



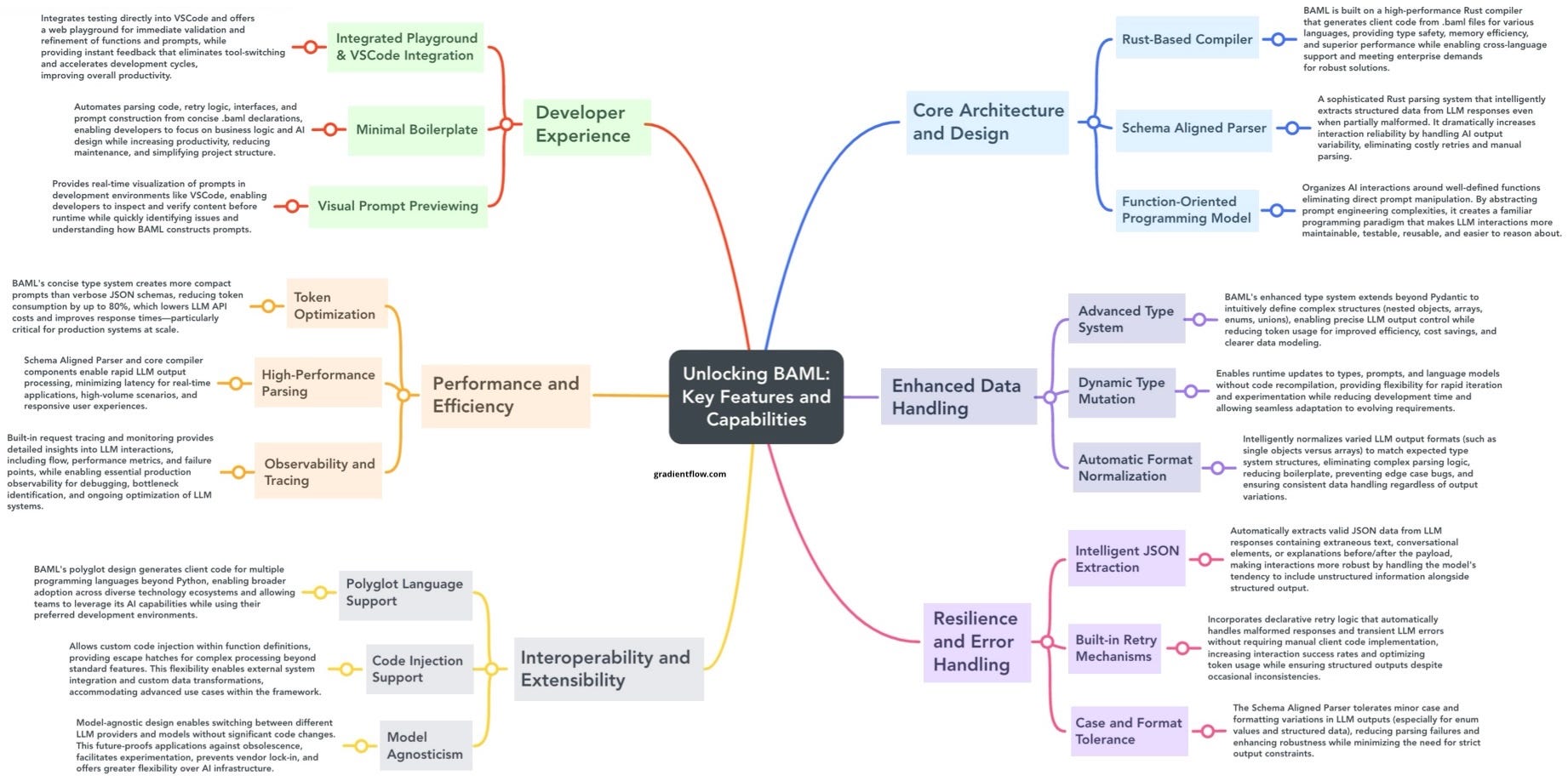
Level Up Your AI Team's Workflow

Faster Iteration, Lower Costs: BAML's Impact on AI Projects
Back in November, I outlined "Seven Features That Make BAML Ideal for AI Developers," and since then, I've been thrilled to see a surge of developers embracing BAML for their AI projects. For AI teams seeking a more robust and deterministic approach to foundation models, BAML offers a powerful solution by treating prompts as structured functions. To explore this growing enthusiasm firsthand, I recently spoke with David Hughes, Principal Data & AI Solution Architect at Enterprise Knowledge, a dedicated BAML user. Below is a heavily edited excerpt from our insightful conversation about his experiences with BAML.
Q: What is BAML and what initially drew you to it?
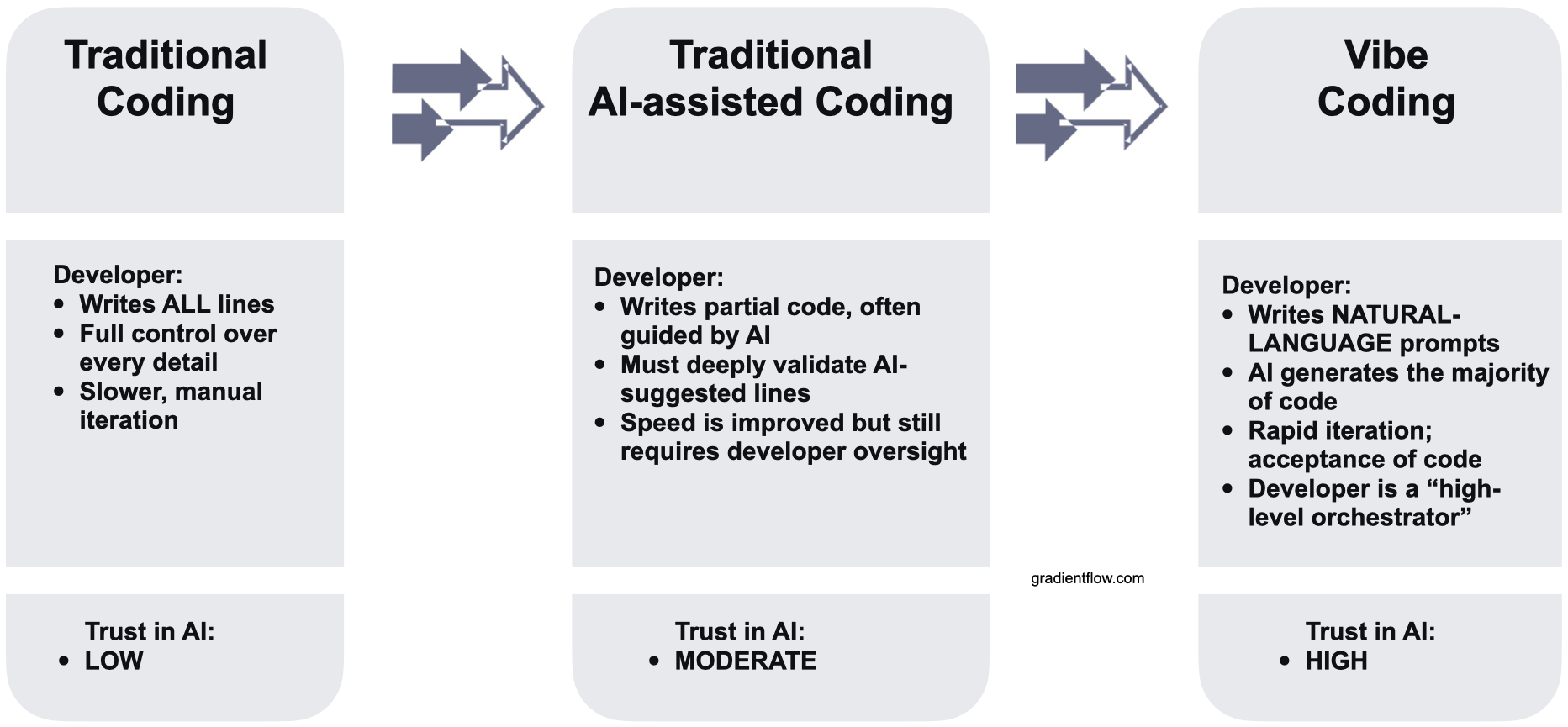
A: BAML is a domain-specific language that treats prompts as structured functions with defined inputs and outputs. Like many practitioners, I've used popular frameworks like LangChain, LlamaIndex, and Haystack extensively. While I could build innovative solutions with them, they often proved brittle. Any changes to input data or integrating new models required significant re-engineering and prompt adjustments.
My "aha moment" came from a podcast episode where prompts were described as functions within BAML. This concept of rigorously managing language model interactions resonated deeply. After trying BAML for just one afternoon, I realized it offered a fundamentally better approach, and I wouldn't need to touch another framework again.
Q: How does BAML's approach of treating prompts as functions differ from traditional prompt engineering?
A: The shift is profound. With BAML, I no longer fixate on crafting the perfect prompt text. Instead, I concentrate on defining clear schemas using classes in BAML, similar to Pydantic. I prioritize defining the desired output structure and ensuring deterministic results for reliable downstream system integration.
Instead of "begging and pleading" with a language model, I spend more time thinking rigorously about my objective. BAML's Playground, an IDE extension, is also transformative. I can test prompts and schemas directly within my development environment, drastically shortening the iteration cycle compared to traditional approaches where you might need to deploy to containers for testing.
Q: Is there a steep learning curve with BAML given that it's a programming language?
A: Surprisingly, no. My initial learning curve was incredibly short – about two hours of documentation and Playground exploration. Within that time, I was already refactoring complex codebases.
While BAML is a DSL, this is actually a strength. Many developers are proficient in languages like Rust for production environments, yet AI development often defaults to Python. BAML, being polyglot, bridges this gap. In under an hour, developers can gain access to a deterministic system for language models, regardless of their primary language. The initial investment unlocks significant productivity gains.
Q: How does BAML compare to frameworks like LangChain, LlamaIndex, or agentic frameworks like Crew or LangGraph?
A: For me, BAML is a replacement, not a supplement. Frameworks like LangChain are heavily prompt-centric. BAML distinguishes itself by focusing on deterministic outputs. This fundamental difference is crucial. [Coincidentally, a recent article practically demonstrates BAML’s power in real-world data workflows, specifically in extracting information and integrating with graph databases like Kuzu, which contrasts with the more prompt-centric frameworks.]
The other frameworks become brittle because they're centered around crafting prompts for specific language models. With the rapid pace of model releases, this requires constant refactoring. BAML's runtime refactoring capabilities—allowing dynamic adjustments to prompts, models, and even output schemas—address this brittleness, especially with the rapid evolution of new language models. This is particularly valuable as different models have different task affinities - with BAML, you can easily match the right model to the right task.
Q: The "prompt engineer" role emerged with the rise of LLMs. Does BAML diminish the need for specialized prompt engineers?
A: Largely, yes. You still write prompts in BAML, but it removes the need for "prompt whisperers" who specialize in model-specific prompting nuances. Keeping up with the task affinities of rapidly evolving models was becoming unsustainable for prompt engineers.
BAML's philosophy encourages breaking down complex tasks into smaller, type-safe, atomic units of operation and reasoning. By emphasizing composability and leveraging smaller, task-aligned language models (which I use about 95% of the time), BAML promotes more resilient and higher-quality outputs, reducing reliance on intricate, model-specific prompt engineering.
Q: How does BAML help teams manage costs associated with LLM API usage?
A: BAML offers several cost-saving mechanisms. In the Playground, you can directly see token counts for your prompts, enabling iterative optimization for conciseness while maintaining output quality. BAML's context injection is also highly efficient, minimizing token usage.
Crucially, BAML's schema-aligned parser significantly reduces costs by eliminating re-prompting. Unlike approaches that rely on re-prompting to correct output formats, BAML ensures the output conforms to the defined schema, regardless of the raw LLM response, avoiding unnecessary API calls and their associated costs.
Q: LLMs are known for sometimes producing "approximately correct" formats. How does BAML handle output parsing and error handling?
A: Even with BAML, inspecting the raw LLM output in the Playground reveals that models often don't produce perfectly formed JSON. However, BAML's parser consistently delivers well-structured JSON based on the schema.
While some systems constrain LLM outputs, they may still return technically valid JSON with incorrect content. BAML provides transparent visibility into what the language model returns and will generate an error if the content cannot be properly parsed to match your schema. This gives you well-defined errors to check for and allows you to create assertions that validate your output. This rigor significantly cuts down iteration cycles and simplifies error handling compared to dealing directly with unstructured or inconsistently formatted LLM outputs.
Q: How does BAML help with testing and debugging AI applications?
A: Language models are fundamentally generators of probabilistic next tokens - they weren't designed to provide structured output. BAML bridges this gap by parsing outputs into the structures you've defined in your schemas.
Because BAML gives you programmatic objects, you can perform runtime assertions and checks. For example, if I'm extracting colors from an image, I can assert that the returned list contains at least one color. I can use assertions to verify if the output is an instance of the expected type and enforce data integrity constraints. This level of programmatic control and testability significantly simplifies debugging compared to dealing directly with unstructured or inconsistently formatted LLM outputs.
Q: What advantages does BAML's cross-language compatibility offer in enterprise environments?
A: BAML's polyglot nature is a major advantage for enterprises. It's designed to be a DSL accessible from any language. Even if native support isn't immediately available for a specific language, BAML provides an API that can be used universally.
Native Rust support is underway, and the architecture is designed for extensibility. This language agnosticism makes BAML readily adaptable to legacy systems and diverse technology stacks common in large organizations. For example, I recently worked on projects requiring Rust, and while BAML doesn't yet have native Rust output, I could use the API and create stubs that will be easy to port when native support arrives.
Q: How does BAML support the development of agentic AI applications?
A: BAML is crucial for building sophisticated agentic systems. I've successfully migrated agentic systems previously built with LangGraph to BAML. It allows you to create agent registries with defined reasoning engines.
Key features include dynamically changing reasoning engines, language models, and prompts for agents. Furthermore, BAML's ability to update output schemas at runtime is invaluable for self-optimizing and autonomous agents. For example, if I discover during execution that I need to add a field to a "person" object, I can do that dynamically and continue getting that updated output.
These features are key for agents that can adapt to changing environments and data by dynamically modifying their output structures, reasoning processes, and even underlying models based on runtime observations and performance metrics.
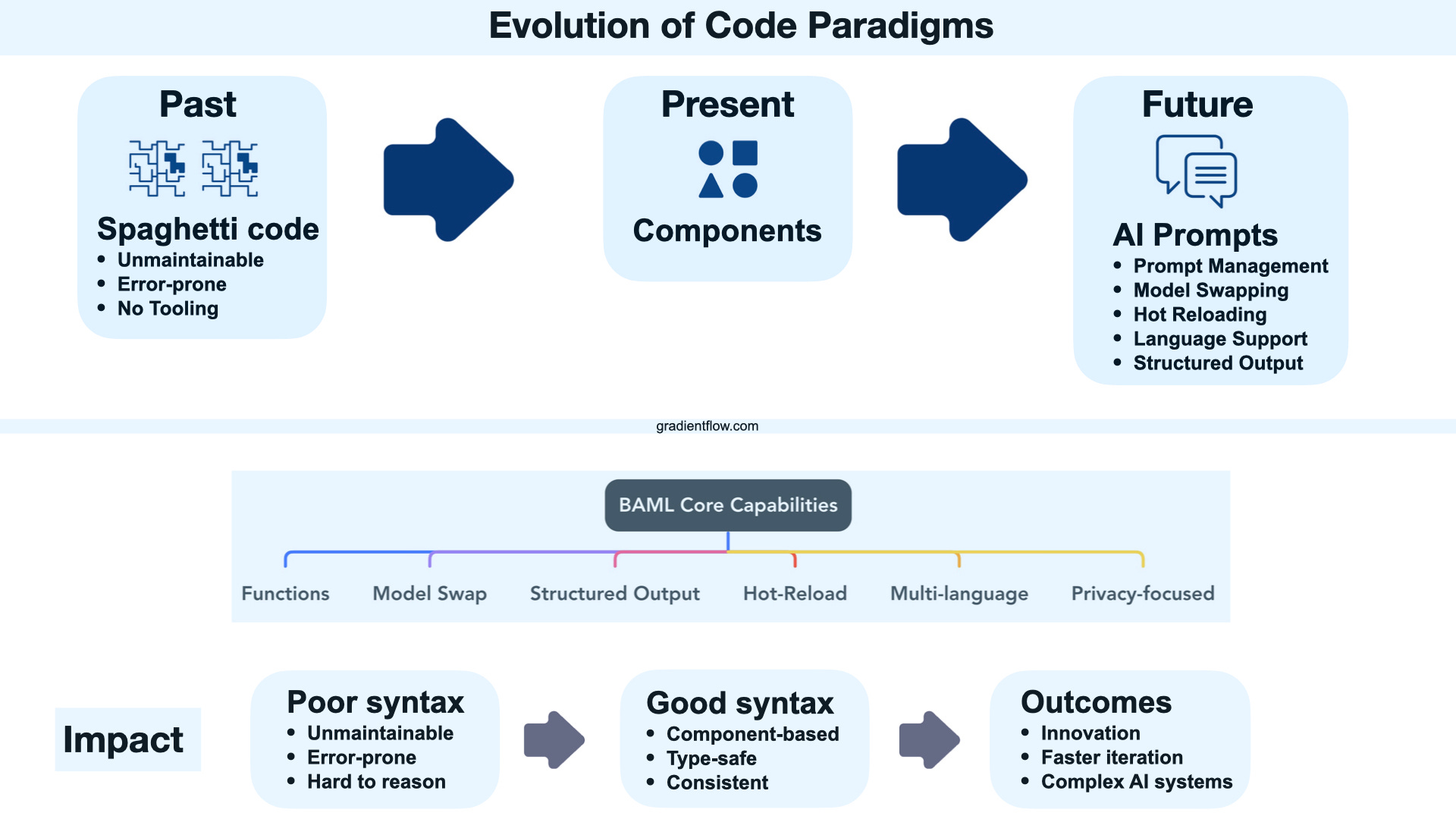
Q: What exciting features are coming to BAML in the near future?
A: The enhancement of "prompts as functions" is very exciting. BAML is expanding the ability to embed more code logic directly within prompts, including iterations and conditional statements. This will further solidify the concept of prompts as powerful, programmable functions, unlocking significant new capabilities and expressiveness.
The broader community around BAML is also growing, with Donew (agentic apps) and Kùzu (for GraphRAG) integrating with BAML. This ecosystem growth will further enhance BAML's value proposition as a foundational AI development tool.
Q: For technical teams curious about BAML, how should they get started?
A: I highly recommend investing an hour to explore BAML. Install the plugin for your IDE (VS Code, Cursor, etc.), follow the quickstart in the BAML docs, and jump into the Playground. Focus on defining the output structure (schema) you want.
If you get stuck, the official BAML Discord is responsive, and the community is growing quickly. It might seem like another tool to learn, but the paradigm shift it offers in working with language models is transformative. If you've struggled with brittle prompts or big, monolithic frameworks, you might find BAML's approach of small, composable "prompt functions" more intuitive. In my experience, it also cuts down on cost and iteration time.
Secure Your Spot at the AI Agent Conference (NYC, May 6-7) – Limited Seats! Use code GRADIENTFLOW25 for 25% off before it expires.
The Gradient Flow newsletter is FREE, thanks to our paid subscribers. Join them for extra content and to support our work! 📩
{kind=link}
{kind=link}
Data Exchange Podcast
The Evolution of Reinforcement Fine-Tuning in AI. In this episode, Travis Addair, Co-Founder & CTO at Predibase, discusses the transformation of pre-trained foundation models into domain-specific assets through advanced customization techniques.
Bridging the AI Agent Prototype-to-Production Chasm. Ilan Kadar is co-creator of IntellAgent, an open-source platform designed to address the significant hurdles in deploying AI agents from prototype to production, particularly in achieving reliable performance and building user trust.
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the AI Agent Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.