

Best Practices in Retrieval Augmented Generation

Techniques, Challenges, and Future of Augmented Language Models
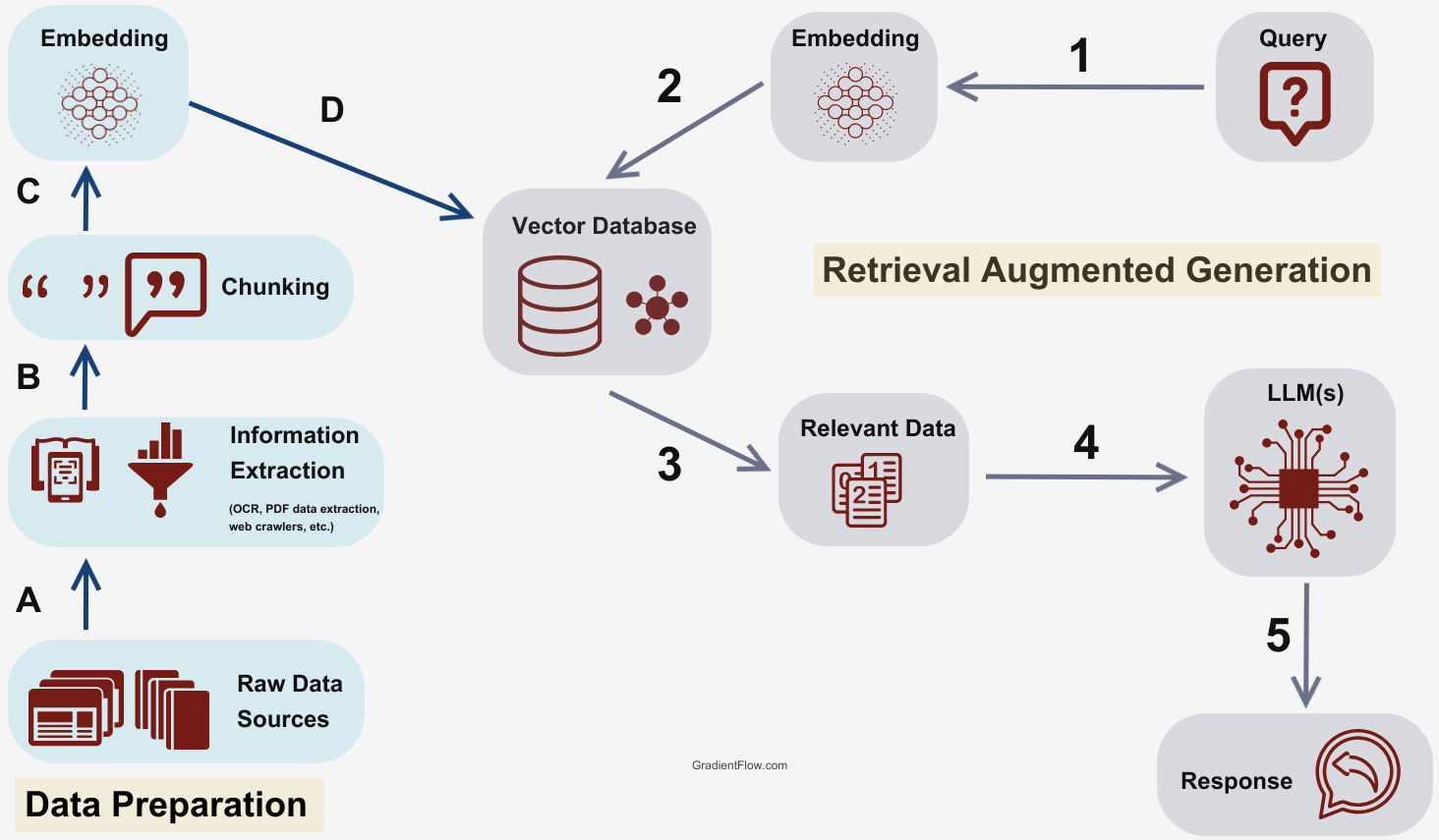
After attending several conferences in the past month, it's evident that Retrieval Augmented Generation (RAG) has emerged as one of the most popular techniques in AI over the past year, widely adopted by many AI teams. RAG refers to the process of supplementing a large language model (LLM) with additional information retrieved from elsewhere to improve the model's responses.
The rise of RAG can be attributed to its ability to produce more accurate and factual outputs by grounding language models in external knowledge sources. By seamlessly integrating retrieval with generation, RAG models can pull relevant information from large databases to include in generated text. This prevents hallucinated or incorrect information in model outputs. Many AI teams now prioritize RAG, and a plethora of tools, such as vector databases, LLM endpoints, and LLM orchestration tools, are emerging to simplify its implementation
While the potential of RAG is clear, best practices are still developing. Deploying an effective RAG system requires extensive experimentation to optimize each component, including data collections, model embeddings, chunking strategies, and more. There is no one-size-fits-all blueprint yet. Deploying a principled RAG design mandates comprehensive experimentation, often involving iterations over data collections, model embeddings, chunking strategies, and more. Through this post, drawing from recent blog posts, conference presentations, and conversations, I aim to share a collection of best practices backed by the experiences of teams that have systematically delved into RAG.
Evaluation
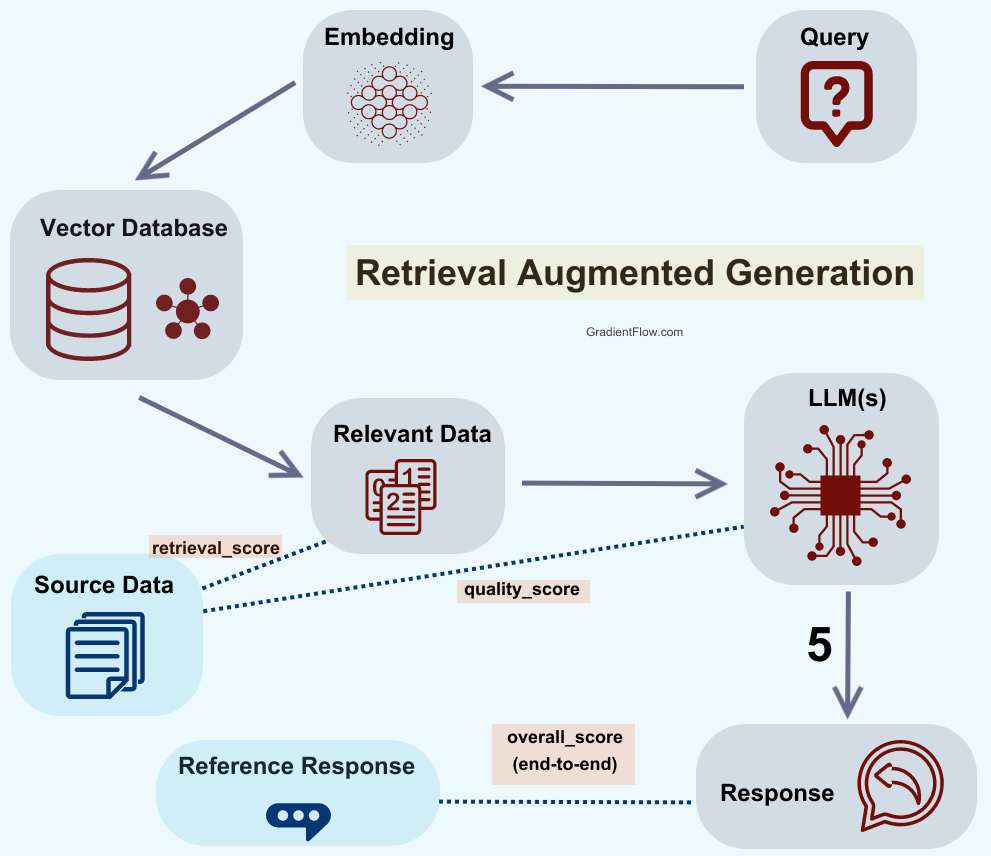
A two-step approach proposed by Anyscale provides a blueprint for thorough RAG evaluation. The first part of this approach emphasizes component-wise or unit evaluation. This is an in-depth analysis of the individual components of the RAG system. For instance, the retrieval system is evaluated in isolation to determine its efficiency in sourcing the best content chunks. Additionally, the response of the LLM is scrutinized to check if, given the best source, it can yield a quality response. Following component-wise assessments, Anyscale suggests transitioning to end-to-end evaluations. This holistic evaluation method probes the overall system quality, factoring in the data sources at hand.
The choice of metrics plays a pivotal role in this evaluation approach. Metrics such as Retrieval_Score and Quality_Score stand out prominently. The former gauges the quality of retrieved context by analyzing the distance between the query embedding and knowledge base's embedded chunks. In contrast, the latter offers a comprehensive measure of a response's overall quality, taking into account its relevance, coherence, and accuracy.
To implement the evaluation steps described above, you will need to invest in creating a reference dataset for evaluation. The key components needed are:
A collection of questions on various topics representative of real-world queries.
For each question, identify one or more relevant documents or passages that contain the information needed to answer the question. These will serve as the ground truth answering sources.
Pass each question and its answering source(s) through your RAG system to generate a response. The system should retrieve the provided source(s) and incorporate the information into its answer.
Have human evaluators score each system-generated response for qualities like relevance, accuracy, and factual grounding against the source context. Scoring should be guided by detailed criteria.
Data
Not unlike supervised learning, the performance of retrieval-augmented generation (RAG) systems is highly dependent on the quality of the data they are trained on. RAG systems work by retrieving relevant information from a knowledge corpus and then using that information to generate a response. If the data in the knowledge corpus is of poor quality, RAG will be unable to generate accurate or informative results.
There are a few key factors that contribute to the impact of data for RAG systems:
Data quality: If the data is inaccurate, incomplete, or biased, the RAG system will be more likely to generate inaccurate or misleading responses.
Data preparation: This includes cleaning the data, removing duplicate entries, and converting the data into a format that is compatible with the RAG system.
Data sources: If the knowledge corpus only contains data from a limited number of sources, the RAG system may not be able to generate responses that are as comprehensive or informative as if it had access to a wider range of data sources.
Metadata: By providing metadata about the chunks passed in the context, the LLM will be able to understand the context better, potentially leading to better output.
Additional Context and Knowledge: If available, knowledge graphs enhance RAG applications by providing additional context at query time, which enables the system to generate more accurate and informative responses.

Chunking
In RAG, "chunking" pertains to the segmentation of input text into concise, meaningful units, facilitating the retrieval system in pinpointing relevant contextual passages for response generation. The quality and structure of these chunks are pivotal to the system's efficacy, ensuring that retrieved texts are narrowly tailored to a user's inquiry.
Anyscale's investigation underscores the prominence of chunking over embedding optimization. Their recommendation for developers prioritizes experimentation with various chunking strategies. When executed properly and considering aspects like the structure of your documents, chunking can significantly enhance RAG performance.
Anyscale's experiments delineated several chunking methods. Key findings from their trials include:
Chunking significantly influences the quality of the generated content.
They tested various sizes, including 100, 300, 500, and 700. The findings suggested that larger chunk sizes can be beneficial, but the benefits taper off after a certain point, indicating that too much context might introduce noise. It's also noteworthy that many open-source embedding models cap at 512 sub-word tokens.
While larger chunk sizes can enhance performance, an excess of context might introduce noise.
Varying the number of chunks can bolster retrieval and quality scores, but the benefits diminish after a threshold. Due to the LLM's context length limitations, experiments maxed out at seven chunks.
Strategies worth noting encompass utilizing smaller chunks and retrieving adjacent chunk content or maintaining multiple embeddings for a document.
What about overlaps? The Anyscale post does not directly address this topic (although they do use a chunk_overlap variable in their experiments). Overlap in chunking refers to the intentional duplication of tokens at the boundaries of adjacent chunks. This ensures that when a chunk is passed to the LLM for generation, it contains some context from its neighboring chunks, enhancing the quality of the output. For instance, if data is divided into chunks of 100 tokens, overlapping by 50 tokens would mean that the last 50 tokens of one chunk are the same as the first 50 tokens of the next chunk, thus preserving surrounding context.
Embedding Models
An "embedding model" refers to a pre-trained model responsible for representing data in a numerical form, facilitating semantic search for information retrieval. Many teams conduct experiments using various popular embedding models. Depending on the size of your corpus, these can be computationally expensive and best produced using a distributed computing framework like Ray.
Anyscale’s experiments revealed that the choice of the embedding model significantly impacts retrieval and quality scores, with the smaller models outperforming even top-ranked models for specific tasks. It turns out that simply selecting the top-performing embedding model from a leaderboard isn't always the best decision!
Both the embedding model and chunking strategy can significantly impact the performance of RAG systems. However, the chunking strategy appears to have a slightly greater impact. The value of embeddings depends largely on your use case. Off-the-shelf embedding models can generate embeddings for data chunks that work well for most use cases. However, if you are working on a specific domain, these models may not adequately represent the domain in the vector space, resulting in poor retrieval quality. In such cases, you can fine-tune and use an embedding model on the domain data to improve retrieval quality.
Data Management and Information Retrieval
Vector search is no longer limited to vector databases. Many data management systems - including Postgres - now support vector search. Depending on your specific application, you might be able to find a system that meets your specific needs. Is near real-time or streaming a priority? Check Rockset’s offering. Are you already using a knowledge graph? Neo4j’s support for vector search means your RAG results will be easier to explain and visualize.
In RAG applications, efficient and precise retrieval algorithms play an indispensable role. RAG integrates retrieved context from vast data sources to generate answers. There are two primary retrieval methods: Term-based matching, like BM25, which identifies keywords from questions and matches them to relevant documents based on term statistics; and Vector similarity search that rely on embeddings. These embeddings are then indexed, allowing for rapid similarity lookups. While term matching is simpler and needs less preprocessing, vector similarity provides a deeper contextual relevance.
Many vector databases allow you to use hybrid (term-based and vector search) retrieval methods. Given the constraints of language models and the crucial role of domain expertise in ranking results, tailoring your retrieval method to specific needs becomes vital. For optimal outcomes with RAG, you will have to run experiments with your own data and determine the most suited retrieval strategy.

LLM
An LLM generated refined answers by harnessing information from relevant document snippets. The LLM is augmented by external data, enhancing its response quality. The right LLM depends on the application's objectives, so choosing the right one is crucial. While some situations only require succinct summaries, others demand advanced reasoning, underscoring the LLM's relevance. Modern LLMs are not just about data memorization; their prowess lies in reasoning, much like consulting an expert. They can critically evaluate and reason over acquired knowledge, making larger models more coveted.
For those developing RAG applications, experimenting with various LLMs is essential. Your choice should align with your application's unique demands, considering factors like accuracy, latency, and cost. Early design patterns have emerged to optimize this:
Mixture of Experts: Employing hybrid routing involves utilizing multiple LLMs. A supervisor model guides the input query to the most apt LLM. Diverse applications can benefit by amalgamating outputs from several LLMs.
Intent Classifiers: Combining RAG with Intent Classifiers, offers an optimized approach between a naive RAG application and a cumbersome conversational agent. Intent Classifiers discern when a user query matches predefined canonical forms, enabling faster and precise responses
Tune Away
Retrieval Augmented Generation is a promising new technique that is transforming the way we generate AI-powered text. By grounding language models in external knowledge sources, RAG can produce more accurate and reliable outputs. I encourage AI teams and practitioners to experiment with different RAG parameters to find the optimal setup for their specific needs.
RAG is here to stay, and systematic exploration will be the key to its success. On a speculative note, hyperparameter optimization tools like Ray Tune could enable the systematic refinement of RAG systems. Ray’s distributed computing framework is essential for parallelizing computationally intensive, combinatorial experiments (grid search), enabling exploration of many more configurations.
Listen to the Data Exchange podcast next Thursday to hear RAG experts Philipp Moritz and Goku Mohandas of Anyscale discuss the results of their recent experiments building RAG applications.

Data Exchange Podcast
Versioning and MLOps for Generative AI. If we can scale DevOps to accommodate repositories of all sizes and optimize our Continuous Integration systems for tasks such as GPU-based training, Yucheng Low from XetHub suggests we could streamline our toolset.
Generative AI-Powered Social Media Manipulation. Bill Marcellino and Nathan Beauchamp-Mustafaga of the RAND Corporation are the principal researchers behind a new report on the potential threats of Generative AI in social media manipulation. The RAND report emphasizes the need for a proactive, broad strategy to counter these threats, which includes exploring technical solutions, regulating social media platforms, verifying user identities, and engaging in international dialogues.
If you enjoyed this newsletter please support our work by encouraging your friends and colleagues to subscribe:
Ben Lorica edits the Gradient Flow newsletter. He helps organize the AI Conference, Ray Summit, and the Data+AI Summit. He is the host of the Data Exchange podcast. You can follow him on Linkedin, or Twitter, or Mastodon, or Pebble, and Post. This newsletter is produced by Gradient Flow.