

How Generative AI is Transforming Healthcare

Generative AI in Healthcare: Beyond the Horizon of Modern Medicine
Whenever a new technology emerges, I like to explore its application across various sectors, especially those that are highly regulated such as financial services and healthcare. These sectors, with their exacting standards and stringent regulations, provide a robust framework for evaluating the maturity and potential impact of emerging technologies.
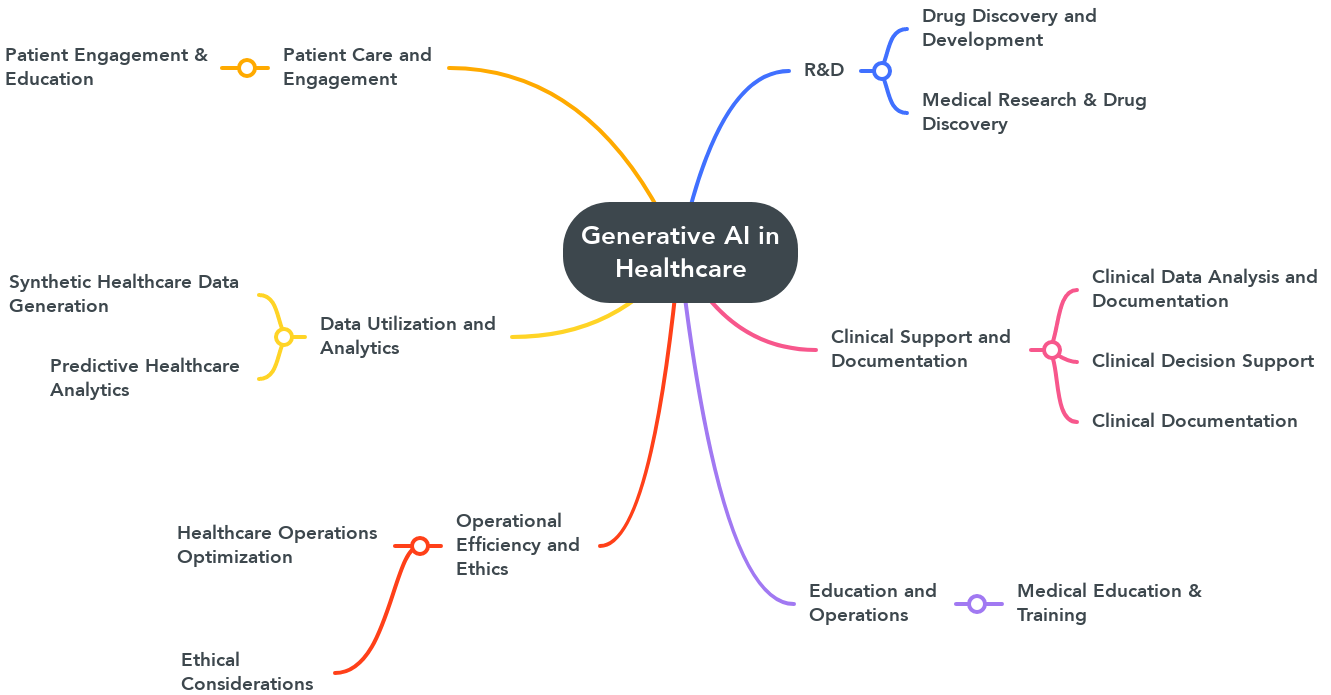
A new free report explores how generative AI could transform healthcare through enhanced clinical support, patient care, data utilization, education, and operations. Highlights include:
Personalized treatment: Generate treatment suggestions tailored to individuals' full health records and latest evidence.
Streamlined documentation: Automatically create clinical notes from voice inputs, saving time and resources.
Clear communication: Simplify patient communications and guidance, fostering better understanding.
Privacy-assured data: Develop realistic synthetic medical data that preserves patient privacy for research and development.
Predictive insights: Identify health risks and forecast outcomes by analyzing data patterns.
Immersive training: Design customized training programs with interactive patient scenarios.
Optimized workflows: Reduce wait times and improve efficiency through optimized workflows.
The report further explores how generative AI and large language models are fueling breakthroughs in drug discovery and medical research, pushing the boundaries of innovation.
As we deploy these technologies, upholding patient privacy, fairness, and transparency remains paramount. Understanding the current state and future potential of generative AI in healthcare offers valuable insights. The capacity to accelerate innovation cycles and promote efficiency as shown in research and development highlights this technology's immense promise.
For full details on the transformative impact of generative AI across healthcare, read or download the free report.
Data Exchange Podcast
AI Infrastructure: From Cloud Computing to Data Center Design. Bryan Cantrill, CTO of Oxide Cloud Computer, discusses the challenges and innovations in cloud computing infrastructure crucial for AI advancement, focusing on efficiency, cost, security, and management in an evolving AI technological landscape.
Transforming Transportation, Enterprise, and Policy. Evangelos Simoudis is a seasoned venture investor and Managing Director at Synapse Partners, a company that invests in startups developing enterprise applications that exploit Big Data and AI. We discuss his new book, The Flagship Experience, which describes how software-defined vehicles and AI will enable automakers, transportation providers, and transportation planners to reimagine the mobility customer experience.

From Supervised Fine-Tuning to Online Feedback
Over the last 9 months, my usage of general-purpose language models like OpenAI's API has decreased as I've learned to leverage open-source models fine-tuned for specific tasks. Anyscale's user-friendly Fine Tuning service has accelerated this transition by making it easy to craft accurate, efficient custom models. Despite the initial investment in creating labeled datasets, the resultant custom models are not only more efficient and accurate but also tailored to specific tasks, providing a dedicated solution that outperforms the broader capabilities of foundational models.
By relying more on specialized models fit to exact needs rather than broad capabilities, I've shifted towards an approach that yields better outcomes through customization. My journey highlights the value of fine-tuning, enabled by accessible services like Anyscale, in creating specialized AI solutions.
Supervised Fine Tuning vs RLHF
Supervised fine tuning (SFT), while powerful, isn't always the best solution for every scenario. SFT requires a large dataset of high-quality labeled examples which can be expensive and time-consuming to collect. Additionally, if there is a significant distribution shift between the training data used for SFT and real-world data the model encounters, model performance can substantially degrade. Augmenting SFT with techniques to promote robustness, like adversarial training, can help, but typically introduces additional data requirements.
An alternative approach called Reinforcement Learning from Human Feedback (RLHF) relies instead on real-time human feedback to shape desired model behaviors. RLHF works by using human judgments about model outputs as reward signals to reinforce behaviors that align with preferences. This allows teaching models new concepts with minimal data through generalization. RLHF is well-suited for more subjective, nuanced tasks where explicit labeling is difficult. RLHF is particularly advantageous for tasks requiring a deep alignment with human values or preferences, where traditional labeled data may not adequately represent the complexity or subtlety of the desired outcomes.
However, RLHF has downsides too. It necessitates extensive human involvement for providing evaluations and rewards, which may not be feasible in some applications. Compared to the simplicity of fine tuning, RLHF introduces additional complexity in terms of training a separate reward model and instrumentation for human interaction. So there are trade-offs to consider when deciding between fine tuning and RLHF based on use case constraints.

Online AI Feedback (OAIF)
While RLHF facilitates aligning models with human preferences, it is not a simple plug-and-play solution. An intriguing new technique called Online AI Feedback (OAIF) from DeepMind offers a way to achieve similar benefits with greater efficiency and less human effort.
OAIF works by collecting real-time preference judgments from a separate language model that acts as an annotator evaluating pairs of responses from the model being trained. The annotator's feedback about which responses better align with goals is then used to update training in a streamlined manner, without needing a distinct reward model.
Compared to RLHF, OAIF simplifies the process by extracting preferences directly from the AI annotator rather than relying on extensive human reward labeling. This self-supervised approach removes friction in the feedback loop. OAIF also enables easy customization of desired outcomes through flexible annotator prompting.
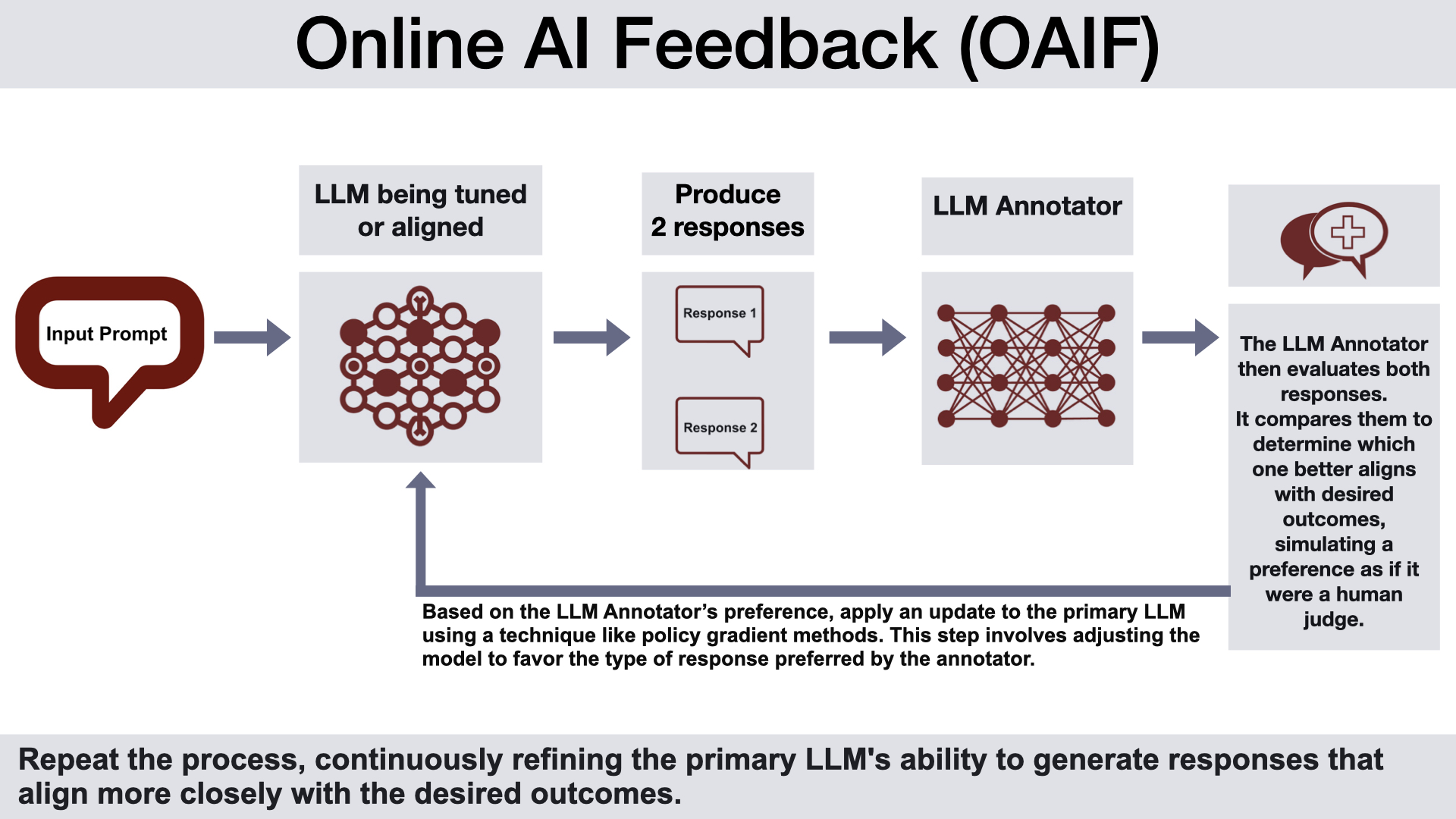
For developers, OAIF offers a more accessible method to align models to preferences with minimal instrumentation. It combines the scalability of self-supervised learning with the responsiveness of human feedback, while automating repetitive judgment tasks. However, reliance on AI evaluation alone risks potential biases or integrity issues. Maintaining oversight and allowing periodic human review of the annotator’s decisions can help mitigate these concerns.
Overall, OAIF represents a promising new point in the design space between supervised learning and RLHF. For use cases where some loss of precision from full human-in-the-loop evaluation can be tolerated in favor of implementation simplicity, OAIF offers an exciting path forward.
Looking Ahead
In closing, when developing custom language models, alignment with human values is as critical as accuracy on functional metrics. For well-defined tasks with clear measures of success, fine tuning on labeled data often suffices. But many applications demand more complex subjective capabilities where human guidance becomes essential.
RLHF enables incorporating such judgments through reinforcement learning, but poses implementation barriers. OAIF puts forth a compelling alternative for applications where some automation of human preferences is acceptable. Between simplified supervised learning, strict human-in-the-loop RLHF and this middle-ground of OAIF, developers now have a spectrum of techniques catered to their needs. The creation of user-friendly OAIF tools are key to enabling widespread adoption of this promising new approach.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Twitter, Reddit, or Mastodon. This newsletter is produced by Gradient Flow.