techniques for customizing LLMs can be challenging, but the goal is to refine models for specific functions.
Anyscale endpoints, leveraging the OpenAI SDK, offer a streamlined process for this endeavor. They simplify the complexities of fine-tuning, from scheduling jobs to optimizing hyperparameters. Once the tuning is complete, Anyscale sends an email notification and your model becomes available for serving. For those venturing into RAG, a robust foundation like Ray is crucial to conducting experiments that produce an optimal RAG setup.
Stage 4: Deploy, use, and manage multiple custom LLMs.
A single custom LLM will likely be insufficient. Different tasks or projects often require their own distinct LLMs. This is driven by a variety of factors, including cost considerations, the pursuit of speed, the need for greater control, and the desire for pinpoint accuracy.

Indeed some applications require multiple custom LLMs to maximize performance and enhance the user experience. A single LLM cannot always meet all of an application's diverse needs. For instance, the Anyscale Doctor, a coding assistant discussed at the Ray Summit, epitomizes this. To address the knowledge gaps inherent in LLMs, a retrieval-augmented generation application was essential. Additionally, using a suite of LLMs allowed the developers to segment tasks, optimizing each and selecting the ideal LLM for specific tasks. An intelligent routing mechanism ensured that the correct LLM was chosen for each task. This multifaceted approach, integrating several LLMs and RAG applications, demanded a robust serving infrastructure, which was achieved through Anyscale endpoints.
Closing Thoughts: Security and Governance considerations.
Building applications with LLMs can be a complex and challenging process. The journey is as much about exploration as it is about optimization and evolution. You have to balance between understanding the tools available, pushing their boundaries, and crafting solutions that are both effective and efficient.
Regardless of which stage you resonate with, an overarching concern permeates them all: the imperative of securing data and intellectual property. In some cases, a standard API may not meet your needs, especially when you're dealing with sensitive data or you're in need of enhanced customization.
In response to these challenges, Anyscale's introduction of private endpoints presents a compelling option. These endpoints empower developers to deploy the Anyscale backend, encompassing various LLMs, within dedicated cloud accounts. Not only does this bolster privacy, but it also enhances flexibility and provides unmatched control over the infrastructure. While numerous LLM APIs exist in the market, none present such a unique blend of advantages. With Anyscale private endpoints, users enjoy the ease of a recognizable API interface, supported by a formidable and scalable backend. Moreover, it affords an exceptional degree of customizability and control, mirroring the experience of operating a personal infrastructure.
Data Exchange Podcast
Trends in Data Management: From Source to BI and Generative AI. Sudhir Hasbe, the Chief Product Officer at Neo4j, has been a prominent technical and product leader in the data management sector for many years.
Navigating the Generative AI Landscape. Christopher Nguyen, CEO of Aitomatic, is also the organizer of the K1st Symposium scheduled to be held at Stanford next week.
Open Source Principles in Foundation Models
The launch of Mistral 7B prompted me to reflect on the concept of open source in relation to Large language Models (LLMs). In essence, an open source LLM is a model whose code is publicly available under an open source license, allowing anyone to use, modify, and distribute the model. Open source machine learning models are typically accompanied by comprehensive documentation that provides insights into the model's architecture, training methodologies, weights, parameters, and the datasets used for training and evaluation, enabling a deeper understanding of the model's design and functionality.
The appropriate open source license is contingent upon your specific use case. It is preferable for the LLM to be distributed under one of several permissive licenses, such as the MIT License, Apache License 2.0, or the BSD 3-Clause License. Assuming a permissive license is used, an open source LLM is an amalgamation of several crucial components that accompanies its release:

Training Data: Detailed information, or ideally access, to the datasets on which the model was trained allows for insights into the diversity, representativeness, and potential biases inherent in the data.
Training Code: The program or script used to train a machine learning model. It includes the algorithm used, the loss function, optimization method, and other details about how the model is trained on the training data.
Model Architecture: This the blueprint of a machine learning model, defining the layers, nodes, and connections between them. It determines how the model processes input data and makes predictions or classifications.
Model Weights and Parameters: These are the learned values that a model uses to make predictions. They are crucial for utilizing the pre-trained model, as they determine how the model responds to new input.
Hyperparameters: These are the settings that control the learning process of a machine learning model. They are not part of the model itself, but they have a significant impact on the model's performance. Some common hyperparameters include learning rate, batch size, and regularization strength.
Preprocessing and Evaluation Code: The code used to prepare input data and evaluate model performance. These items ensure that users can correctly format their data and understand how well the model is likely to perform on new data.
Documentation: Comprehensive and informative instructions on how to use the model, including the training process, dependencies, and requirements.
Detailed Training Setup and Configuration: Information on the training setup allowing for accurate reproduction of the training environment.
Open source LLMs have proven to be capable and viable options for a range of applications and tasks, providing additional benefits such as more control over deployment options and settings. However, the top-tier open source foundation models still demand significant resources for training, with a majority originating from a select group of companies, like Meta. There's a risk that future versions of these foundation models will come with restrictive licenses, so we definitely need a broader range of suppliers of open source foundation models.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, or Pebble, and Post. This newsletter is produced by Gradient Flow.
Where in your framework would you put enterprise software like Writer.com, which at its top level of service will fine-tune a model for you and make it accessible through their UX, which is built with the marketing industry in mind?