

Before you scale your AI, read this

Beyond the Lab: Performance Engineering for Production AI Systems
The conversation around AI has shifted from whether to adopt the technology to how to make it economically viable at production scale. In previous articles, I’ve covered the strategic playbooks for AI adoption and evaluation frameworks that define success. However, a critical gap persists between successful pilots and sustainable production systems—a gap that costs organizations millions in wasted infrastructure and missed opportunities. The companies that will lead the next wave of innovation understand that AI performance engineering isn't about maximizing raw model capability, but about optimizing the entire system for business value. The following eight strategies represent hard-won lessons from teams that have moved beyond the lab to build AI systems that scale profitably.
1. Understand the Non-Linear Economics of AI Systems
Unlike traditional software where costs scale predictably with users, generative AI systems face exponential cost growth through hidden multipliers like context expansion, retry mechanisms, and cascading tool calls—similar to how distributed systems introduced new failure modes that monolithic architectures never encountered. A simple chatbot query that costs pennies in development can balloon to dollars in production when factoring in retrieval-augmented generation lookups, multi-turn conversation history, and safety filtering passes, creating budget surprises that derail AI initiatives.
Organizations that internalize this reality early avoid the common pattern of successful pilots that stall at production scale, maintaining momentum while competitors hit cost walls that force feature rollbacks. By building cost awareness into architectural decisions from day one, teams significantly reduce time-to-market compared to those who attempt late-stage optimization sprints. Task your lead engineer to trace a complex user query through your entire AI pipeline, documenting every API call, token multiplication point, and retry loop to reveal the true cost amplification factor—the results typically shock even experienced teams.
2. Implement Intelligent Model Routing for Cost Efficiency
Defaulting to your most powerful model for every request wastes resources on simple tasks that smaller models handle equally well, much like using a Formula One engine for neighborhood errands. A tiered routing system analyzes incoming requests and directs them to appropriately-sized models—lightweight 7B parameter models for FAQs and data extraction, mid-tier 13-30B models for moderate reasoning, and premium models only for complex creative or analytical tasks. This cascade architecture functions as a computational CDN, where the majority of requests never need expensive inference, dramatically improving both cost and latency profiles.
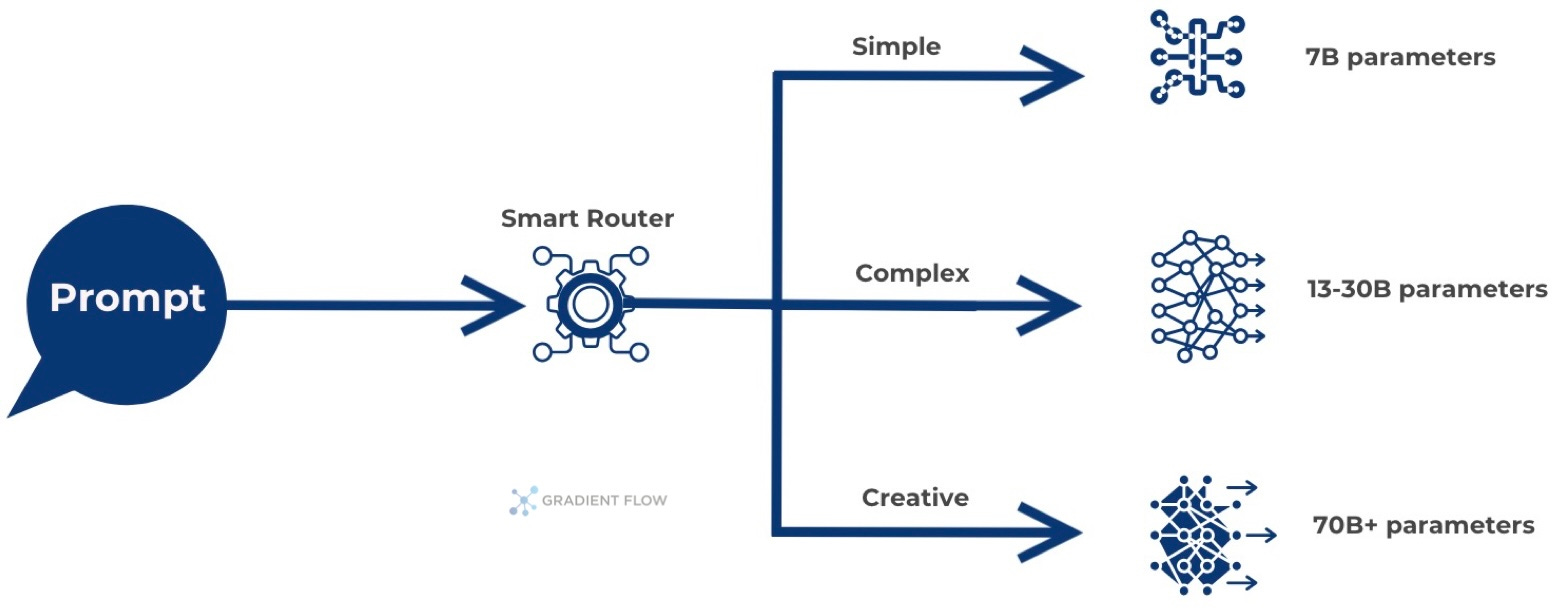
Teams implementing model cascades report substantial reductions in inference costs while actually improving average response times, as queue contention on expensive resources drops dramatically. This transforms previously uneconomical use cases into viable products, expanding the market for AI features while improving system reliability through better resource isolation. Analyze your last 1,000 API calls to categorize them by complexity, then pilot routing your highest-volume simple queries to an open-source 7B parameter model, measuring both cost savings and quality retention.
3. Optimize Memory Bandwidth, Not Just Compute
Modern AI systems hit memory bandwidth limits long before exhausting computational capacity, similar to how Netflix discovered content delivery performance mattered more than raw server processing power. The primary bottleneck for large language models isn't computation, but data movement. This memory-bound reality creates a fundamental challenge that traditional, compute-focused scaling solutions are ineffective against. This memory wall becomes particularly acute during inference when models must sequentially generate tokens, with each step requiring access to cached attention states that grow linearly with context length.
Teams that recognize this architectural reality avoid costly over-provisioning of GPUs while achieving significantly better hardware utilization through memory-aware optimizations. This shift in perspective transforms capacity planning from guesswork to engineering, enabling accurate predictions of real-world performance limits. Instrument your highest-traffic AI endpoint to measure memory bandwidth utilization versus compute utilization during peak periods, then share these metrics with your infrastructure team to realign resource allocation strategies.
4. Deploy Modern Inference Stacks with Built-in Optimizations
Modern AI inference platforms deliver the same performance leap your organization experienced moving from basic web servers to enterprise application servers. These platforms come with built-in optimizations that dramatically boost your GPU efficiency—similar to how a load balancer prevents one slow request from choking your entire system. Instead of your team spending months building custom performance optimizations like continuous batching, paged attention, and efficient KV-caching, frameworks like the open-source vLLM project deliver substantially better throughput immediately.
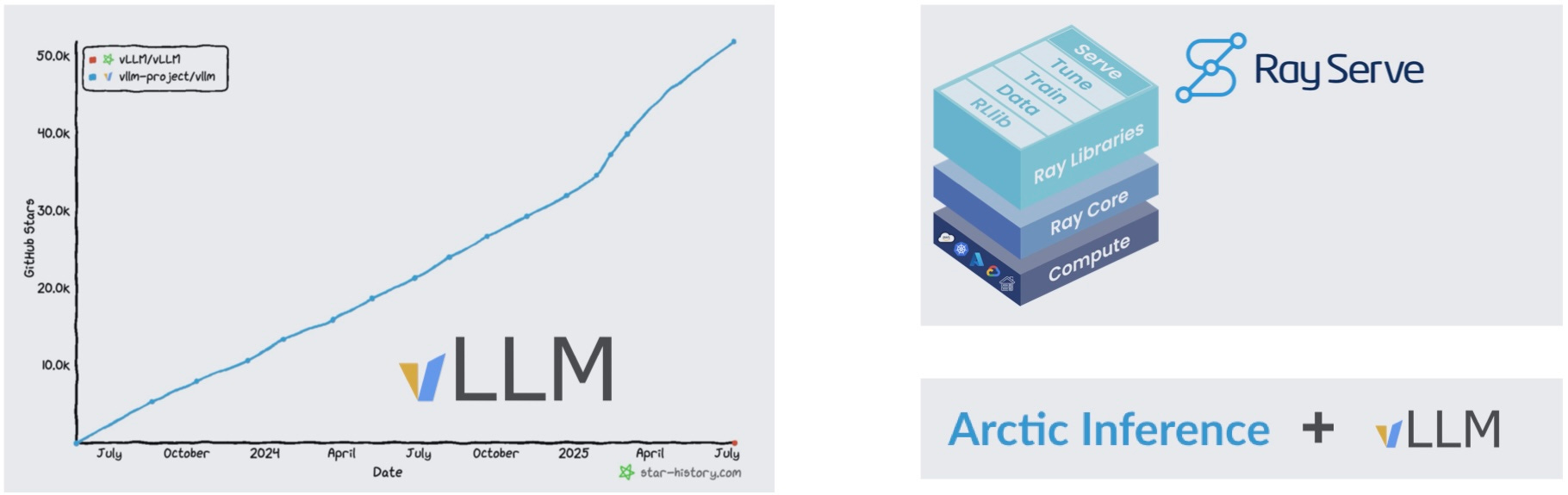
The business impact is immediate and measurable. Organizations adopting these platforms see response times improve significantly, infrastructure costs drop substantially, and engineering teams shift from fighting performance issues to building features that matter. This infrastructure foundation accelerates your AI experimentation cycle—a critical competitive advantage when AI capabilities are evolving rapidly. Direct your platform team to benchmark your current inference setup against a modern open-source serving framework, measuring tokens per second and latency—the results will provide clear justification for migration.
5. Compress Models Systematically Through Quantization
Quantization reduces model precision from 32-bit floating point to 8-bit integers or even 4-bit representations, achieving significant size reduction while maintaining most of the original accuracy—comparable to how video compression preserves visual quality while dramatically reducing bandwidth requirements. Smaller models mean larger batch sizes fit in the same GPU memory, directly translating to higher throughput and lower latency, while also reducing cold start times for serverless deployments. Combined with structured pruning that removes redundant parameters, these techniques turn memory constraints from barriers into optimization opportunities.
Teams implementing systematic compression strategies report substantial improvements in inference speed and reductions in infrastructure costs, making previously impossible applications suddenly feasible. The business impact extends beyond cost savings to enable new product categories like on-device AI and edge deployment, opening markets that cloud-only solutions cannot address. Apply INT8 quantization to your most resource-intensive model in a development environment, A/B testing the compressed version against the original to establish concrete metrics for accuracy versus efficiency trade-offs.
6. Establish Granular FinOps Discipline from Day One
When an AI feature's monthly bill unexpectedly triples, who is accountable? This isn't just a budget issue; it's a symptom of a new kind of architectural complexity. Much like the move to microservices obscured system behavior until distributed tracing made it visible, AI's cascading costs remain hidden from standard monitoring. A robust FinOps practice acts as that essential tracing layer for expenses, preventing the frustrating cycle of blame by making costs transparent and attributable from the start.
Companies with AI FinOps practices report significant reductions in operational expenses while actually increasing feature velocity, as teams make informed trade-offs between cost and capability. This discipline prevents the budget crises that derail roadmaps and maintains trust between engineering and finance organizations. Mandate that every AI endpoint must deploy with cost allocation tags identifying the model used, feature served, and responsible team, then configure automated alerts at 50% and 80% of current monthly spend thresholds.
7. Build AI-Native Observability Before Problems Surface
Traditional infrastructure monitoring misses critical AI performance indicators like time-to-first-token, inter-token latency, and KV-cache efficiency, leaving teams blind to degradations that directly impact user experience—similar to how early web applications measured uptime but not page load speed. These AI-specific metrics provide early warning systems for performance issues, enabling proactive optimization rather than reactive firefighting when users complain about slow responses. Modern AI observability also tracks prompt injection attempts, hallucination rates, and context overflow events that traditional APM tools cannot detect.

With specialized AI monitoring, organizations fix issues faster, ensuring the consistent performance that keeps users engaged. This data-driven observability also replaces guesswork with precision in capacity planning and cost optimization. Implement time-to-first-token monitoring on your primary user-facing endpoint this week, establishing baseline p50/p90/p99 measurements and configuring alerts at 2x your normal baseline to catch degradations before users notice.
8. Prepare for the Inference-Time Compute Revolution
The next wave of AI breakthroughs will come from inference-time scaling—using more computation during generation to improve output quality—rather than simply training larger models, paralleling how search engines evolved through better ranking algorithms rather than bigger indexes. Techniques like speculative decoding (using small models to draft tokens for large models to verify in batches) and test-time fine-tuning represent early examples of this paradigm shift, offering substantial quality improvements for complex reasoning tasks. Organizations that architect for flexible inference-time computation today will leverage these advances without infrastructure rewrites tomorrow.
Early adopters of inference-scaling techniques report notable improvements in output quality for complex reasoning tasks while maintaining production latency requirements. Enable speculative decoding in your serving framework—often just a configuration flag—and measure the impact on time-to-first-token for interactive workloads to understand the immediate benefits while building experience with next-generation techniques
Ray Summit 2025
These performance engineering principles will be front and center at Ray Summit 2025, taking place November 3-5 in San Francisco. This year's summit features a dedicated vLLM track focused on building the kind of high-throughput, low-latency inference services that separate successful AI products from expensive experiments. The sessions will offer a deep dive into the practical implementation of many concepts outlined here, from intelligent model routing to memory-aware optimization. For teams serious about scaling AI systems economically, Ray Summit is a rare opportunity to learn directly from practitioners who are solving these challenges in production.

Ben Lorica edits the Gradient Flow newsletter and hosts the Data Exchange podcast. He helps organize the AI Conference, the AI Agent Conference, the Applied AI Summit, while also serving as the Strategic Content Chair for AI at the Linux Foundation. You can follow him on Linkedin, X, Mastodon, Reddit, Bluesky, YouTube, or TikTok. This newsletter is produced by Gradient Flow.