

7 Must-Have Features for Crafting Custom LLMs

Keys to a Robust Fleet of Custom LLMs
The rising popularity of Generative AI is driving companies to adopt custom large language models (LLMs) to address concerns about intellectual property, and data security and privacy. Custom LLMs can safeguard proprietary data while also meeting specific needs, delivering enhanced performance and accuracy for improved user experiences and operations. Tailoring these models to specific requirements ensures optimization in terms of size, speed, and precision, which can lead to long-term cost savings.
Imagine a multifaceted LLM environment within a company, with one LLM focused on precision medical diagnoses, another streamlining customer interactions with rapid and relevant responses, and a third LLM for internal use. LLMs are not just technological showcases, but a functional necessity that ensures the right custom model is used at the right time.
Navigating the Landscape of Tools for Building Custom LLMs
The growing trend towards custom LLMs has led to an explosion of tools and techniques for their creation and deployment. However, the field is still in its early days, and it can be difficult for teams to evaluate the different options available. Some tools are easy to use, others demand a steeper learning curve, and a handful remain embedded in the research domain.
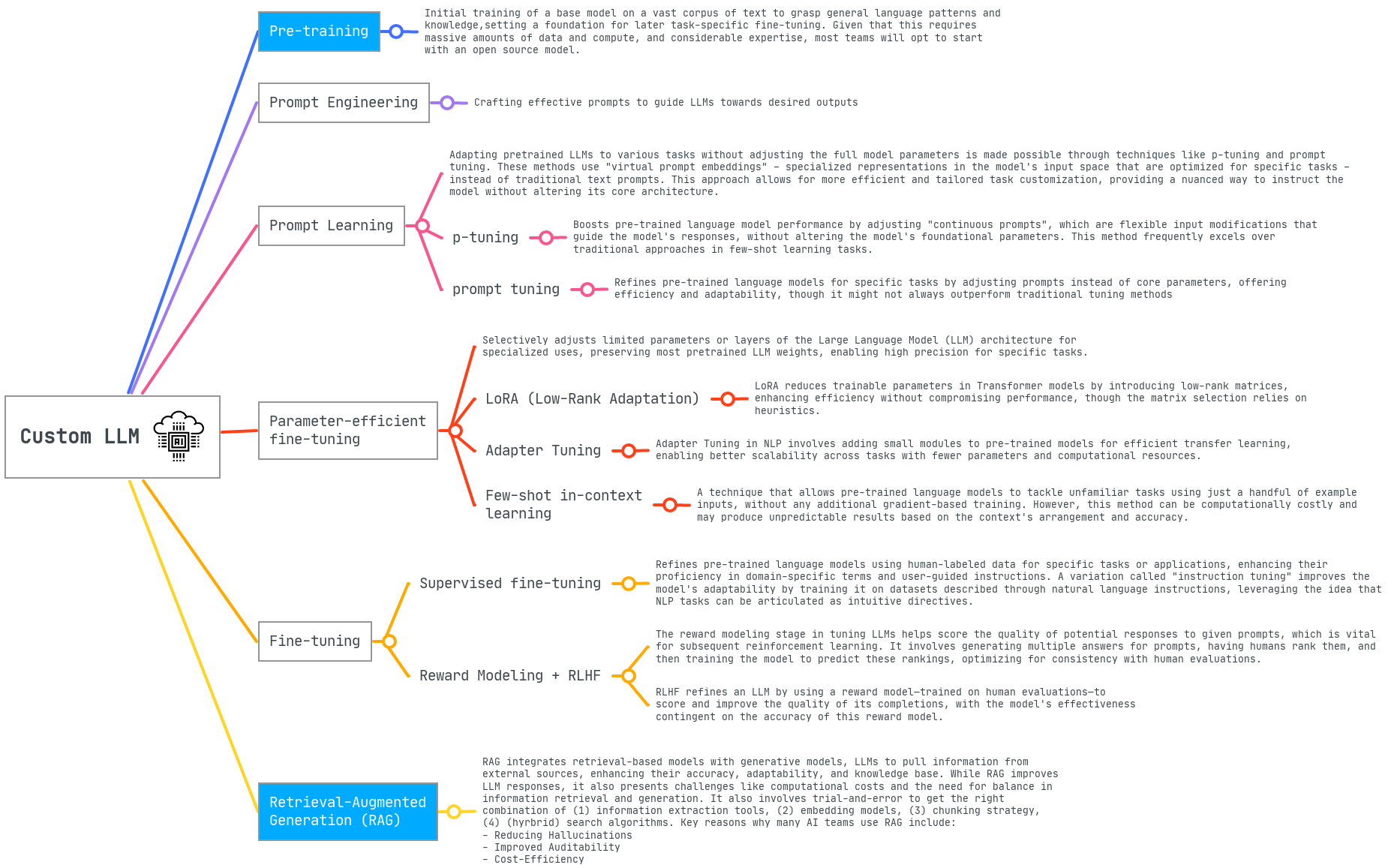
As you search for tools, don't get too bogged down in the details of which techniques to use. I've read articles, watched talks, and spoken with experts to compile a baseline list of assumptions about what you'll need as you start developing and deploying multiple custom LLMs. Customizing an LLM isn't just about technical finesse; it’s about aligning technology with real-world applications.
While many of the elements described below may be familiar to experienced machine learning teams that have worked with multiple models in different contexts, their presentation here highlights the unique challenges and potential of foundation models.
Versatile and Adaptive Tuning Toolkit: The evolving nature of business requirements demands flexible customization techniques for optimal outcomes. Ideally, a unified platform would let users effortlessly test and integrate various methods without juggling multiple tools. Just as using separate machine learning libraries for different models is inefficient, depending on multiple tools for customizing LLMs is suboptimal. As businesses may require diverse LLMs, each use case typically needs a unique blend of techniques.
Human-Integrated Customization: Optimal customization of LLMs often requires integrating human expertise into the development workflow. This includes tasks such as data labeling, crafting prompts, and ensuring the model's output is accurate. While human involvement can extend iteration cycles, it is invaluable for safety and precision. When testing LLMs with users, it is recommended to pair them with human oversight to mitigate potential discrepancies in the output.
Data Augmentation and Synthesis: When customizing an LLM, sometimes your existing dataset may not be diverse or robust enough. Ideally your platform can assist in generating synthetic examples, or augmenting existing ones.
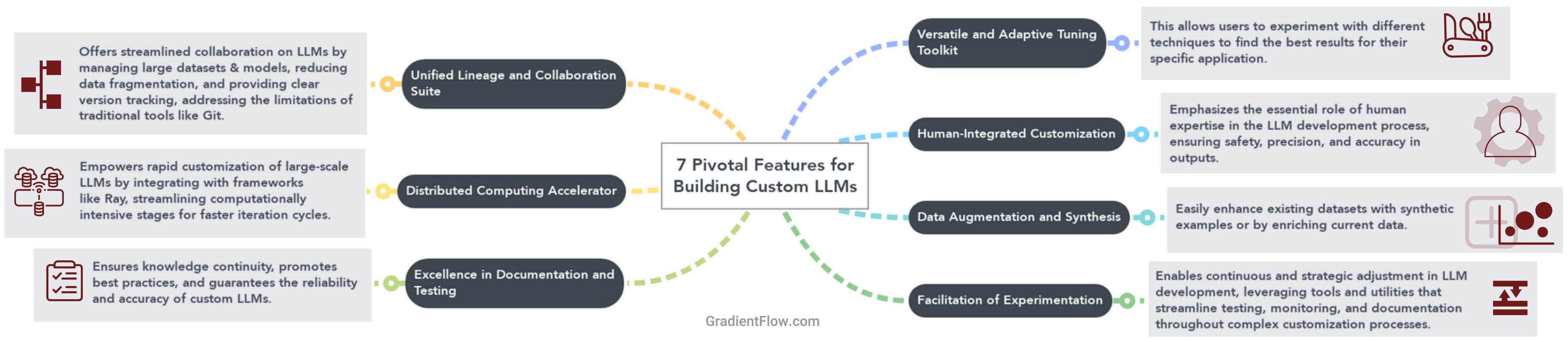
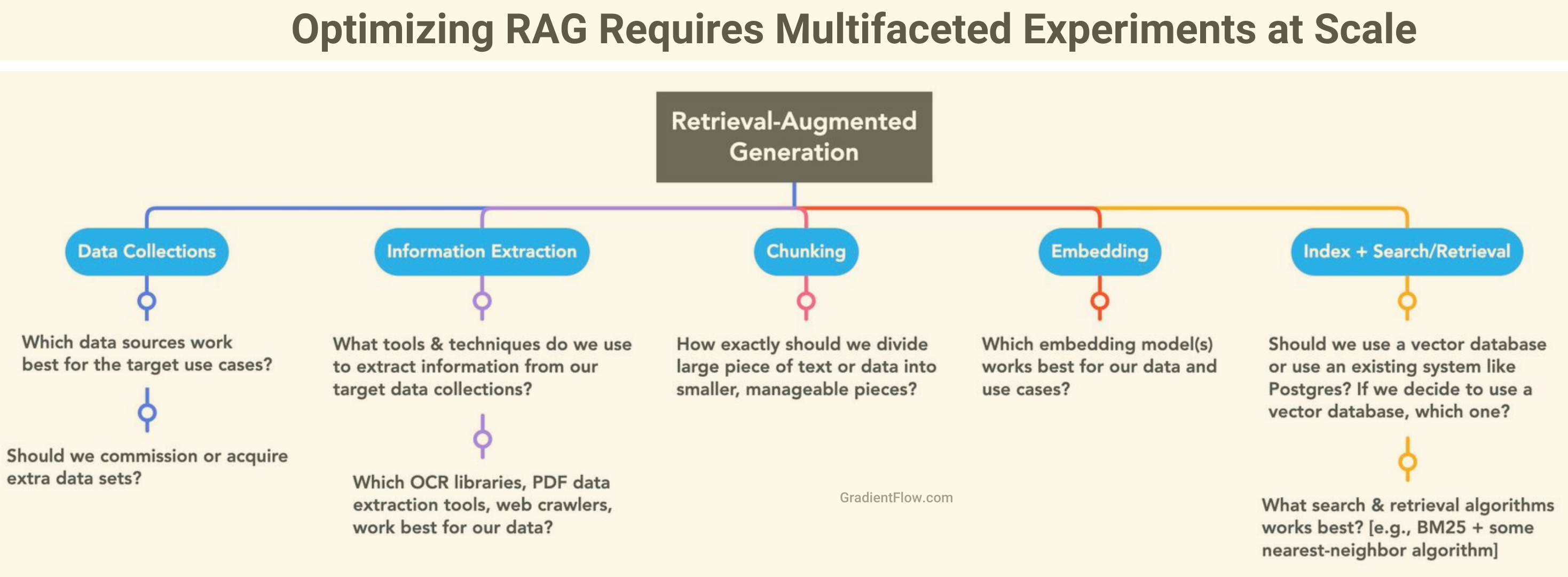
Facilitation of Experimentation: Customizing LLMs demands continuous and strategic experimentation at each phase. Open-source tools like MLflow and Aim are widely used for managing and documenting ML experiments. Teams dedicated to developing bespoke LLMs will benefit from similar utilities, such as the ability to test, monitor, and share prompts effortlessly. Applications employing retrieval-augmented generation (RAG) underscore the complexity of experimentation; they necessitate tuning across data collections, model embeddings, chunking strategies, information extraction tools, and hybrid/vector search algorithms. Based on my experience, you’ll need to explore various combinations of these elements before deploying your RAG-based system.
Distributed Computing Accelerator: Harnessing the power of distributed computing is crucial given the immense scale of building custom LLMs. By utilizing tools integrated with frameworks like Ray, you can significantly accelerate experiment cycles when testing various LLM tuning techniques and RAG setups. While human-involved processes will still introduce delays, the computationally intensive stages in your customization pipeline will be streamlined and you can iterate faster.
Unified Lineage and Collaboration Suite: Collaborating on LLMs often requires managing vast datasets and large models. Traditional tools like Git were not designed for this, so engineers and researchers often create multiple subsets of the data for quick model testing, analysis, and iterative experiments. In refining LLMs, it's typical to introduce gradual data modifications or updates. This results in nearly identical data replicas across teams, consuming extra storage and complicating version tracking. New tools like XetHub are tailored to simplify collaboration in this space, reducing data fragmentation and ensuring clarity in lineage.
Excellence in Documentation and Testing: Documentation serves as more than just a procedural requirement. It is a guiding light for best practices, insights, regulatory compliance, and risk mitigation. By maintaining comprehensive records, we ensure knowledge continuity, promote a culture of informed experimentation, and pave the way for colleagues to build upon prior experiments and discoveries. Robust testing is essential to ensuring alignment, accuracy, and reliability of custom LLMs.
Closing Thoughts
It's easy to be overwhelmed by the myriad of techniques and tools for fine tuning LLMs. The ultimate goal is clear: craft custom LLMs tailored for specific tasks. We need tools that streamline the cycle of pre-training, customizing, optimizing, and deploying these models, adapting them as new data or better strategies emerge.
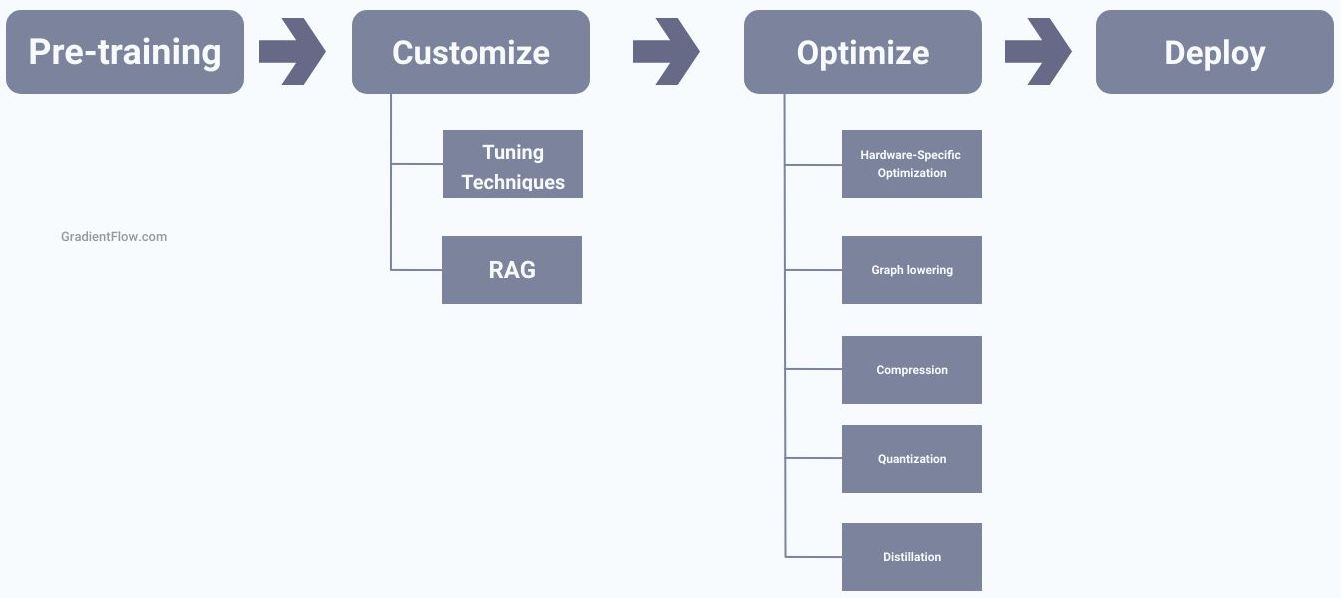
There are currently many different ways to customize LLMs, but future tools are likely to automate some of these processes. Imagine a system where users can input their data and specific requirements to receive a suggested workflow for creating a custom LLM. However, it is important to note that automation has its limits. The complexity of datasets and synthetic data pipelines still requires human intervention, which can slow down the customization process.
It's also crucial to acknowledge the current limitations of LLMs. Among the chief concerns are hallucination, biases, reasoning errors, susceptibility to attacks—including prompt injection and data poisoning—and latency issues in real-time applications. For now, LLMs are best suited for low-stakes tasks, acting as suggestive aids paired with human supervision, rather than full-fledged autonomous systems.

Data Exchange Podcast
The Implications of Generative AI for Cybersecurity. Casey Ellis is Founder/Chair/CTO of Bugcrowd, a Crowdsourced Cybersecurity Platform.
AI and the Future of Speech Technologies. I discussed the state of AI for speech and audio, including trends in Generative AI, with Yishay Carmiel, the CEO of Meaning.
2023 AI Conference
The AI Conference is taking place in San Francisco next week, September 26-27. This in-person, vendor-neutral event offers a deep dive into a vibrant AI community, featuring engaging talks and interactive sessions.
We have a diverse range of sessions that cover both the breadth and depth of AI. You'll hear about the latest research and industry trends from experts at UC Berkeley, Stanford, Google, NVIDIA, Anthropic, Meta, Hugging Face, Anyscale, Cerebras, Stability AI, and many more. Our speakers include creators of some of the most popular services and frameworks in AI today.

The conference will delve into the challenges of productionizing AI, Generative AI and Large Language Models (LLMs). We'll explore alignment and risk mitigation, and gain insights from practitioners across various industries. But we're not just focusing on Generative AI and LLMs. We'll also have talks on computer vision, recommendation systems, and speech technologies.
And if you're interested in the business side of AI, we have you covered. There will be talks on the challenges of harnessing the power of AI, especially as we scale and integrate it into the heart of organizations worldwide. We'll have perspectives from researchers as well as from leading investors and venture capitalists, discussing AI trends and investment strategies.
The conference is also a fantastic networking opportunity. You'll get to meet other members of the AI community, including the speakers at the conference. I can't wait to see you there, to learn, share, and network in this vibrant AI community.
The inaugural AI Conference takes place next week in San Francisco (Sep 26-27).
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, or Pebble, and Post. This newsletter is produced by Gradient Flow.