

LLM Inference Hardware: Emerging from Nvidia's Shadow

Beyond Nvidia: Exploring New Horizons in LLM Inference
The landscape of large language models (LLMs) and Generative AI (GenAI) is undergoing rapid transformation, fueled by surging interest from executives and widespread interest across diverse sectors. Over one-third of CxOs have already embraced GenAI in their operations, and nearly half are actively preparing to invest in this cutting-edge technology. In 2024, LLMs are set to impact a diverse array of sectors such as customer service, software development, medicine, and law, by providing unparalleled efficiency and fostering significant opportunities for business growth.
As the applications of LLMs expand, there is an escalating demand for efficient, fast, and cost-effective inference solutions. As the applications of LLMs proliferate, there is a heightened need for efficient, rapid, and cost-effective inference solutions. This demand is pivotal, as companies strive to optimize the value of LLMs, seeking to swiftly and dependably generate text at scale for a wide range of users. While most inference today relies on Nvidia GPUs, 2024 will see alternative solutions starting to gain market share. The expanding number of hardware options for large language models and GenAI inference is a welcome development for AI teams needing more computing power.
This shift is particularly significant considering the historical context. For years, the use of LLMs was largely restricted to well-resourced teams, due to high cloud costs and lengthy GPU acquisition times. This exclusivity often left smaller innovators and AI enthusiasts at a disadvantage. But a wave of innovative hardware solutions is emerging, aiming to democratize LLM inference and open new generative AI possibilities for all. Unlocking the full potential of LLMs hinges on overcoming this critical efficiency and cost hurdle.

So while Nvidia GPUs currently dominate, 2024 is set to become a pivotal year as new hardware contenders reshape the landscape - making LLM inference more accessible and fueling the wider GenAI revolution across countless industries. My goal in this post is to provide an overview of emerging hardware alternatives for LLM inference, specifically focused on hardware for server deployments. My focus will be on general-purpose hardware like GPUs and CPUs, rather than specialized accelerators such as TPUs, Cerebras, Intel Gaudi, or AWS Inferentia.
It’s also important to note, however, that the evolving landscape isn’t limited to server-based solutions. Companies like Apple and Useful Sensors are also innovating in the realm of edge computing, developing LLM solutions deployable in everyday appliances and electronic devices, which complements the advancements in server hardware.
AMD GPUs Present a Compelling Option for LLM Inference
AMD is emerging as a strong contender in the hardware solutions for LLM inference, providing a combination of high-performance GPUs and optimized software. AMD's Instinct accelerators, including the MI300X and MI300A accelerators, deliver exceptional throughput on AI workloads. Paired with AMD's ROCm open software platform, which closely parallels the capabilities of Nvidia's CUDA, these GPUs can efficiently run even the largest models.
To further optimize LLM inference, AMD has partnered with Lamini, whose software includes innovations like model caching, dynamic batching, and a GPU memory-embedded cache. Together, these hardware and software advancements address previous challenges like long lead times and resource intensiveness that have slowed enterprise GPU deployment. The result is a platform that delivers substantially higher performance and efficiency for LLMs via GPU acceleration, offering a competitive alternative to Nvidia's platform in terms of software capabilities and hardware availability.
The experience of companies like iFit is a powerful testament to the effectiveness of this collaboration, proving its ability to drive tangible results. Through the deployment of AMD hardware and Lamini's software, iFit and similar enterprises have experienced the ability to rapidly iterate and deploy performant enterprise LLMs. Benchmarks showcasing AMD Instinct GPUs achieving up to 166 TFLOPs and 1.18 TB/s memory bandwidth on LLM workloads further underscore the capabilities of this alliance.
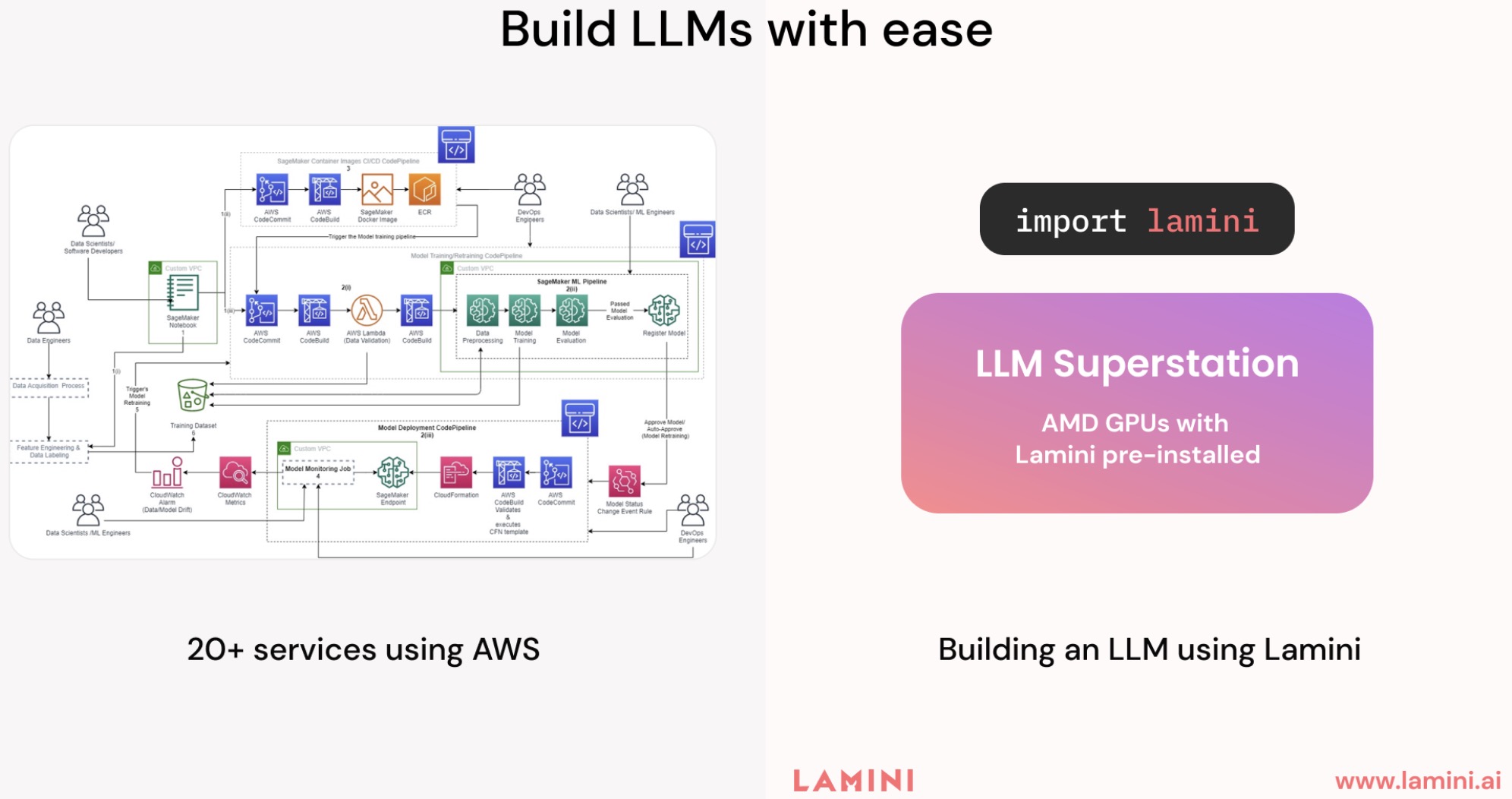
With its combination of high-throughput hardware and optimized software for efficient LLM execution, AMD's offering presents a compelling alternative to Nvidia for the 2024 inference market. As real-world production deployments continue, AMD and its partners show strong potential to keep pushing the boundaries of what's possible with LLMs on GPUs.
The Rise of CPU-Based LLM Inference Solutions
CPU-based solutions are emerging as viable options for LLM inference, especially for teams with limited GPU access. Neural Magic’s approach to LLM inference allows for more efficient model processing without a significant loss in accuracy, positioning CPUs as a practical alternative for both inference and fine-tuning tasks. Their focus on balancing model size, speed, and accuracy, particularly through sparsification and quantization, makes them stand out, especially for scenarios where GPU resources are limited or CPU affordability is a key consideration.
Neural Magic's technology already demonstrates its potency with concrete metrics like speedup and accuracy recovery. By optimizing LLMs for performance on commodity CPUs, they provide a path for quicker execution and the flexibility of running multiple models locally. This innovation is especially critical for teams with limited access to GPUs, offering them a viable and efficient solution for deploying LLMs
Intel complements these advancements with its BigDL-LLM and Intel® Extension for Transformers. BigDL-LLM is an open-source library designed to optimize matrix multiplication and memory management for efficient LLM inference on CPUs. This library focuses on enhancing the processing capabilities of CPUs, making them more suitable for handling the demands of large language models. On the other hand, the Intel® Extension for Transformers provides an interface for deploying transformer-based models, including LLMs, across Intel hardware platforms. It offers optimized kernels for transformer models and supports inference on both CPUs and GPUs, thus broadening the range of options available to developers.
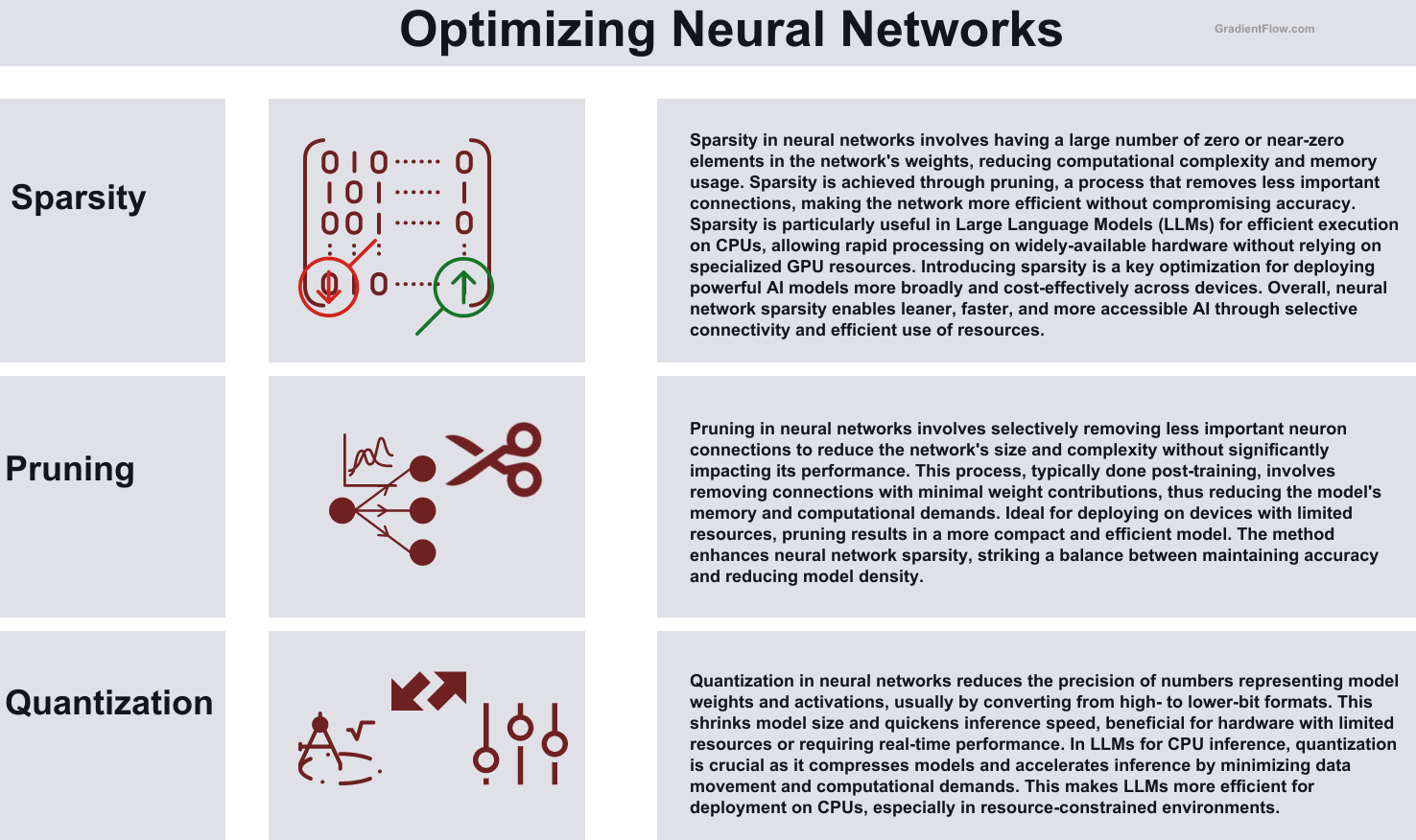
Together, the efforts of Neural Magic and Intel signify a hopeful future for CPU-based solutions in LLM deployments.. For teams unable to adopt GPUs extensively due to cost or infrastructure constraints, sparsity and quantization optimizations from Neural Magic and performance libraries like BigDL-LLM demonstrate CPUs can deliver sufficient throughput without sacrificing accuracy or versatility. With ongoing advancements in technology, CPUs have the potential to become even more powerful and cost-effective options for LLMs.
Emerging Horizons in LLM Inference
As highlighted in this post, the hardware landscape for LLM inference is undergoing a significant transformation. While Nvidia GPUs currently dominate, 2024 is expected to usher in a wave of alternative technologies that will significantly diversify and enhance server-based LLM inference.
Central to this evolution are AMD's GPUs and the innovative CPU-based solutions from companies like Neural Magic and Intel. These technologies represent strides towards a more varied hardware ecosystem, offering rapid iteration capabilities, efficiency, and in some cases, a viable alternative to Nvidia GPUs. In particular, the advancements in optimized CPU solutions are providing new avenues for teams, especially those with limited access to GPU resources, underscoring the growing inclusivity in the LLM inference field.
Adding to this diverse hardware landscape is Meta's foray into custom-designed silicon based on RISC-V technology, purpose-built for AI workloads. If innovations like this successfully lower barriers to access, they could truly democratize generative AI and unlock its benefits for companies of all sizes. Ultimately, this hardware diversity, fueled by both open source solutions and custom silicon, leads to greater accessibility and choice. Rather than facing vendor lock-in, teams can select the most fitting option for their specific needs from a vibrant tech ecosystem.
I firmly believe that while Nvidia GPUs will continue to be a versatile mainstay for years, the horizon is bright with more specialized alternatives tailor-made for scalable LLM inference across various use cases. As GenAI increasingly weaves its way into both business and societal fabrics, we're on the cusp of a hardware revolution that I'm convinced will dramatically transform how teams build and deploy this game-changing technology. This development is particularly promising. It stands to benefit a wide range of stakeholders, from established tech giants to emerging players, setting the stage for a dynamic and competitive landscape in the ever-evolving world of AI.

Data Exchange Podcast
LLMs on CPUs, Period. Nir Shavit, a Professor at MIT's Computer Science and Artificial Intelligence Laboratory, is a Founder of Neural Magic, a startup working to accelerate open-source large language models and simplify AI deployments.
Tools and Techniques to Make AI Development More Accessible. Sarmad Qadri, founder and CEO of LastMile, a startup building an AI developer platform for engineering teams. The discussion focuses on injecting software engineering rigor into the development of large language models (LLMs) and generative AI applications.

If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, Artifact, and Post. This newsletter is produced by Gradient Flow.
Coming to this late but it reads well with hindsight. The landscape has shifted quite a bit since you wrote this. Cerebras, which you mentioned briefly as a specialised accelerator, just landed a $10 billion inference deal with OpenAI and shipped the first production model on non-NVIDIA silicon. 1,000+ tokens per second for code generation. The memory bandwidth angle turned out to be the unlock. I covered the Cerebras architecture and why it matters for developer workflows here: https://reading.sh/chatgpt-and-codex-are-about-to-get-helluva-lot-faster-51ad25a7eed0