

The Future of Prompt Engineering

What I Talk About When I Talk About Prompting
In recent months, my approach to constructing NLP pipelines and applications has shifted from integrating various libraries to using large language models (LLMs) via their APIs. This transition has resulted in a slight increase in latency and cost (due to the replacement of free libraries), but it has also delivered significant benefits in terms of accuracy and user-friendliness. I believe that future NLP pipelines will be composed of multiple LLMs, enabling developers to select the most appropriate model for their specific task and application. The choice of LLMs is influenced by a number of factors, including the need for domain-specific models at certain stages of a pipeline, as well as performance and cost considerations tailored to specific tasks.

With this approach to building NLP pipelines, it becomes crucial to effectively compose, refine, and test prompts. Prompt engineering is the art of crafting effective input prompts to elicit the desired output from foundation models. It’s the process of crafting prompts that effectively leverage the capabilities of existing generative AI models to accomplish specific objectives. Often, this entails incorporating the task's objective that the LLM is intended to achieve within the input, such as "provide a summary of this text".
Prompt engineering tools need to be flexible enough to accommodate a variety of use cases, transparent so that users can understand how they work, resilient to errors, compatible with a wide range of foundation models, and user-friendly so that anyone can use them. Let me start with a few high-level observations:
As LLMs rapidly evolve, a standardized approach to prompt engineering is essential for fostering collaboration and streamlining the sharing of models and data.
Looking beyond text and LLMs, users need to be able to interact with foundational models across a variety of modalities. An effective prompt engineering tool must be able to handle a variety of data types, such as text, images, and audio, and be robust to noisy data, incomplete data, and other data-related issues.
To facilitate collaboration and seamless sharing of models and data, prompt engineering tools must be interoperable, ensuring their compatibility with a variety of tools and platforms.
In the long run, it is important for prompt engineering tools to be transparent. This entails ensuring that these tools aid users in comprehending a model's functionality, its decision-making mechanisms, and the methods by which it generates output. This will allow users to understand how their AI tools work and to make informed decisions about their use.
I decided to compile an ambitious assortment of features that could potentially improve and optimize prompt engineering for teams. Given my current focus on working with LLMs and NLP pipelines, this list may skew towards text-based applications.

It turns out that a diverse range of prompt engineering tools—with varying degrees of maturity—already exists to help engineers and researchers craft and manage prompts effectively. The following diagram offers a representative sample of such tools.
Prompt Inspiration: Tools for generating diverse prompts and sparking creativity.
Prompt Organization: Tools for managing prompts with features like folders, versioning, and team support.
Prompt Optimization: Tools to test and improve prompts for high-quality results.
AI Art Creation: Tools for crafting unique AI-generated art using prompts.
Metadata Visualization: Tools to log, visualize, and analyze AI metadata for insights. Metadata tools are particularly crucial for teams that integrate and chain together multiple services to build AI applications.
Multi-Model Interaction: Tools for integrating and interacting with multiple AI models and external services.

Some people believe that the emphasis on prompt engineering tools is misplaced, given that we are currently in a transitional phase. As LLMs continue to improve, they will not only predict words more accurately, but also become more adept at following instructions. Consequently, even simple directives will likely produce satisfactory results, thereby diminishing the significance of meticulously crafted text prompts. Despite these advancements, I maintain that formulating and managing clear, concise instructions will continue to be crucial. Just as in human communication, where different instructions can lead to different outcomes, the same will be true for large language models.
As we move forward, building software systems with LLMs and other Generative Models will primarily involve writing text instructions. Given the importance of crafting these instructions, it is likely that we will need a subset of the features listed above. However, I believe that it is only a matter of time before many of these features are integrated into existing tools. Consequently, apart from LangChain and AimStack (AI metadata tracking tool), I have not yet integrated other prompt engineering and management solutions into my personal toolkit.

Spotlight
The LLM Engine for Rapidly Customizing Models. Lamini is offering developers a user-friendly LLM engine, empowering them to train top-notch language models effortlessly with minimal code. They make it easy for developers to produce custom models on their own data, giving teams the freedom to tailor their solutions to unique needs. Learn more about their advanced optimizations and intuitive interface, and secure your early access to their comprehensive LLM training module.
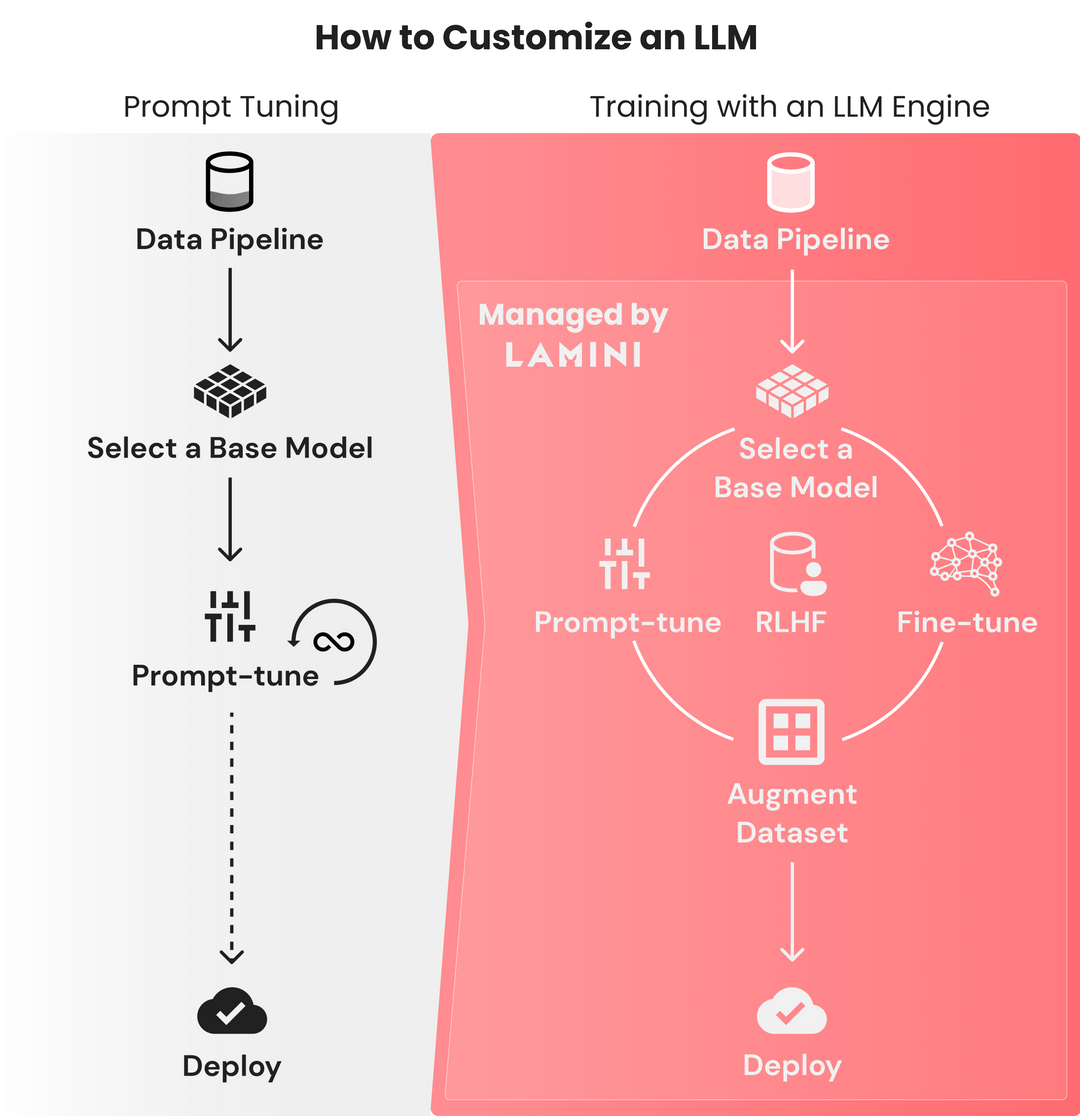
Lamini: the LLM Engine for Rapidly Customizing Models RATH. A new open-source tool for data exploration and visualization, providing automated exploratory data analysis and insightful visualizations. RATH discovers patterns and insights while offering advanced features such as autovis, causal discovery, and GPT integration for a streamlined data analysis experience.
ViperGPT. This is a very interesting open-source project for programmatic composition of specialized vision, language, math, and logic functions. ViperGPT simplifies complex visual queries by leveraging code-generation models to combine vision and language models, producing state-of-the-art results in various visual tasks.
How to turbocharge embeddings. Generating embeddings from documents is a critical step for LLM workflows. This tutorial demonstrates how to use Ray Data, a distributed data processing system within the Ray framework, to efficiently generate and store embeddings for 2,000 PDF documents from cloud storage in under 4 minutes, using 20 GPUs. This approach overcomes the limitations of using LangChain with larger corpora, enabling faster development and easy parallelization for scaling LLM applications.


Data Exchange Podcast
AI Metadata. Gev Sogomonian, is the co-author of AimStack – an open-source, self-hosted AI metadata tracking solution. AimStack effectively logs all relevant AI metadata, such as experiments, prompts, and metrics, while delivering a user-friendly interface for in-depth exploration and data analysis. Additionally, it features an SDK that allows for efficient programmatic querying of the tracked metadata.
Revolutionizing B2B: Unleashing the Power of AI and Data. Simon Chan is General Partner at Firsthand Alliance, a venture capital fund targeting B2B and enterprise software. We discuss AI, cloud computing, and collaboration tools, and Simon explains the pivotal role Generative AI plays in propelling content creation and innovation throughout a diverse range of industries.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the Ray Summit, the NLP Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, or on Post. This newsletter is produced by Gradient Flow.