

Unlocking Business Value by Optimizing AI Workflows

Overcoming AI Scaling Challenges with Ray Compiled Graph
By Ben Lorica and Dean Wampler.
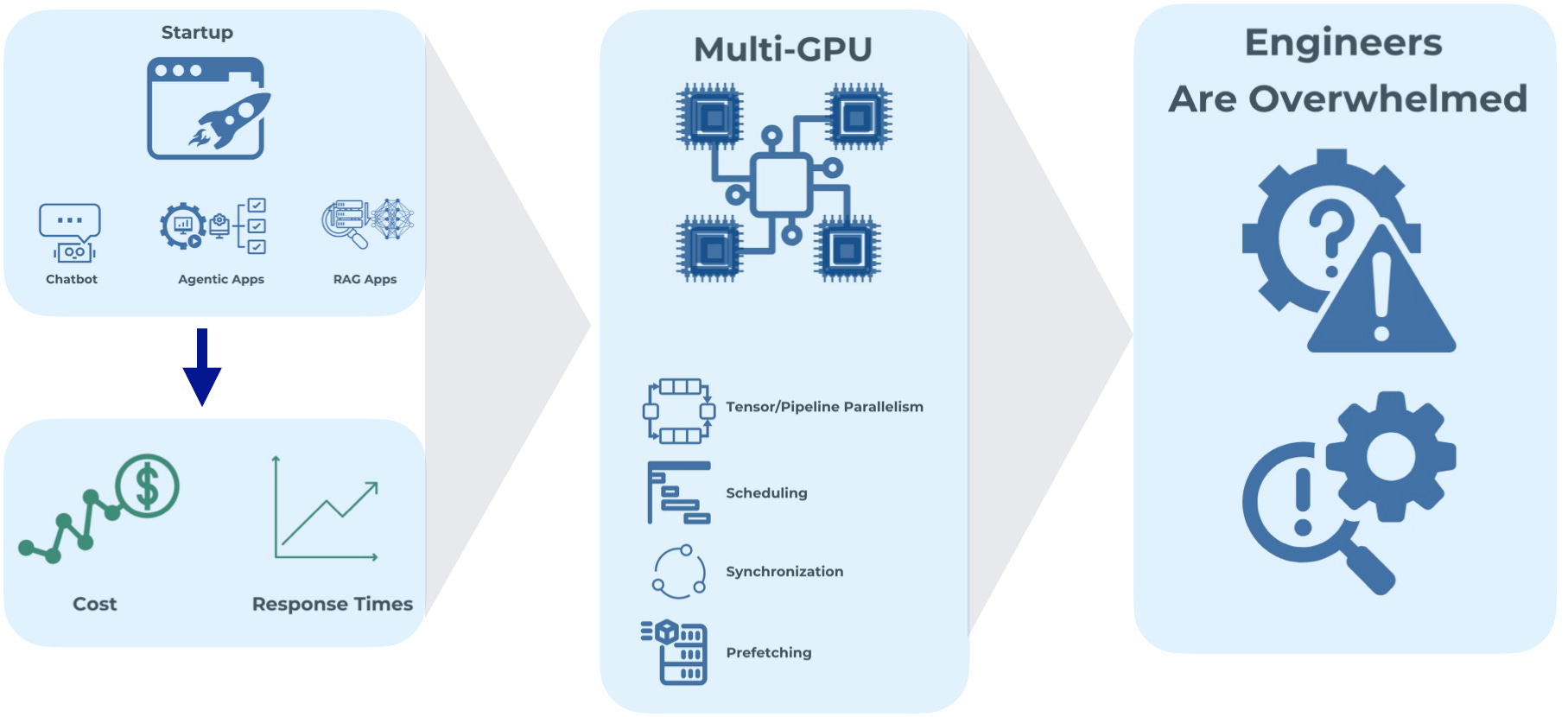
Imagine a startup developing AI-powered customer service chatbots, agentic workflows, or retrieval-augmented generation (RAG) applications. As their user base grows, they suddenly face skyrocketing costs and deteriorating response times. This scenario is playing out across industries as companies grapple with the challenges of scaling AI workloads efficiently. At the recent Ray Summit, it became evident that these challenges are at the forefront of concerns for teams developing AI applications and solutions.
In the era of generative AI, training and inference workloads have become increasingly complex and resource-intensive. Many operations require coordination across multiple GPUs, particularly for large models—such as language models (LLMs)—that cannot fit on a single device. As generative AI gains momentum, efficiently scaling inference workloads has emerged as a significant challenge. Techniques like tensor parallelism and pipeline parallelism, which involve splitting tasks into smaller pieces for simultaneous or sequential processing, are now essential for distributing computations across multiple GPUs.
The importance of maximizing performance in multi-GPU architectures cannot be overstated. Even on single GPUs, the cost of inference overhead is substantial. When scaling to multiple GPUs, these overhead costs can increase disproportionately, often exceeding the simple multiplication of single GPU costs. Consequently, it is crucial that multi-GPU architectures be designed and implemented with the utmost efficiency to minimize these overhead costs and maximize overall performance.
Coordinating tasks across multiple GPUs is like conducting a complex orchestra—every part must work in harmony, and the slightest misstep can throw everything off. This complexity not only consumes valuable engineering time but also increases the risk of costly errors and delays, directly affecting a company's ability to deliver products on time and within budget.

The intricacies of scheduling tasks, ensuring synchronization across devices, and preventing deadlocks demand a deep understanding of distributed systems. As machine learning advances, techniques like pipeline-parallel training and prefetch disaggregation further complicate the process. Prefetching, for instance, proactively retrieves data from remote memory before it's needed, similar to how a CPU's cache operates to reduce latency. While these methods aim to speed up processing, they add layers of complexity to an already intricate system.
The widespread deployment of generative AI models has direct implications for user experience and operational costs, particularly in terms of inference workload efficiency and scalability. Failure to optimize these workloads can lead to increased expenses and reduced competitiveness in the market. The challenges of multi-GPU coordination are thus critical in both training complex models and scaling inference workloads effectively, with financial consequences that can make or break an organization's AI initiatives.
The Shortcomings of Existing Solutions
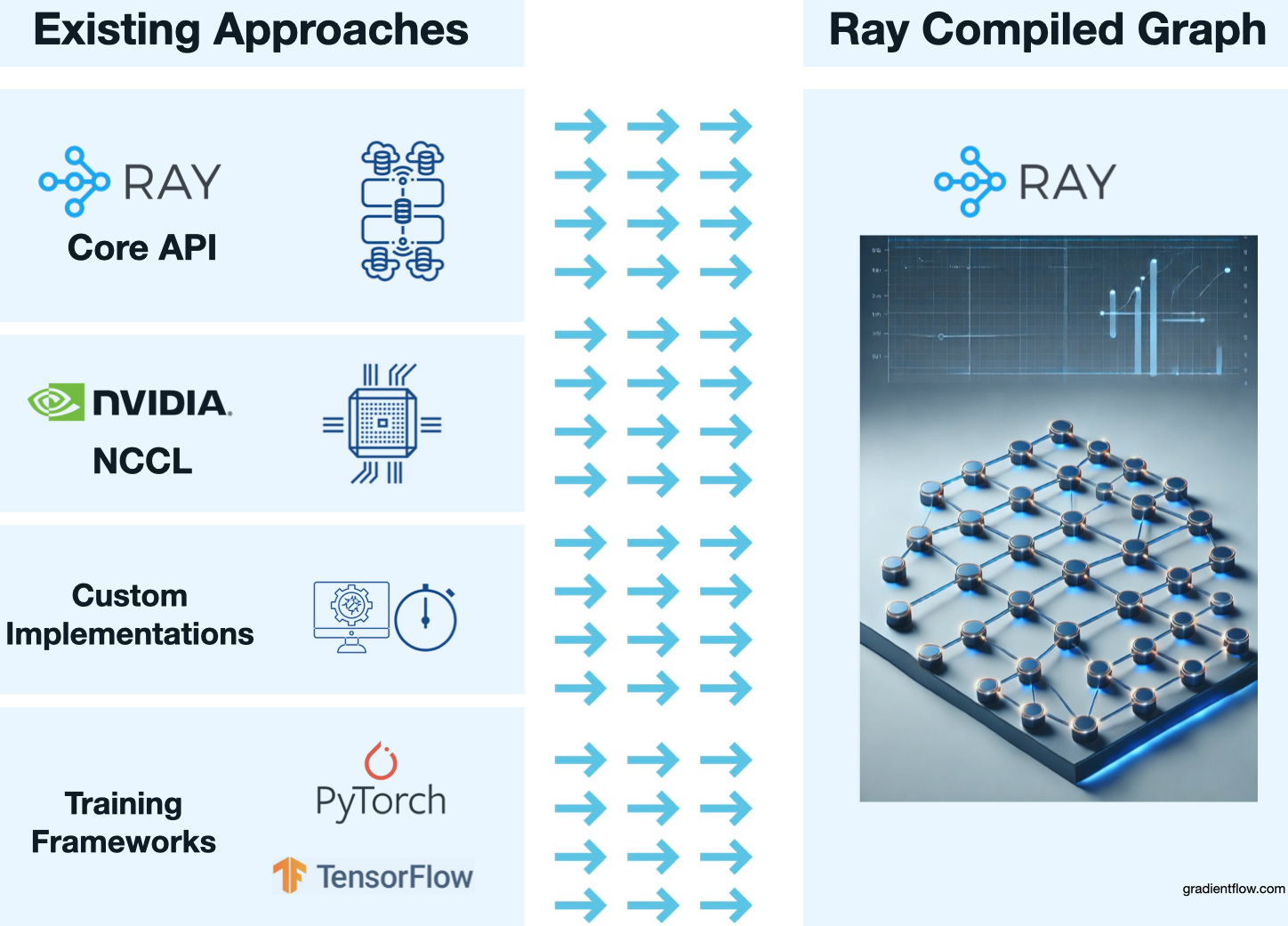
Existing approaches to managing multi-GPU workloads are inadequate for today's challenges. The Ray Core API, for instance, provides a framework for distributed computing but introduces overhead due to dynamic remote procedure calls (RPCs) and memory allocation. While these overheads make sense for general-purpose scaling, they lead to serious performance bottlenecks in multi-GPU scenarios. The dynamic nature of the Ray Core API also makes it difficult to guarantee correctness in large-scale distributed systems. While Ray Core is powerful, its design is not optimized for the specific demands of large, multi-GPU models in both training and inference contexts.
Some developers resort to building custom implementations to handle GPU communication and coordination. This approach is time-consuming and error-prone, requiring specialized expertise in distributed systems—a resource not readily available to many AI teams. Moreover, these custom solutions often lack performance optimizations and add complexity to development.
GPU communication libraries like NVIDIA's NCCL offer low-level primitives for GPU communication but lack higher-level abstractions necessary for complex workflows. They require developers to manually synchronize processes, increasing complexity and the likelihood of mistakes. Similarly, existing training frameworks often assume homogeneous GPU setups, making it challenging to efficiently utilize clusters with different types of GPUs—a common scenario where hardware varies in capabilities. This assumption limits resource utilization and can hinder performance when using different types of GPUs together, affecting both training and inference workloads.
The common thread among these solutions is that they introduce significant complexity and overhead. Developers must grapple with intricate details of GPU coordination, which not only leads to suboptimal performance and increased development time but also delays product deployment and raises operational costs. Implementing advanced parallelism strategies like pipeline parallelism requires substantial effort, and challenges with heterogeneous hardware setups remain unresolved. For instance, an AI team might spend months developing a custom GPU coordination system, only to find it doesn't scale efficiently with their growing datasets.
Ray Compiled Graph: A Compelling Solution with Tangible Benefits
One of the standout announcements at Ray Summit 2024 was the introduction of Ray Compiled Graph (RCG), a new system designed to tackle the challenges faced by AI teams dealing with multi-GPU workloads. RCG builds on top of the existing Ray Core API but introduces a compiled execution model that dramatically reduces the overhead associated with dynamic task creation and RPCs.
The following diagrams compare the two. Note the lines between the Driver and other modules that disappear in the compiled graph diagram. This remote communication with the driver is a significant source of overhead. When it can be removed, it dramatically reduces the overhead and thereby improves performance.

RCG allows developers to represent workloads as a directed acyclic graph (DAG)—essentially, a flowchart of tasks with explicit data dependencies. This high-level representation is then compiled into an optimized execution plan, executed across a GPU cluster. By handling the complexities of scheduling, synchronization, and communication automatically, RCG significantly reduces the manual coordination required from developers.
Key advantages and tangible benefits of RCG include:
Optimized Scheduling and Execution. RCG analyzes the DAG structure to efficiently schedule tasks across GPUs, optimizing for data locality and reducing communication overhead. This leads to more efficient use of GPU resources and faster execution times. In large language model (LLM) inference tasks, RCG has demonstrated improvements of up to 10–15% in throughput and latency compared to custom implementations—significant gains for applications where speed and efficiency directly impact user experience and operational costs.
Simplified Implementation of Advanced Parallelism Strategies. RCG makes it easier to implement complex parallelism patterns like tensor parallelism and pipeline parallelism, which are essential for scaling up the training and inference of large models. Complex techniques like pipeline parallelism can be implemented in under 100 lines of code, drastically reducing development effort and complexity. This allows teams to experiment with and deploy different strategies without the steep learning curve or extensive coding previously required.

Automatic Synchronization and Communication. It manages inter-GPU communication and synchronization automatically, freeing developers from manual coordination. Teams can now focus on model development rather than infrastructure complexities.
Integration with Existing Libraries. RCG seamlessly integrates with familiar tools like PyTorch and NVIDIA's NCCL, allowing developers to adopt it without overhauling their existing workflows or learning new tools. This compatibility complements the familiar Ray Core API while providing the performance improvements of compiled execution.
Flexibility and Extensibility. Designed to be hardware-agnostic, RCG adapts to various hardware environments, including heterogeneous GPU clusters. By being aware of GPU heterogeneity, RCG significantly improves utilization, ensuring all available resources are leveraged efficiently. This is crucial in environments where hardware diversity is common, contributing to cost savings and improved performance in both training and inference workloads.
Improved Debugging and Maintenance. The ability to switch between compiled and non-compiled execution models enhances debugging, making it easier to identify and resolve issues. This flexibility simplifies development and maintenance, reducing troubleshooting time and increasing productivity.
RCG not only accelerates execution times but also reduces development overhead, allowing teams to focus on innovation rather than infrastructure challenges. Whether in training complex models or scaling inference workloads to meet growing demands, RCG provides tangible benefits that can lead to cost savings and improved competitiveness in the market.
Why not always compile the graphs? RCG is designed for scenarios where the graph of computation is effectively static, as in AI model training and inference scenarios. For the general case, where more dynamic flexibility is required, non-compiled graphs, the “classic” scenario provided by the Ray Core API, is the right choice.
Next Steps for Ray Compiled Graph
Ray Compiled Graph is currently in alpha/preview status. Although initial results are promising, several areas require improvement. The system's focus has primarily been on PyTorch and NVIDIA hardware, but there is potential to expand support to other machine learning frameworks and hardware platforms. Stability is another key area, with a beta release expected to enhance the robustness and performance of RCG for a wider range of use cases.
To make RCG more user-friendly, efforts are underway to improve developer interfaces and debugging tools. Debugging in a compiled environment can be more challenging than in a dynamic one, so providing better tools for developers will be crucial to RCG's long-term success. Additionally, RCG's flexibility will be enhanced by making it more pluggable and adaptable to various hardware environments, including non-NVIDIA platforms.
While it is still a work in progress, with continued development and community support, RCG could streamline AI workflows and better leverage hardware resources. Its success will depend on addressing current limitations and fostering widespread adoption.
Ray continues to impress us with its enduring core concepts, which deliver intuitive yet powerful features. Moreover, its support for increasingly complex optimizations has not only widened Ray's range of applications but also significantly improved its performance metrics.
Conclusion: Simplifying the Path Forward in AI Development
Efficiently managing multi-GPU workloads poses significant challenges for AI teams seeking to leverage modern foundation models. As generative AI adoption accelerates, scaling inference workloads efficiently and cost-effectively becomes increasingly important. Ray Compiled Graph offers a practical solution by simplifying multi-GPU coordination and optimizing performance.
By introducing a compiled execution model, RCG allows developers to focus on building innovative AI applications rather than managing hardware complexities. It abstracts GPU coordination, reduces development overhead, and enhances performance—all while maintaining the familiar programming model of Ray Core. This approach benefits both training complex models and scaling inference workloads to meet growing demands without proportionally increasing costs.
As RCG matures, it has the potential to deliver substantial business value by reducing operational costs, accelerating time-to-market, and enabling better utilization of resources. Teams adopting RCG will be better positioned to innovate rapidly, satisfy user demands, and maintain a competitive edge in the rapidly evolving AI landscape.

NODES 2024 is a free online conference showcasing the latest in graph-based AI and GenAI. I'm excited to be the keynote speaker—join me online!
Data Exchange Podcast
The Security Debate: How Safe is Open-Source Software? Mars Lan from Metaphor discusses security challenges in open source software and the role of AI in modern application security. The conversation highlights Metaphor's innovative use of interconnected graphs, including technical, business, and social graphs, as a prime example of GraphRAG in production.
The AI-Driven Transformation of Programming and Data Analytics. Matt Welsh joins us to discuss the revolutionary impact of AI on programming and the challenges in trusting and verifying AI-generated code.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Twitter, Reddit, Mastodon, or TikTok. This newsletter is produced by Gradient Flow.