

Exploring the Efficient Frontier of LLMs

The Efficient Frontier of LLMs: Better, Faster, Cheaper
Since the release of ChatGPT in November 2022, there has been an explosion of interest in large language models (LLMs), with numerous open-source and proprietary models entering the market. As competition intensifies, LLM providers are increasingly focusing on efficiency as a key differentiator to attract users and stay ahead of the curve.
In the race to develop the most advanced and capable LLMs, much of the media attention has been centered on the quest for Artificial General Intelligence (AGI). However, as the market matures, cost and performance efficiency are emerging as critical factors that will determine the success of LLM providers. This shift in focus is driving innovation in pre-training and inference techniques, as providers strive to deliver models that are not only more accurate but also faster and more cost-effective than their competitors.
Analysis
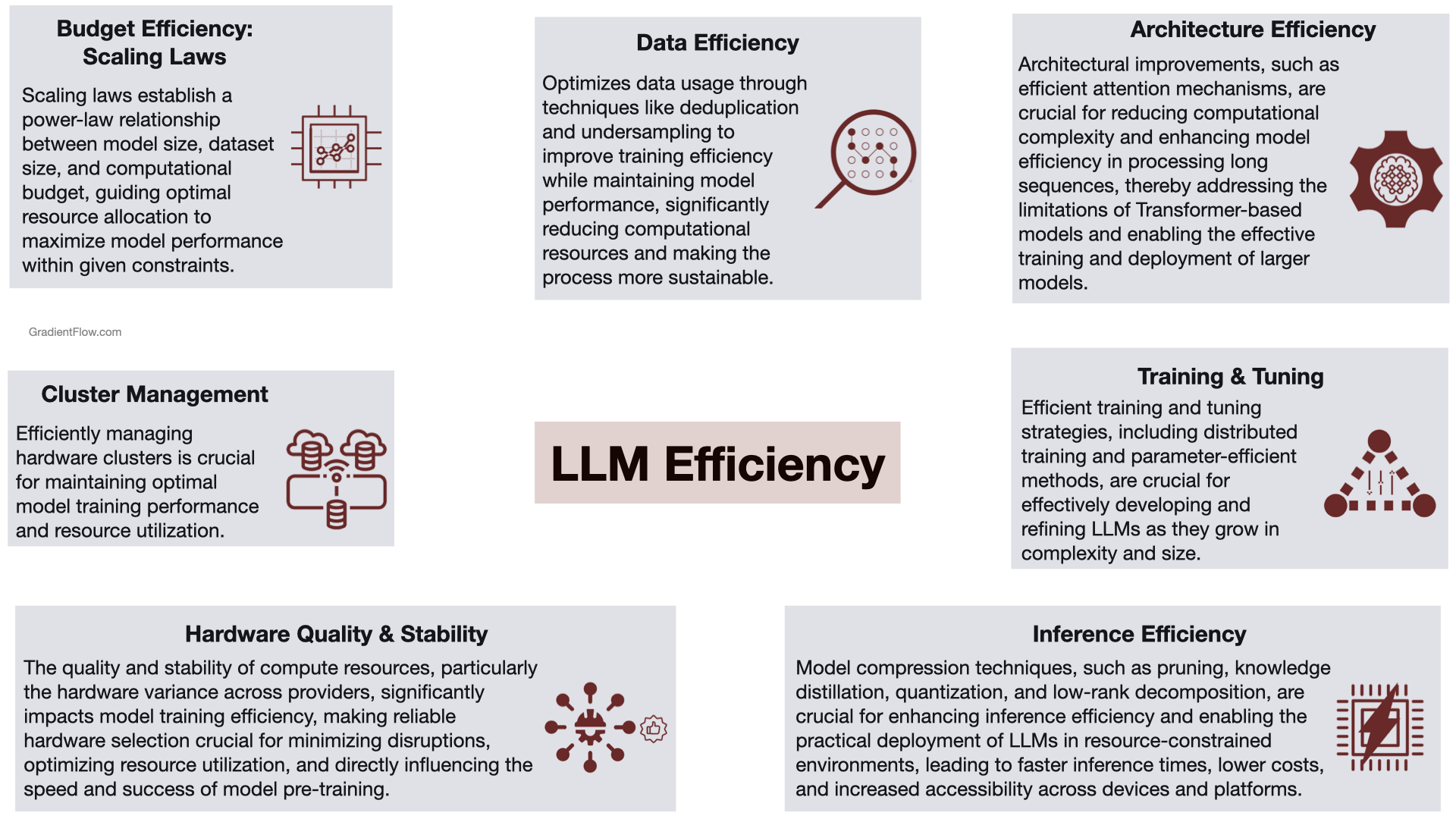
1. Data Efficiency as a Competitive Lever: Mistral AI's success in developing smaller, more efficient models is largely attributed to their prowess in filtering out repetitive or nonsensical information from training data. Investing in data tools and expertise can yield significant returns in terms of model performance and cost savings. This highlights a critical need for industry-wide investment in sophisticated data tools tailored for diverse data types, similar to the pivotal role Visual Layer plays in computer vision.
2. Architectural Innovations Leading the Charge: The remarkable strides made by Google's Gemini 1.5 and Mistral's Mixtral 8x7B, through sparse architectures and Mixture of Experts engines (MoE), exemplify how architectural innovation can drive efficiency. These models not only challenge the status quo with reduced compute demands but also herald a new era of cost-effective, high-performance LLMs.
3. Hardware Quality and Strategic Partnerships for Efficiency: The efficiency of model training is heavily influenced by the quality and stability of compute resources, particularly the inconsistency in hardware performance across various providers. Key factors affecting training efficiency include the overall cluster quality and the performance of accelerators such as GPUs or TPUs. Companies should prioritize hardware assessment and strategic partnerships, leveraging tools like Ray for efficient cluster management and distributed training, ensuring stability and scalability in their AI projects.
4. Emphasizing Cluster Management and Orchestration: Efficient management of computational resources and the strategic use of orchestration tools are indispensable for scaling AI operations without compromising performance. These tools not only optimize resource allocation but also enable flexibility, seamless scalability, and fault tolerance, which are key for managing complex AI workflows.
Efficiency in pre-training is not just an operational advantage - it's a catalyst for innovation and agility in AI development
5. Inference Efficiency: With advancements in model compression and pruning techniques, inference efficiency has become a focal point for deploying LLMs in resource-constrained environments. Adopting strategies like pruning and quantization, businesses can dramatically reduce operational expenses, extending the reach and accessibility of LLM technologies.
6. The Strategic Advantage of Efficient Pre-training: The move towards more efficient pre-training methods is not just about cost savings; it's about agility and innovation. Faster, less resource-intensive training cycles allow for more experimentation and rapid deployment of improved models, offering a strategic edge in a competitive market.
7. Survival of the Efficient (and the Deep-pocketed): This shift towards efficiency also aligns better with the evolving investment landscape, where the focus is increasingly on developing scalable, profitable AI solutions that address specific business needs rather than chasing the elusive goal of AGI. This means startups building foundation models need to be extremely capital and resource efficient, or be attached to a profitable company (e.g. Google, Meta). To achieve this, the model provider's executive team must be fully committed and focused on the task at hand, which may be challenging if they are involved in numerous other side hustles.
8. Interchangeability and Flexibility in Model Selection: Don't be swayed by hype. While some companies dominate tech headlines with new models, remember: the competitive landscape is constantly shifting. Competitors and open source models often catch up in performance within months. This underscores the importance of building applications and systems that offer the flexibility to integrate models from various providers. This ensures access to the best-performing models at any given time, freeing your team from vendor lock-in.
In the era of Generative AI, being better, faster, and cheaper is essential for success. To achieve this, focus on efficiency in your AI applications, even if you're not training your own LLMs. Prioritize data quality, optimal resource utilization, streamlined processes, and innovative architectures to deliver cutting-edge solutions that drive meaningful results. By embracing an efficiency-first mindset, your AI team can stay ahead of the curve and create impactful applications that leverage the power of foundation models.

Data Exchange Podcast
Monthly Roundup. Paco Nathan and I explore the latest AI advancements, from text-to-video models and Google's Gemini system to AMD's AI acceleration software. We also delve into techniques for enhancing foundation models and integrating knowledge graphs with language models.
Unlocking the Potential of Private Data Collaboration. In this episode, Sadegh Riazi, CEO and co-founder of Pyte, discusses secure multi-party computation solutions for enabling privacy-preserving data collaboration, analytics, and machine learning.

Boosting RAG Systems with Knowledge Graphs: Early Insights
In a previous post, I explored the potential of knowledge graphs (KGs) for enhancing language models (LLMs). Building on that, I have collected results from early studies on the use of KGs in retrieval augmented generation (RAG) systems. We are beginning to see the integration of KGs and RAG, particularly in the case of structured data, such as text-to-SQL models.
Recent work on the enhancement of RAG systems using knowledge graphs has shown promising results. Knowledge graph-guided retrieval leverages KGs to guide the retrieval of relevant passages for RAG models, particularly enhancing question-answering and information summarization. Studies have demonstrated improvements in precision and recall over traditional retrieval methods, enhancing RAG model performance. However, the effectiveness of this approach depends on the completeness and accuracy of the KGs, potentially affecting retrieval efficacy.
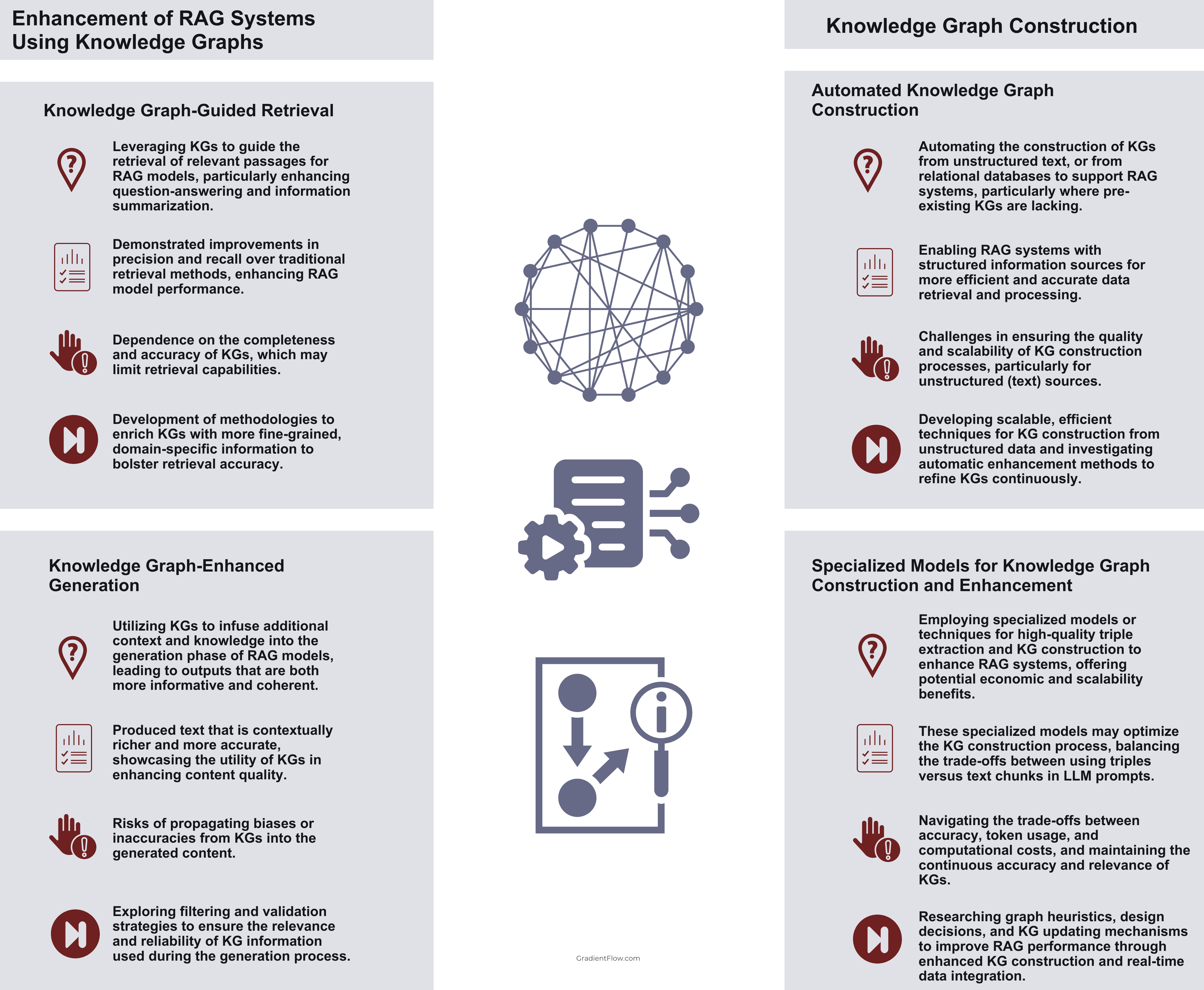
Another focal point is knowledge graph-enhanced generation, which utilizes KGs to infuse additional context and knowledge into the generation phase of RAG models, leading to outputs that are both more informative and coherent. Early experiments suggest that this approach can produce text that is contextually richer and more accurate, showcasing the utility of KGs in enhancing content quality. However, it also carries the risk of transferring biases or inaccuracies from the KGs into the generated material.
An important aspect of all of this is the creation of knowledge graphs. Automated knowledge graph construction from unstructured data is being explored to support RAG systems, particularly where pre-existing KGs are lacking. This facilitates access to structured information sources for more effective and precise data retrieval and processing. However, ensuring the quality and scalability of KG construction processes remains a challenge.
Specialized models for knowledge graph construction and enhancement are also being employed for high-quality triple extraction and KG construction to enhance RAG systems, offering potential cost and scalability benefits. These specialized models may optimize the KG construction process, balancing the trade-offs between using triples versus text chunks in language model prompts. However, navigating the trade-offs between accuracy, token usage, and computational costs, and maintaining the continuous accuracy and relevance of KGs is a challenge.
Explore More:
Nvidia’s GTC 2024 Announcements (a cheat sheet)
The impact of KGs on RAG systems is contingent upon the accuracy and completeness of the knowledge graphs
Although still in the early stages, the integration of KGs with RAG systems shows promise. The easiest place to start seems to be in analytics - using your structured data to create a KG to enhance your RAG system. To advance this field, future research should focus on developing efficient methods for constructing KGs from unstructured data, and exploring strategies to ensure the relevance and reliability of KG information used in the generation process. Investigating graph heuristics and design decisions to optimize RAG system performance through enhanced KG construction is crucial. Additionally, developing KG updating mechanisms for real-time data integration is essential for staying competitive in practical applications.
As the field progresses, we can expect to see more sophisticated and effective integration of knowledge graphs and RAG systems, leading to more accurate, informative, and coherent outputs across a wide range of applications.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, Twitter, Reddit, or Mastodon. This newsletter is produced by Gradient Flow.
Insightful article and a kindred choice of metaphor: Efficient Frontier. We have applied the same term to the opposite side of the coin, algorithmically creating an EF for enterprises to manage cost, quality, response, and security.