



Is Your AI Secure? New Threats & How to Mitigate Them

Securing Generative AI: Beyond Traditional Playbooks
Generative AI is moving beyond lab experiments and is beginning to power critical business workflows. This shift has fundamentally transformed the security landscape. Unlike traditional software, Large Language Models (LLMs) and agentic systems introduce vulnerabilities more akin to human fallibility than traditional code exploits. Since LLMs generate responses probabilistically rather than deterministically, carefully crafted inputs can manipulate them in ways impossible with traditional software. This behaviour is closer to social‑engineering a person than exploiting code.
Unlock full access: Become a Premium Supporter! 🔓
The result is a dangerous security asymmetry: exploit techniques spread rapidly through open-source repositories and Discord channels, while effective mitigations demand architectural overhauls, sophisticated testing protocols, and comprehensive staff retraining. The longer we treat LLMs as ‘‘just another API’’, the wider that gap becomes.
New Attack Surface: Prompts to System Compromise
Prompt injection currently poses the most immediate and pervasive threat to AI applications. Unlike traditional SQL injection where input validation can mitigate risks, LLMs can be manipulated through carefully crafted prompts that appear innocuous but subvert the model's intended behavior. These attacks can bypass explicit safeguards, potentially leading to unauthorized actions that the system was explicitly designed to prevent.
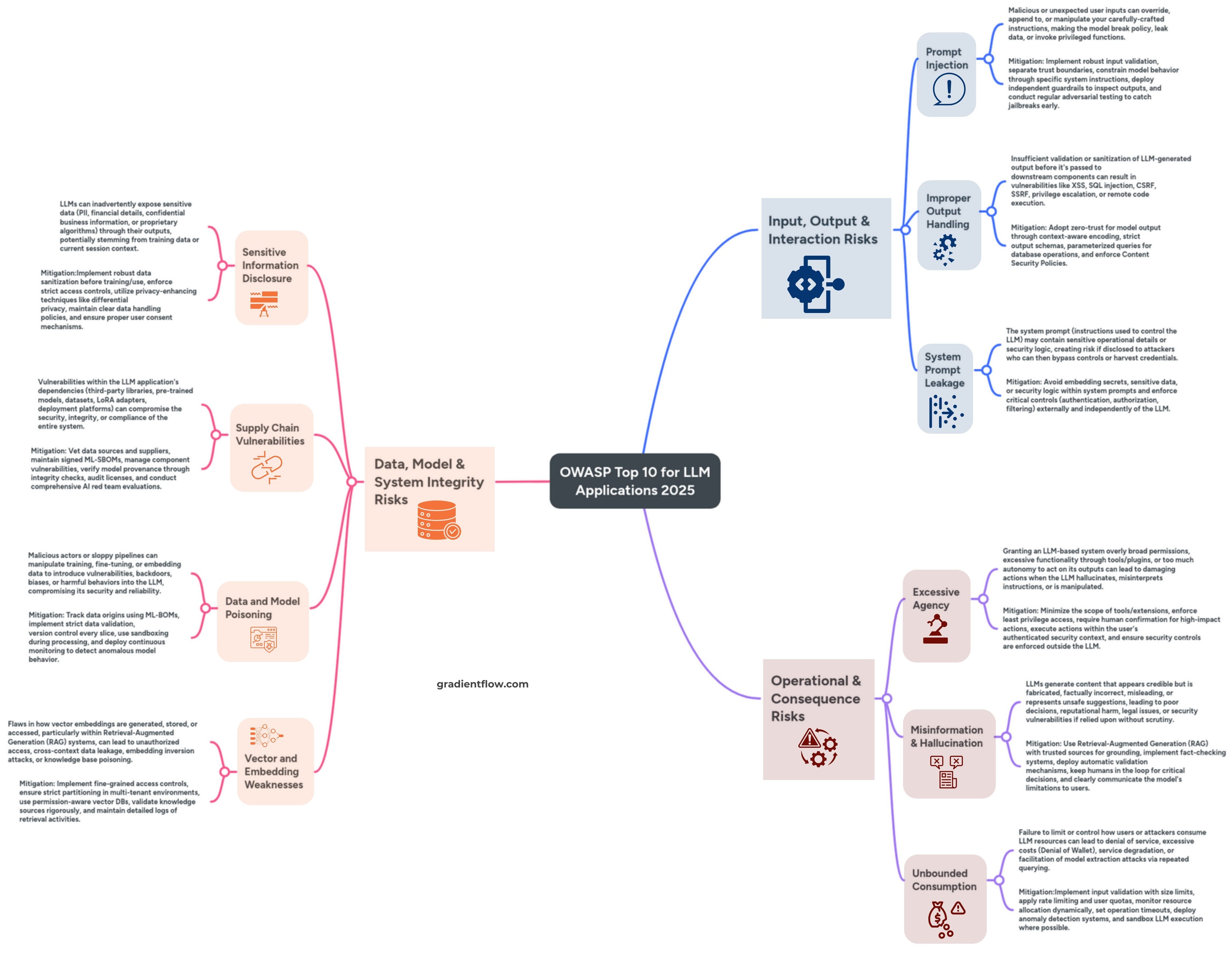
Furthermore, the AI Supply Chain presents unique and complex challenges. We are no longer just managing code libraries; we must contend with vast, opaque model weights (often gigabytes in size) that were derived using massive training datasets whose provenance is frequently unclear. A poisoned checkpoint or a hallucinated/compromised Python package named in an LLM‑generated requirements file can give an attacker code‑execution rights inside your pipeline. Standard security scanners can’t parse multi‑gigabyte weight files, so additional safeguards are essential: digitally sign model weights, maintain a ‘bill of materials’ for training data, and keep verifiable training logs.
Equally concerning is the risk of sensitive information disclosure. LLMs and foundation models lack inherent understanding of confidentiality boundaries, creating a significant risk when they have access to proprietary or regulated information. Without robust controls, these models may inadvertently leak confidential data in their responses, creating compliance and competitive risks that are difficult to fully mitigate through traditional means. To combat these risks, organizations must implement three critical safeguards:
Enforce granular access controls for each data element
Automatically scan all model outputs for potential information leakage
Redact or obfuscate all personal identifiers before responses leave the system
Adapting Security Operations for the AI Era
Addressing AI-specific security challenges requires more than sophisticated tools; it necessitates an operating model centered on shared controls. Some organizations are establishing AI Centers of Excellence (CoEs) with a dedicated security function. By centralizing controls, the CoE enables application teams to innovate rapidly while adhering to stringent compliance requirements, particularly in regulated sectors like finance and healthcare. This mirrors how centralized cloud-security units facilitated secure cloud adoption by managing shared infrastructure risks. For organizations considering this model, the OWASP AI Security CoE Guide offers frameworks for establishing governance structures that balance innovation with security, ethics, and compliance through defined protocols and cross-functional collaboration.
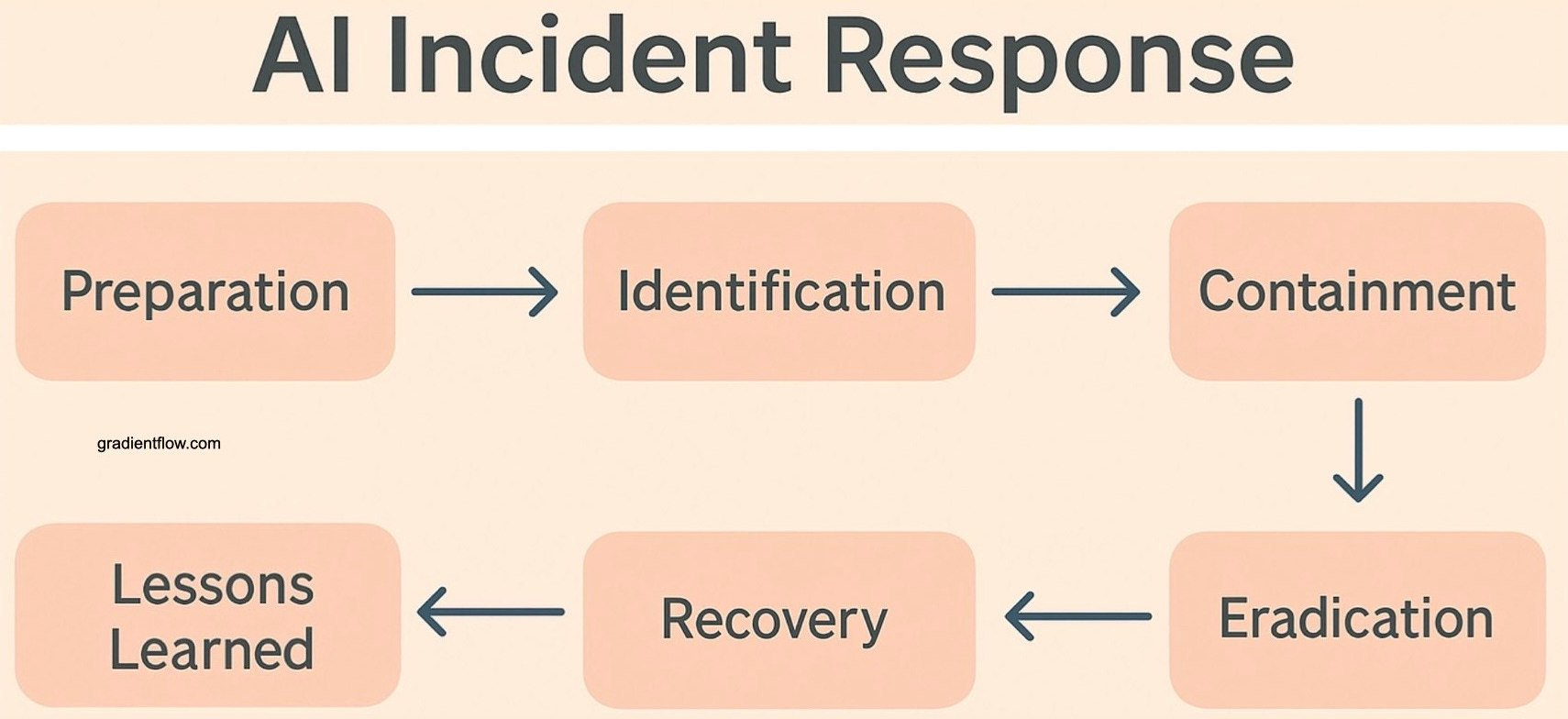
A common technical approach involves a central platform, often implemented as a gateway, that applies guardrails to model interactions. These typically include input and output checks designed to detect policy violations, data leakage (such as Personally Identifiable Information - PII), bias, or attempts to bypass safety mechanisms ('jailbreaks'). However, guardrails and related preventative measures address only part of the risk.
A critical vulnerability in many organizations is the absence of AI-specific incident-response (IR) plans—a dangerous deficiency that becomes increasingly problematic as AI deployments scale across the enterprise. An effective IR playbook must clearly define what constitutes an AI security incident, specify containment procedures (e.g., API rate limiting, model quarantining), and establish clear lines of responsibility. Regular testing is essential to maintain the effectiveness of these plans. This should include red-team exercises that combine automated vulnerability scanning with human expertise to identify weaknesses, such as prompt injection vulnerabilities or flaws in associated plugins and data pipelines. Without this continuous cycle of preparation, testing, and refinement, even the most promising AI prototypes can rapidly evolve into serious operational vulnerabilities and potentially devastating reputational liabilities.

A broader operational challenge is the fragmentation of AI risk management. Controls for privacy, bias, security, and compliance often exist in disparate tools managed by separate teams. This fragmented approach severely impedes the development of a cohesive, comprehensive AI risk posture, inevitably creating inefficiencies, dangerous oversight gaps, and potential regulatory exposure. Consequently, there is increasing demand for unified alignment platforms. These aim to provide legal, compliance, and technical teams with shared workflows, consistent testing methodologies applicable across different model types, and a centralized, auditable repository for governance activities and decisions. Such integration seeks to reduce redundancy, streamline model deployment, and ensure AI systems operate consistently within defined ethical guidelines and organisational policies.
Reading List for the Next Sprint
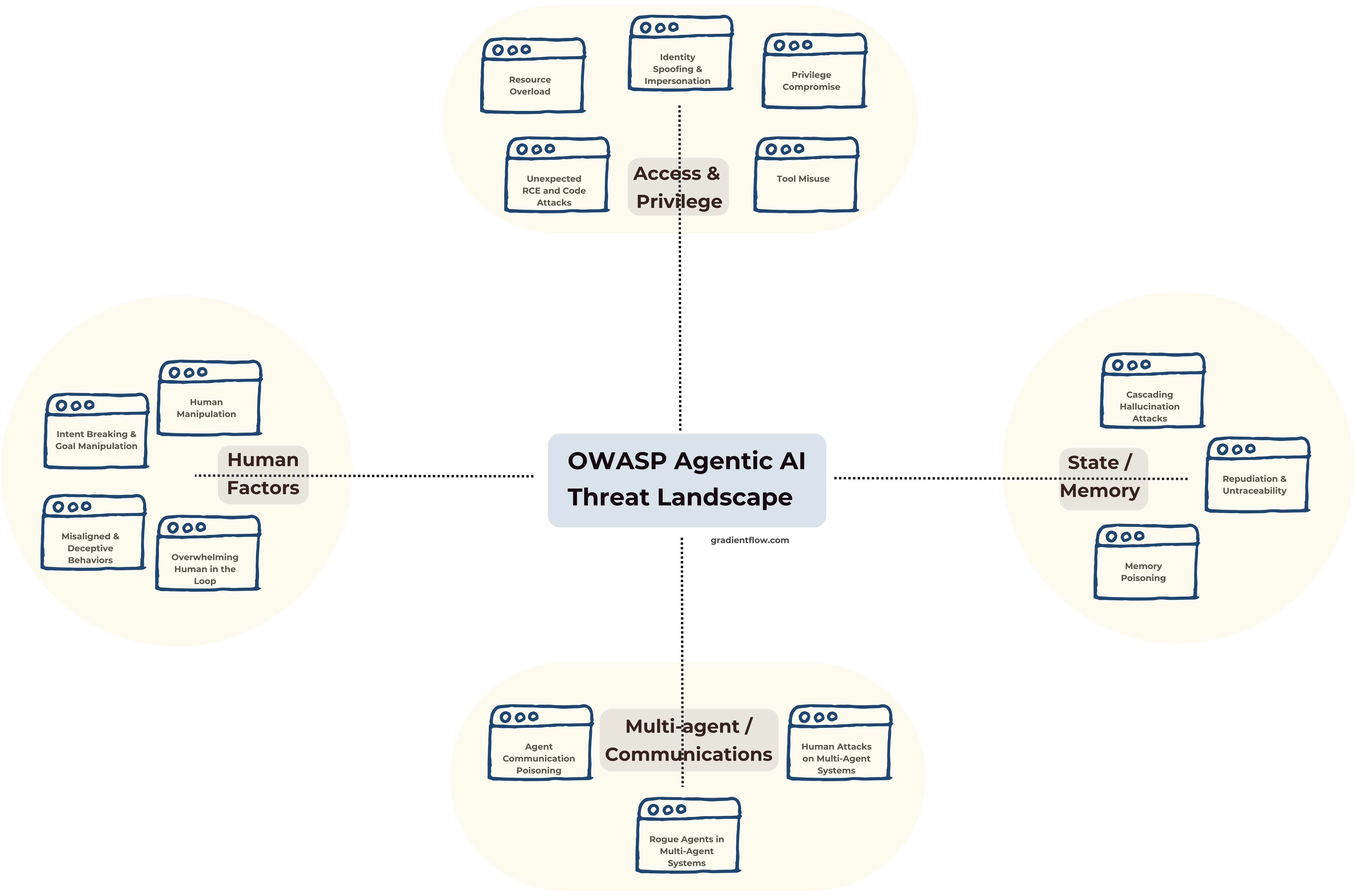
Fortunately, security and development teams need not build their AI security frameworks from scratch. The OWASP GenAI Security Project has already distilled community experience into the Top 10 for Large Language Model Applications and, more recently, the Agentic AI – Threats and Mitigations guide, a threat‑modelling companion for autonomous agents. Both documents are living standards that are updated regularly, and provide check‑lists that map neatly onto AI application development projects. For teams tasked with securing generative AI applications, these resources offer immediate, practical guidance grounded in real-world experience and industry best practices.
{kind=link}
{kind=link}
{kind=link}
Your insights matter: Help guide AI policy by responding to our brief survey.

Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, the AI Agent Conference, the NLP Summit, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.