

Charting the Graphical Roadmap to Smarter AI

Boosting LLMs with External Knowledge: The Case for Knowledge Graphs
When we wrote our post on Graph Intelligence in early 2022, our goal was to highlight techniques for deriving insights about relationships and connections from structured data using graph analytics and machine learning. We focused mainly on business intelligence and machine learning applications, showcasing how technology companies were applying graph neural networks (GNNs) in areas like recommendations and fraud detection.
However, GNNs remain complex and scarce in real world applications. There remains a disconnect between the large number of research papers published about GNN and the number of real-world production deployments. Bridging the gap requires reducing friction for practitioners - streamlining implementation, ensuring robust performance, and clearly demonstrating business value. Widespread production deployment of GNNs awaits solutions encapsulating their power into scalable, extensible enterprise offerings with compelling returns.
In the meantime, the rise of large language models now opens new possibilities for graphs – not for analytics or for GNN, but to improve language AI itself. Large language models (LLMs) have become remarkably proficient at generating human-like text. But they lack real-world factual knowledge, which limits their reasoning abilities and usefulness for many real-world applications. This is where knowledge graphs come in.
Knowledge graphs (KGs) are structured repositories of factual knowledge about the world, represented as interconnected concepts and entities. KGs efficiently capture the complex contextual relationships between real-world facts and concepts. For example, a KG could contain facts like "Paris is the capital of France" and "Satya Nadella is CEO of Microsoft." This graph structure makes KGs versatile tools for generating more accurate and informative search results, creating more engaging and informative chatbots, and developing new and innovative applications, such as supply chain and logistics management.
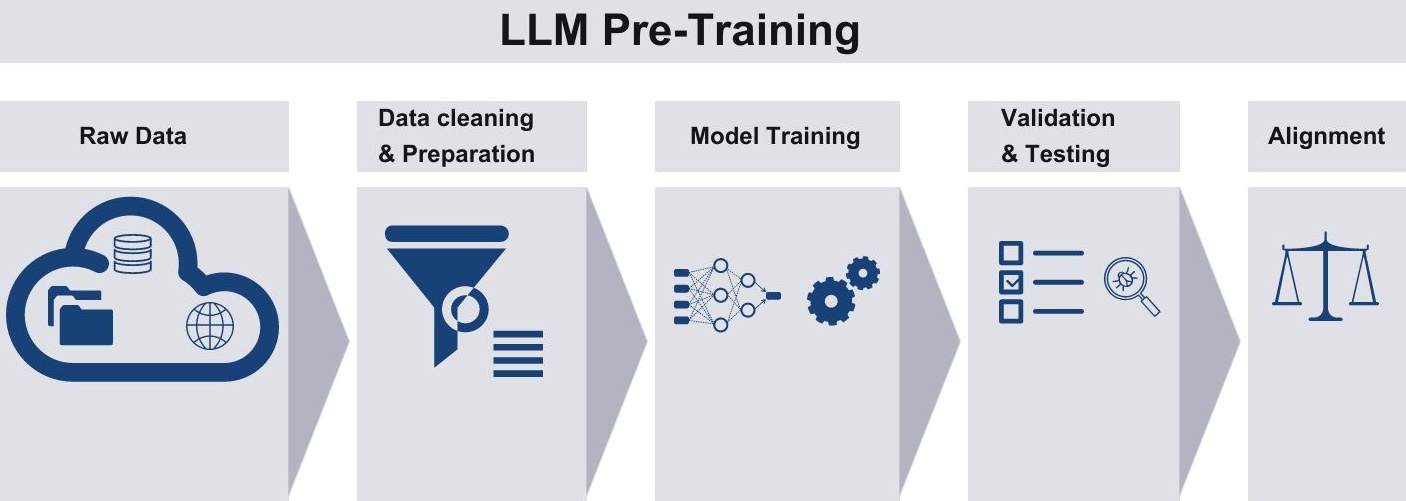
In contrast, LLMs are trained on vast amounts of text data to learn general linguistic skills. However, they lack factual knowledge about the world. Enhancing pre-training with knowledge graphs (KGs) can provide LLMs with structured, explicit representations of factual knowledge about concepts, entities and their relationships.
Pre-training LLMs with Knowledge Graphs
Pre-training is key to creating capable large language models like GPT-4 and Llama. This stage exposes models to massive text corpora to learn linguistic patterns. However, it typically lacks real-world factual knowledge.
Researchers recently described how to augment pre-training of LLMs with structured knowledge graph data. This instills grounded representations of factual concepts and relationships into the models. Specific techniques to inject knowledge graphs include:
Integrate into Training Objectives. New knowledge-aware training objectives can help language models learn more entities and relationships during pre-training. This can be done by masking knowledge graph entities more frequently based on connectivity, balancing losses between text and entities, and predicting alignments between text and graphs. The goal is to incorporate structured knowledge into the models and improve their ability to leverage real-world facts and relationships.
Integrate into Model Inputs. Knowledge injection techniques directly embed relevant knowledge graph information into language model inputs. For example, concatenating knowledge triples with text, allowing only entities to access knowledge, and connecting textual tokens to knowledge entities in a unified graph. These techniques aim to combine knowledge and text representations, so models learn to leverage both sources of information.
Add Fusion Modules. Knowledge graphs can be fused with language models by introducing additional encoders or layers to separately process and filter the knowledge graph, before fusing the knowledge representations with the textual encodings from the language model. This modular approach allows customizing how knowledge is selected, encoded, and integrated, while keeping the base language model parameters frozen.
Augmented pre-training produces models proficient in both language generation and factual knowledge - a powerful combination for knowledgeable AI. The overall goal is to ground language models in structured factual knowledge, improving their contextual understanding and reasoning abilities. Different techniques strike different balances between knowledge infusion and model complexity.
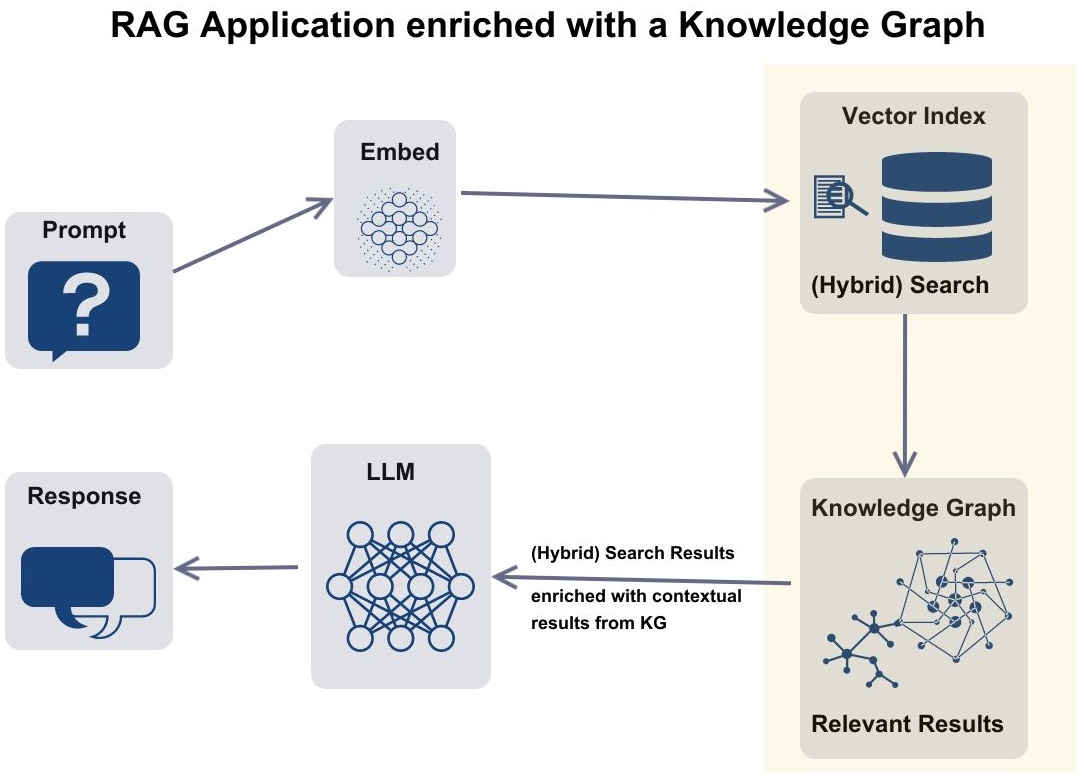
Retrieval Augmented Generation and Knowledge Graphs
Retrieval-augmented generation (RAG) enhances large language models by integrating external data to improve accuracy and relevance. Basic RAG applications retrieve supplementary text to contextualize the model. Metadata, such as timestamp, geolocation, reference, and product ID, can help refine and target information generated from text. The presence of metadata in the source data can enhance RAG by providing the model with additional context about the content, which can help the model to generate more relevant and informative responses.
Knowledge graphs significantly enhance RAG models by providing more context and structure than metadata alone. KGs allow you to blend vector-based and graph-based semantic search, which can lead to more accurate and informative results.
In RAG systems leveraging knowledge graphs, the user's prompt first goes through an embedding model to create a vector representation capturing its semantic meaning. This vector is then used to identify the most relevant nodes in the knowledge graph.
The top semantically similar nodes are retrieved along with their local context in the form of raw documents or passages. Additionally, the broader knowledge graph structure is traversed to gather potentially relevant related entities and relationships within a few hops of the retrieved nodes.
All of this pertinent external information - the identified relevant nodes, their local document contexts, and surrounding knowledge graph connections - is distilled and combined with the original user question into a prompt.
In summary, the user's question is transformed into a vector, this vector retrieves relevant graph nodes, surrounding graph context is gathered, and all of this external knowledge augments the generator to enable informed, contextual responses.
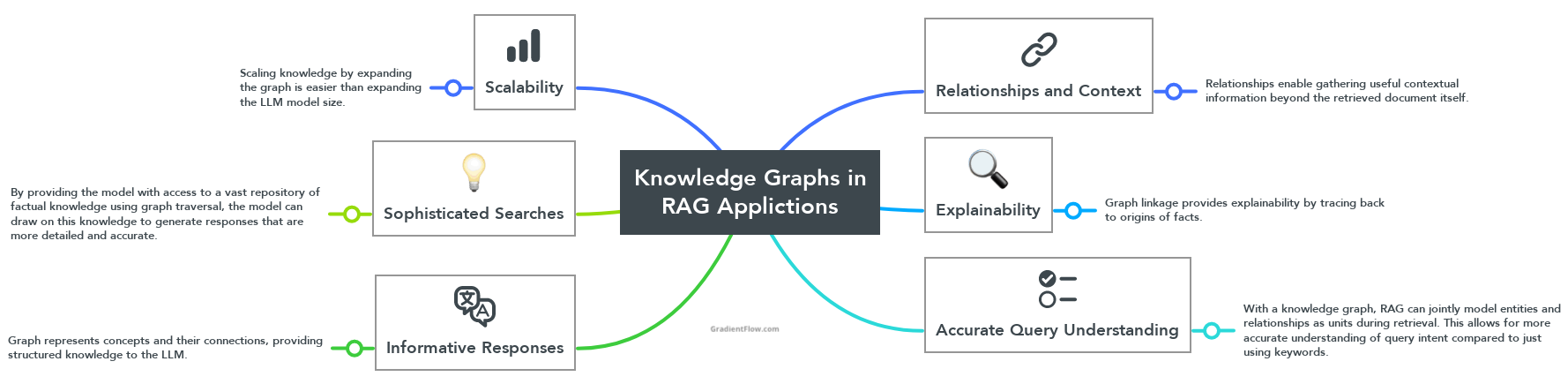
Some key benefits of augmenting RAG with knowledge graphs include the ability to gather useful contextual information beyond isolated facts through relationships, the capacity to perform more sophisticated semantic searches compared to just vector matches, the provision of explicit structured knowledge representation to improve accuracy, efficient knowledge scaling by expanding the graph versus the model, and inherent explainability by tracing facts back to their origins in the graph.
Turning Enterprise Data into Knowledge Graphs
Many enterprises likely already possess much of the data needed to start enhancing their LLM applications with knowledge graphs. As we noted in our post on Graph Intelligence, there are tools that can automatically turn semi-structured data like tables, logs, and documents into knowledge graphs.
In a recent discussion I had with Emil Eifrem of Neo4j, he pointed out that the majority of data that companies utilize for their LLM RAG applications possesses sufficient inherent structure to facilitate the creation of a knowledge graph. Common semi-structured data sources include customer support transcripts, reports, emails, and other conversational data sources. The metadata often present in such enterprise data enables identifying entities and relationships to build a basic knowledge graph. Even incomplete knowledge graphs can still augment language models with useful context. And graph structure makes it easy to continuously expand knowledge over time.
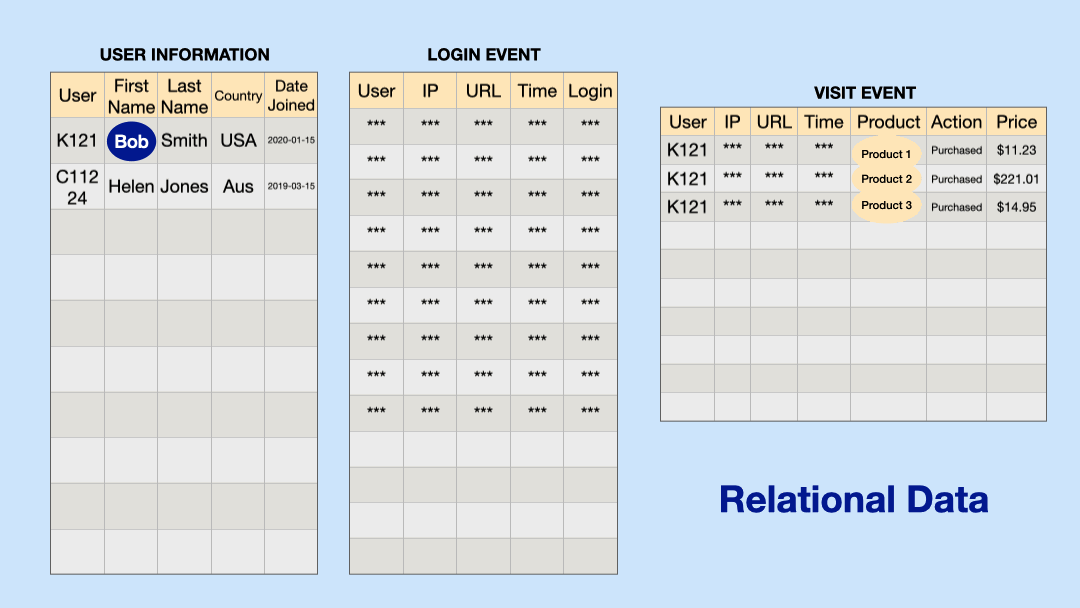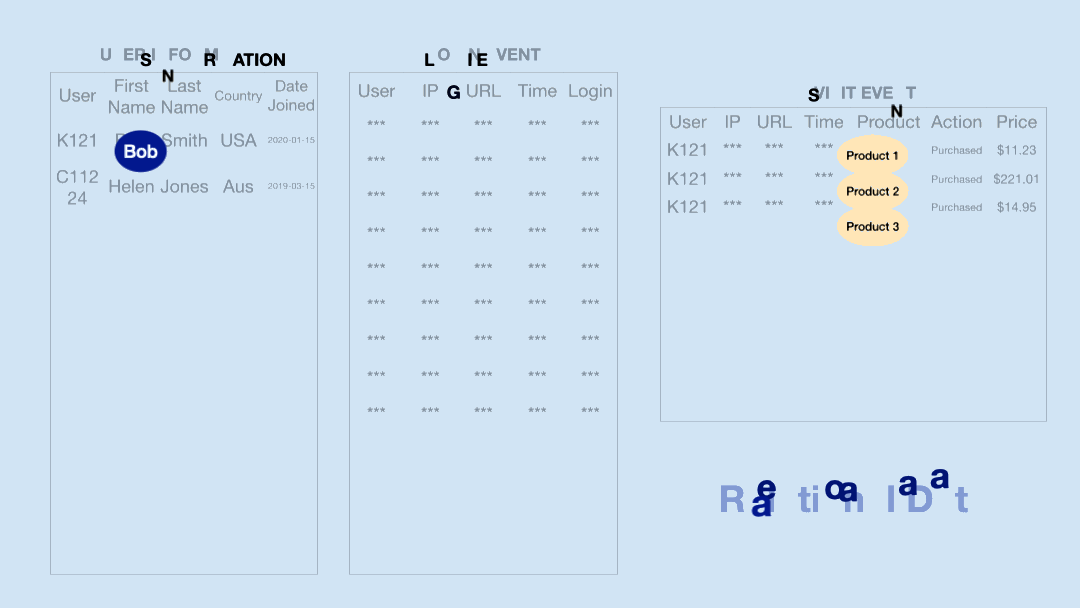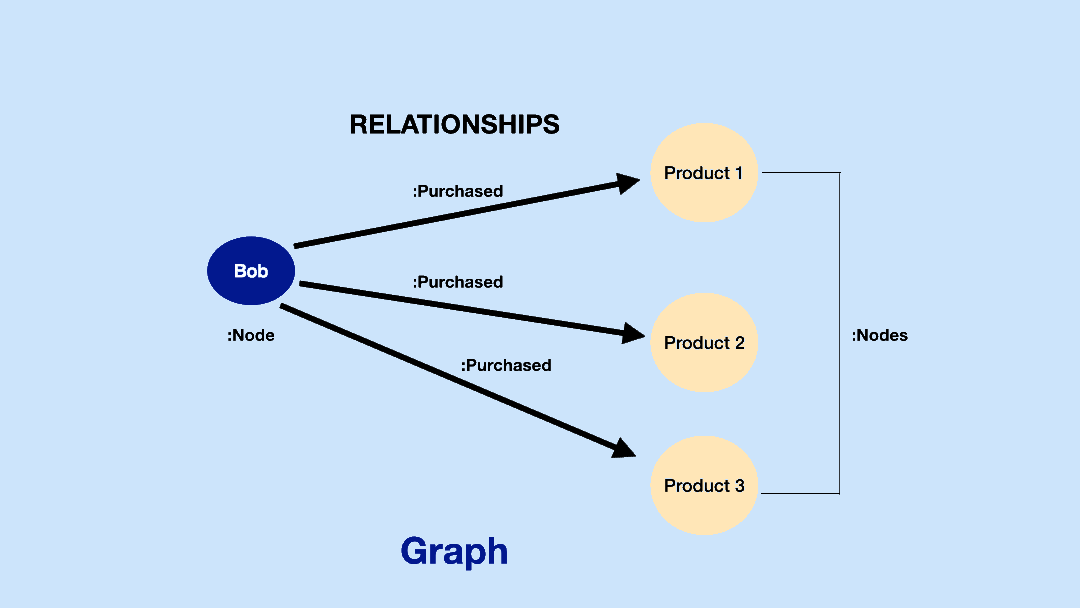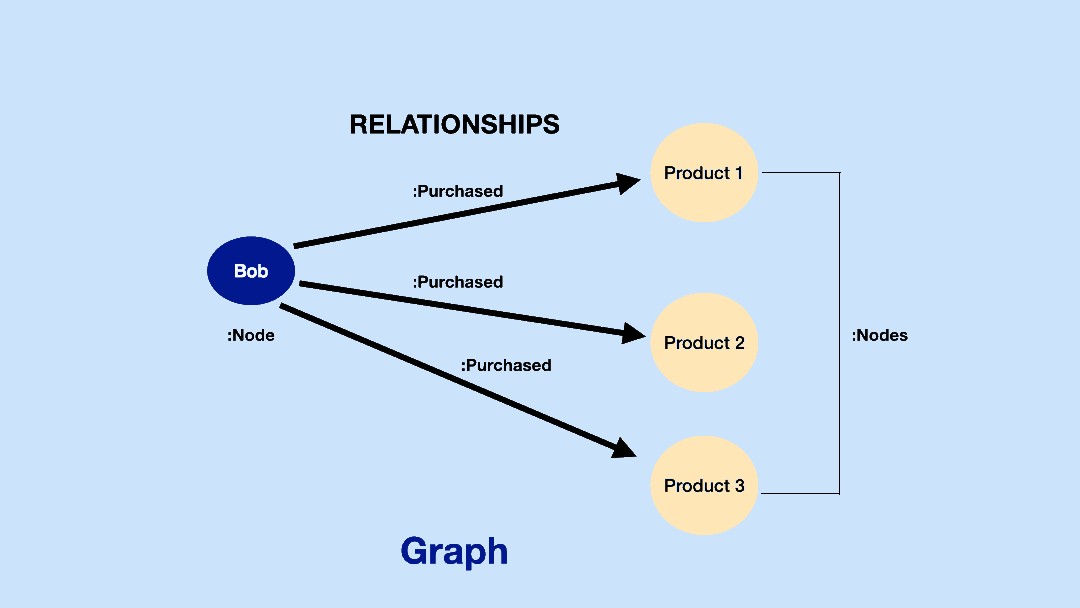
Unstructured data, however, poses more of a challenge. Nonetheless, the auto-generation of KGs from specific document sets has been a vibrant research area in AI for quite some time. LLMs themselves are now being applied to extract entities and relationships from text corpora for knowledge graph construction. Early experiments indicate LLMs can learn to extract new knowledge from instructions quickly, demonstrating strong generalization abilities.
Recent research introduced techniques using multiple LLMs collaboratively to automate building and utilizing knowledge graphs from unstructured data. So innovation continues swiftly in automating knowledge graph creation to handle diverse enterprise data sources.
You can start enhancing RAG systems with knowledge graphs today using the semi-structured data you already have. As automated knowledge extraction matures further, deriving graphs directly from unstructured content will enable tapping into broader LLM data. Knowledge graphs provide a powerful way to inject structure and context to make virtually any LLM application more intelligent.
The Future of AI is Graphical
The advent of LLMs expands the scope of Graph Intelligence to reach conversational data. For instance, knowledge graphs are a flexible method to provide LLMs with expanding structured knowledge, improving their accuracy, relevance, and explainability.
Most data enterprises use for LLM-based applications has enough structure to be converted into a knowledge graph. Rapid innovation in using LLMs for automated graph construction will also unlock unstructured data. Even incomplete graphs can provide useful contextual augmentation.
LLM queries are becoming easier with companies like Neo4j prioritizing usability. Its Cypher graph query language works similarly to SQL while optimizing graph traversals. With accessible data conversion, storage, and query tools, it's straightforward to start boosting enterprise LLM and AI applications with knowledge graphs today.
By enhancing pre-training and inference with interconnected, flexible knowledge, graph-empowered LLMs can reach new levels of practical utility. Pairing their language proficiency with structured factual knowledge empowers AI applications to understand the broader context.
Knowledge graphs can enrich RAG applications by connecting concepts and revealing insights. I don't want to oversell - this technology is still developing. But it's worth starting small - explore your data, add metadata, map key entities and relationships. Encode what high-value knowledge you can. Experiment to see how even simple graphs augment your models. Build incrementally as the technology evolves. Start mapping out knowledge today to take your RAG application to the next level. The future possibilities are exciting as knowledge graphs converge with large language models.

Data Exchange Podcast
Navigating the Nuances of Retrieval Augmented Generation. I discuss the intricacies of configuring RAG apps with Philipp Moritz and Goku Mohandas of Anyscale.
Kùzu: A simple, extremely fast, and embeddable graph database. Semih Salihoglu is an Associate Professor at University of Waterloo, and co-creator of Kuzu, the “DuckDB for Graphs”.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, Artifact, and Post. This newsletter is produced by Gradient Flow.
Great article 👏