

The Convergence of Data, AI, and Agents: Are You Prepared?

Autonomous Agents are Here. What Does It Mean for Your Data?
By Ciro Greco and Ben Lorica.
A striking factoid emerges from Anthropic’s latest Economic Index report: directive AI usage, where users delegate complete tasks to Claude, has surged from 27% to 39% on Claude.ai in just eight months.
Among API customers building production systems, that figure jumps to an overwhelming 77%. This rapid shift from augmentation to automation represents more than a change in user preference; it signals a fundamental mismatch between how AI agents need to operate and how most data infrastructure is built. While we previously explored how this impacts the transactional databases that serve as an agent’s workspace, the problem cuts across the entire data engineering lifecycle that supplies agents with reliable information.
The problem becomes clear when examining how businesses deploy AI today. According to the Anthropic data, coding tasks dominate API usage at 44%. While this aligns with Claude’s reputation as a strong coding model, the sheer scale of this concentration points less to model capabilities and more to a simple reality: it also reflects where existing infrastructure makes automation feasible.
Code repositories are centralized, version-controlled, and programmatically accessible. Most enterprise data is not. For AI to break out of this developer-centric niche, it must confront a messy reality: a fragmented data stack that imposes a steep tax on building reliable, autonomous systems.
The Automation Challenge in Data Engineering
The limited impact of AI code-generation tools in data engineering reveals an important distinction. Unlike software development, where code is the product, data engineering treats code as merely instrumental. The real work is operational: orchestrating distributed systems across storage, compute, and governance layers. Tools like Cursor and Copilot excel at writing code, but they barely touch the bottleneck — building reliable, observable automation across fragmented infrastructure.
The future belongs to platforms that treat AI agents as core constituents.
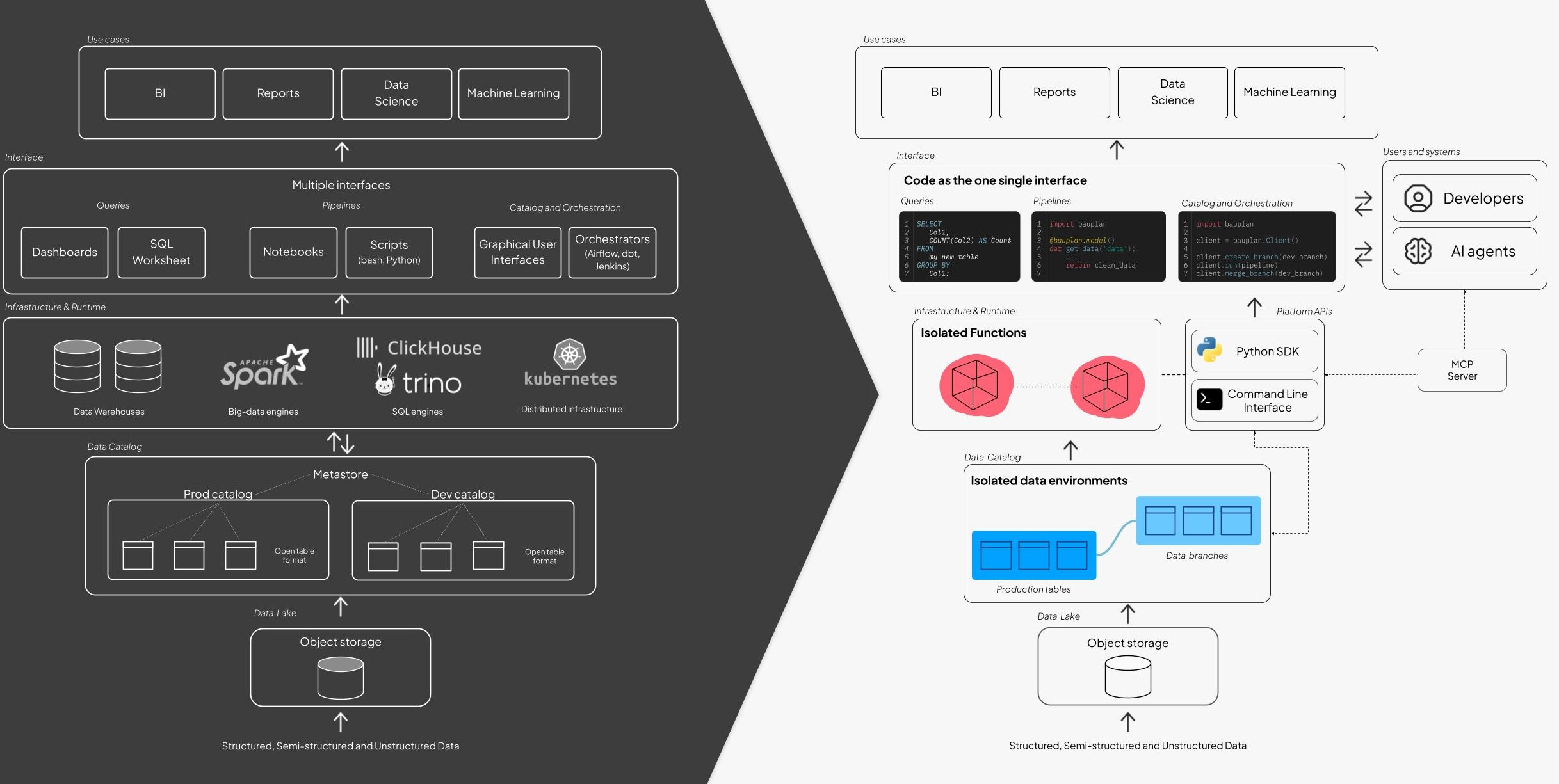
This operational reality explains why the data-as-code movement matters. When infrastructure became code, DevOps productivity surged. Version control, testing, and auditability replaced manual configuration. The same transformation is now unfolding in data operations, not because agents can write better Python, but because code provides the uniform interface agents need to reason about and safely manipulate complex systems. Automation demands repeatability and auditability; fragmented GUIs and YAML configurations offer neither.
Isolation as an Architectural Requirement
For autonomous agents to operate safely in production data environments, isolation must be built into the data platform from day one. The challenge is granting operational authority while ensuring zero risk to production integrity. This requires two distinct forms of isolation that work in concert.
Runtime isolation ensures every execution is ephemeral and stateless. Functions execute in sandboxed environments with immutable dependencies and strict network controls. No shared state, no persistent side effects. This containment guarantees that even unexpected agent behavior carries zero blast radius. Data isolation operates differently but serves the same goal. Agents must access production-quality data without touching production tables. Open table formats like Apache Iceberg enable this through zero-copy branching: agents write to isolated branches, execute validations, and merge only when all checks pass.

This approach is what modern lakehouse architectures enable. By combining object storage with versioned table formats (Iceberg, Delta Lake), teams gain atomic commits, full lineage, and instant rollback. Databricks and Snowflake have proven that open tables on object storage can support enterprise-scale workloads. But what’s still missing in most stacks is runtime isolation and composable APIs — the last mile required to make those systems safe for autonomous agents.
Platforms built around these principles — FaaS-based execution, isolated branches, and atomic merges — create a trusted environment where automation can happen continuously and safely. This isn’t theoretical: it’s how an agent can fix a broken pipeline, validate its output, and publish a clean result without touching production data.
The Fragmentation Tax on AI Development
This friction stems from a deep-seated structural issue: data work is typically siloed into three distinct phases. One set of tools is used for initial analysis, another for building data processes, and a third for running them in the live business environment. This division imposes a “fragmentation tax” with severe consequences. Code becomes difficult to reuse because its core purpose is obscured by scheduling details. Reproducibility suffers, making it a challenge to debug past results. And most frustratingly, the gap between environments leads to the all-too-common scenario where code validated in development still causes failures in production.

This brittle foundation is ill-suited for the continuous, reliable automation that AI systems demand. As the Anthropic report notes, a key bottleneck for enterprise AI is the difficulty of curating the right context. This fragmentation is a primary cause, scattering data, logic, and environmental state across siloed systems and making it very challenging for an agent to assemble a coherent, actionable view of the world.
The Composability Imperative
Perhaps the most promising architectural response is the composable data stack. Rather than monolithic platforms, this approach assembles specialized components through clean APIs: open table formats on object storage, detachable query engines, and ephemeral orchestration layers. Databricks pioneered this with the lakehouse model, proving that modularity at the data layer scales. Snowflake and others followed, cementing the pattern.
The next frontier is composability in compute and control. New platforms like Bauplan combine serverless functions, object storage, and embedded databases for planning — each swappable and independently scalable, yet unified through a minimal API surface. This matters because, as the Anthropic data reveals, API customers gravitate toward complex, high-value tasks. Composable architecture enables these workloads by letting teams integrate specialized capabilities without rebuilding their stack.
The embedded database pattern exemplifies this philosophy. Systems like Kùzu run within the application process, eliminating network overhead while providing sophisticated graph operations. With simple package installation and permissive licensing, teams can add powerful planning capabilities to existing systems without managing separate infrastructure. This accessibility is crucial: as the Anthropic report shows, AI adoption remains concentrated. Reducing infrastructure complexity helps democratize access to more sophisticated automation.
By unifying isolation and composability, the data stack becomes agent-ready. Pipelines become reproducible, stateful, and safe. Every operation — read, write, branch, merge — is both human-auditable and machine-executable. That’s the future of data engineering, and the architectural foundation for AI-assisted automation at scale.
{kind=link}
Code-First Infrastructure for an Automated World
Automation isn’t just about smarter planning — it requires infrastructure that can be driven entirely by code. Systems built around SQL, YAML, or GUIs create friction for AI agents, which need stable, programmable surfaces. The emerging pattern is clear: treat everything as code.
Pipelines become plain Python functions. Tables are defined and branched programmatically. Validation and deployment happen through APIs or CLI commands. This model gives both humans and agents a uniform way to reason about infrastructure and execute safely.
Agent-native means everything as code: instant branches, clean audits, reliable hand-offs.
The same shift is happening in transactional systems, where agents already spin up ephemeral databases or functions through API calls. In both cases, infrastructure becomes dynamic and on-demand — a substrate that automation can control directly.
Anthropic’s data supports this direction: organizations exposing their systems through APIs achieve higher automation rates for complex, contextual tasks. Code interfaces make knowledge machine-readable.
New platforms like Bauplan extend this idea to the data plane. Every run produces an immutable commit linking code, data, and environment. Agents can branch, test, and merge using the Write-Audit-Publish model — a safety net for autonomous operations.
From Human-Driven to Agent-Native
The shift from augmentation to automation is reshaping the requirements for data infrastructure. When 77% of business API usage involves complete task delegation, systems optimized for human interaction become bottlenecks. Agent-native architectures share several characteristics: they provide programmatic interfaces that reduce errors, they support rapid provisioning of isolated environments, and they maintain comprehensive audit trails. Crucially, they treat planning and coordination as first-class concerns, often through graph-based approaches. Such platforms provide the reliable data supply chain, while a new generation of transactional databases offers the ephemeral, isolated workspaces agents need to execute their tasks. Together, they form two essential layers of a truly agent-native stack.
The Anthropic report suggests we are still in the early stages of this transition. While directive usage is rising, most AI deployment remains concentrated in well-structured domains like coding. The next phase of adoption will require infrastructure that matches agents’ growing autonomy. For engineering teams building AI applications, the message is clear: the path to sophisticated automation runs through deliberate information architecture. The future belongs to platforms that treat AI agents not as users, but as core constituents.
Where AI’s Future Takes Shape

Ben Lorica edits the Gradient Flow newsletter and hosts the Data Exchange podcast. He helps organize the AI Conference, the AI Agent Conference, the Applied AI Summit, while also serving as the Strategic Content Chair for AI at the Linux Foundation. You can follow him on Linkedin, X, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.